

Passenger attribute recognition method for railway passenger stations based on AL-Transformer model
-
摘要: 随着铁路运力的不断提升,旅客在铁路客运站内候车的频次和时间也在不断增加,为主动挖掘候车旅客的个性化需求,提出一种基于AL-Transformer(Attribute Localization—Transformer)模型的铁路客运站旅客属性识别方法。AL-Transformer模型基于Swin Transformer主干网络提取进站旅客的结构化信息,通过掩码对比学习(MCL ,Mask Contrast Learning)框架抑制特征区域相关性,获取到更有辨识度的属性区域;通过属性空间记忆(ASM ,Attribute Spatial Memory)模块选取更加可靠、稳定的属性相关区域。在中国铁路兰州局集团有限公司白银南站试用的效果表明,该方法可有效识别旅客属性,为客运站工作人员推送更有针对性的信息,提升客运站的旅客服务质量,保障旅客候车安全。
-
关键词:
- 属性识别 /
- AL-Transformer模型 /
- 掩码对比学习(MCL) /
- 属性空间记忆(ASM) /
- 旅客异常行为
Abstract: With the continuous improvement of railway transportation capacity, the frequency and time of passengers waiting for trains in railway passenger stations are also increasing. To actively explore the personalized needs of waiting passengers, this paper proposed a passenger attribute recognition method for railway passenger station based on the AL-Transformer (Attribute Localization Transformer) model. The paper used AL-Transformer model based on the Swin Transformer backbone network to extract structured information of passengers entering the stations, suppressed feature region correlation through the Mask Contrast Learning (MCL) framework to obtain more recognizable attribute regions, and used Attribute Spatial Memory (ASM) module to selecte more reliable and stable attribute related regions. The trial results at Baiyin South Station of CHINA RAILWAY Lanzhou Group show that this method can effectively identify passenger attributes, push more targeted information for station staff, improve the quality of passenger service at the station, and ensure the safety of passenger waiting. -
随着我国铁路建设的快速发展和高速铁路(简称:高铁)线网的不断完善,高铁已逐渐成为人们的首选出行方式。为保障旅客的候车安全,提升旅客出行体验,铁路客运站内普遍通过工作人员实时观察旅客候车情况,尽可能地提高旅客候车舒适度。然而,铁路客运站面临着日益增长的客流量和复杂的站场形式,人工观察的方式大多是事后的补救措施,无法主动提升候车服务质量。
因此,有必要在旅客进入候车室时就自动识别到其属性信息(年龄范围、性别、帽子、眼镜、衣着、乘坐轮椅、携带物等),从而为其主动提供精准服务;增加异常行为报警的详细描述信息,辅助工作人员快速、准确锁定异常行为人员等,从而更好地保障旅客候车安全。
行人属性识别技术是为摄像头捕捉的行人图片监测其属性类别的技术[1]。早期的行人属性识别技术通常依赖人工进行属性提取,并为每个属性设计单独的分类器[2-4]。然而,客运站的复杂环境会显著降低该技术的性能。随着深度学习技术的发展,众多学者尝试使用复杂网络来解决该问题[5-8],例如,利用特征金字塔网络(FPN ,Feature Pyramid Network)从多层次特征图中提取属性,结合注意力机制提取属性类别。随着Transformer模型在计算机视觉领域的广泛应用,学者们发现其可捕获长距离依赖关系,更适合于行人属性的提取。该模型主要通过属性相关性来完成任务,然而过渡的依赖关系有时反而会降低属性定位的准确性。
综上,本文提出一种基于AL-Transformer(Attribute Localization—Transformer)模型的铁路客运站旅客属性识别方法。该方法基于掩码对比学习(MCL ,Mask Contrast Learning)框架抑制特征区域相关性;通过属性空间记忆(ASM ,Attribute Spatial Memory)模块获得更有辨识度、更可靠稳定的属性区域。为铁路客运站工作人员推送更有针对性的预警信息,提高旅客服务质量。
1 AL-Transformer模型
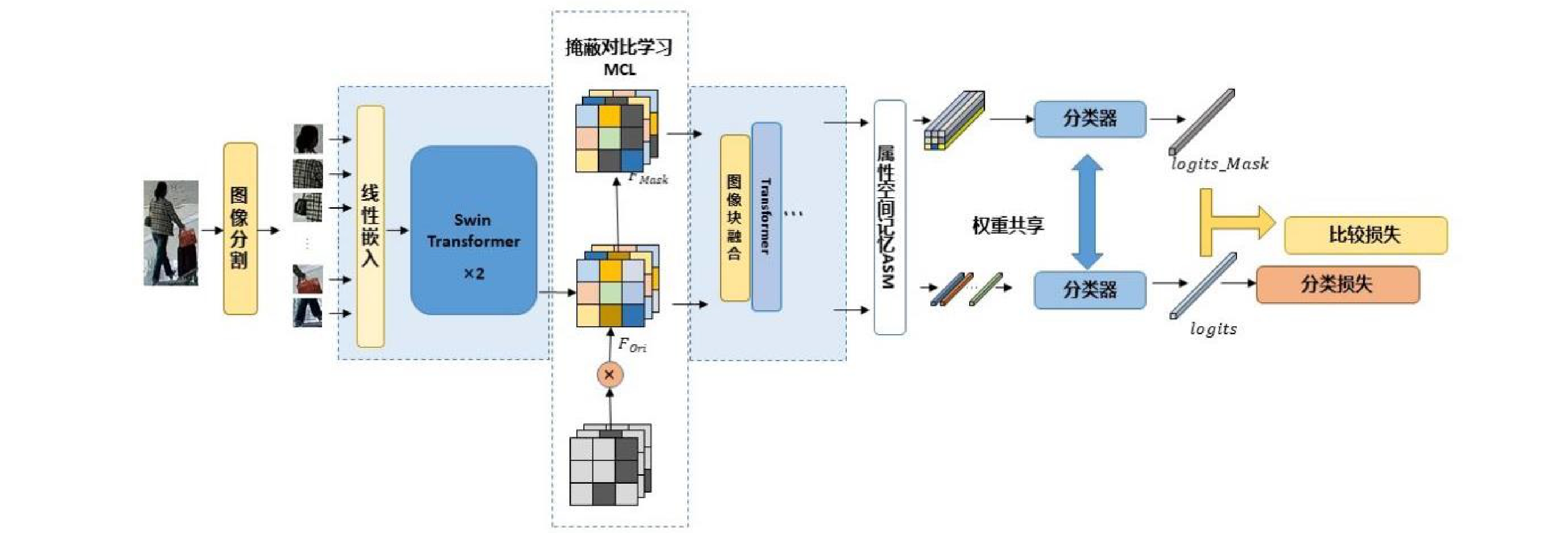
AL-Transformer模型以Swin Transformer为骨干网络[9],其总体架构如图1所示。AL-Transformer模型将给定的图像分割成不重叠的图像块;随后对每个图像块进行线性嵌入,并通过Swin Transformer骨干提取图像特征。AL-Transformer模型引入MCL框架,生成随机掩码特征图
FMask 和 原始特征图FOri ,FMask 和FOri 通过Transformer模型和ASM模块,分别生成预测logits 和logits_Mask 。AL-Transformer模型计算logits_Mask 和logits 间的比较损失并进行回归预测,改进属性定位能力。1.1 MCL框架
AL-Transformer模型在骨干网络的基础上,加入MCL框架,降低模型中的区域相关性对于性能预测的影响。为使AL-Transformer模型更关注于精确的属性空间区域,MCL框架在网络中间层完成特征掩码,通过控制特征区域间的相关性提升预测精度。
MCL框架为每一批输入图像生成相应数量的随机
FMask ,随后在分类器阶段设置对比度损失函数Lcon ,以评估通过随机遮掩和没有随机遮掩的预测结果间的差异,损失函数Lcon 公式为Lcon=−predOri⋅log(predMask) (1) 式(1)中,
predMask 和predOri 分别为原始特征图FOri 和随机掩码特征图FMask 的预测结果。1.2 ASM模块
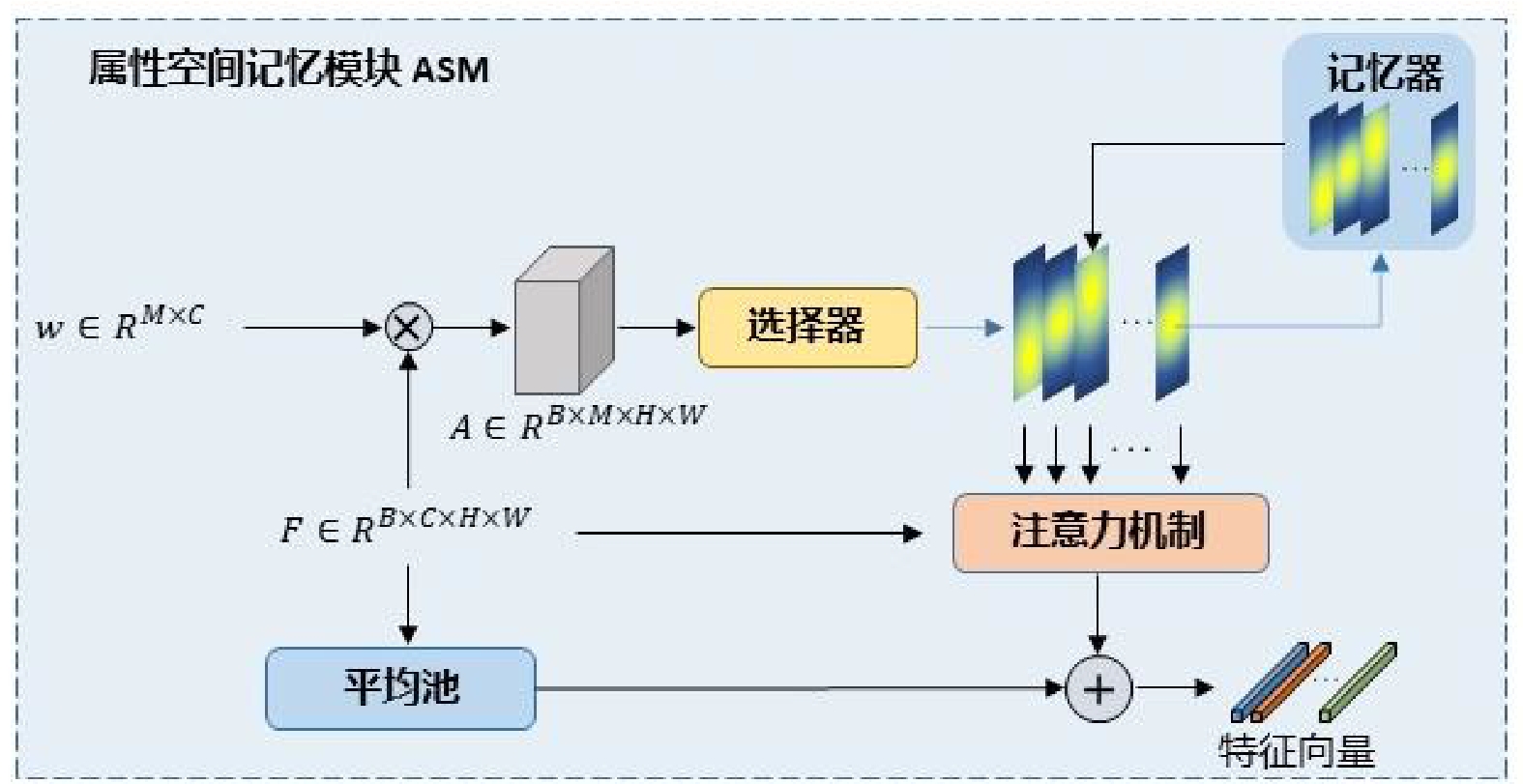
ASM模块用于解决空间注意力区域偏差问题,其架构如图2所示。
ASM模块利用输入特征生成注意力图,选择可靠的注意力图保存在记忆器模块中,再通过注意力机制和选择器为其生成相应的属性定位信息。
ASM模块将特征图
F∈RB×C×H×W 和分类器权重w∈RM×C 作为输入,其中,F∈RB×C×H×W 是主干网络的输出;H 、W 、C 表示特征图的高度、宽度和通道维度;B 为训练批次。M 是属性的总数;A∈RB×M×H×W 为输出的每个属性的注意力图,其公式为Ai,m = wm⋅Fi(x,y), m=0,1,2,⋯,M−1 (2) 式(2)中,
Fi 是主干框架的特征图;wm 是第m 个属性的分类器权重。注意力图
Ai,m 表示不同空间区域的属性预测值,ASM模块分别对不同属性生成相应的嵌入向量,对空间位置信息进行加权,从而改进每个属性的空间定位。再对注意力图进行归一化,用作空间加权系数,对特征进行加权池化。1.3 损失函数
AL-Transformer模型根据二元交叉熵损失计算分类损失
Lcls ,公式为Lcls=1NN∑i=1M∑j=1yi,jlog(pi,j)+(1−yi,j)log(1−pi,j) (3) 式(3)中,
pi, j 为分类器的预测概率;yi, j 为预测结果;N 为预测属性类别数。对比损失
Lcon 公式为LCon=−probOri⋅log(probMask) (4) 式(4)中,probOri和probMask分别代表原始特征的预测结果和掩码特征的预测结果。
最终损失函数Loss是分类损失
Lcls 和对比度损失Lcon 的加权总和。2 试验验证
2.1 性能比较
2.1.1 公共图像数据库介绍
本文试验采用PETA(PEdesTrian Attribute)公共图像数据库和PAl00K(Pedestrian Attribute—100K)公共图像数据库的公开图像数据。其中,PETA公共图像数据库包含19000张行人图片,图片的分辨率为17×39 ~ 169×365(PPI),同时,每张行人图片标注了61个二元属性和4个多类别属性,例如年龄、性别、服饰和配饰等[10],其图片示例如图3(a)所示;PAl00K公共图像数据库是目前为止最大的监控场景下行人属性识别数据库。该数据库拥有100000张行人图片,包括80000张训练集图片,10000张验证集和10000张测试集图片,每张行人图片被标注了26个属性[5] ,其图片示例如图3(b)所示。
2.1.2 实验设置
本文基于PyTorch框架实现铁路客运站旅客属性识别方法,并以端到端的方式进行训练,采用Swin Transformer作为骨干网络提取行人图像特征。本文将输入的行人图像尺寸统一调整为256×192像素,并采用随机水平镜像、填充和随机裁剪的方式进行图像增强。此外,本文采用Adamw训练策略,设置衰减权重为0.0005、初始学习率为0.0001、批处理大小为64、训练阶段的总迭代周期为50、动量系数为0.9998、标签平滑系数为0.2。
2.1.3 性能比较
本文采用平均准确率(mA)、准确率(Accu)、精确率(Prec)、召回率(Recall) 和 F1值作为评价指标 [11],基于PETA和PA100K 这2个公共图像数据库,与位置信息嵌入、视觉属性聚合和视觉注意一致等3种常规算法进行性能比较。
由表1可知,AL-Transformer模型在PETA和PA100K公共图像数据库上实现了更好的性能。与采用ResNet101作为骨干网络的视觉属性聚合模型相比,本文方法在PETA公共图像数据库上的mA和F1性能分别提高了4.95%和1.59%。与位置信息嵌入模型等基于定位的方法相比,本文方法在2个公共图像数据库上的mA性能分别提高了3.93%和3.24%。本文方法在大多数性能指标上显著优于视觉注意一致方法[12]。
表 1 多种方法的性能比较方法 PA100k PETA mA Accu Pre Recall F1 mA Accu Pre Recall F1 位置信息嵌入 80.68 77.08 84.21 88.84 86.46 86.30 79.52 85.65 88.09 86.85 视觉属性聚合 - - - - - 84.59 78.56 86.79 86.12 86.46 视觉注意一致 79.04 78.95 88.41 86.07 86.83 83.63 78.94 87.63 85.45 86.23 本文方法 84.61 78.86 84.11 91.03 87.43 89.54 80.75 86.15 90.04 88.05 2.2 可视化验证
如图4所示,在PA-100K公开图像数据库的测试集上对本文方法和Swin Transformer网络关注的属性区域进行了可视化验证。其中,绿色边框为Swin Transformer网络的属性注意力图;红色边框为本文方法的属性注意力图。与Swin Transformer网络相比,本文方法有助于为每个属性定位与其相关的区域,例如:在图4中的行人2和行人3中,当识别到属性“眼镜”时,本文方法更好地关注到了头部区域。可视化结果表明,本文方法可有效改善每个属性的空间位置。
2.3 消融试验
本文通过消融试验来验证ASM模块和MCL框架对AL-Transformer模型性能的影响,试验结果如表2所示。
表 2 在PETA和PA100K上的消融实验方法 PA100k PETA mA Accu Pre Recall F1 mA Accu Pre Recall F1 Swing Transformer网络 82.82 81.47 89.08 88.88 88.98 87.20 80.17 86.54 88.73 87.62 Swing Transformer主干网络+MCL框架 83.21 81.70 89.18 88.99 89.09 87.67 71.65 76.81 89.01 82.46 Swing Transformer主干网络+ASM模块 84.00 77.00 82.85 90.08 86.32 89.26 79.55 84.83 89.92 87.30 本文方法 84.61 78.86 84.11 91.03 87.43 89.54 80.75 86.15 90.04 88.05 (1)Swing Transformer主干网络的属性定位精度较差,识别精度较低,证明算法在没有正确的注意区域的情况下,缺乏对属性语义特征的辨别能力,并包含更多噪声。
(2)相比于只使用Swing Transformer主干网络,添加ASM模块可使在PA100K和PETA公共图像数据库的mA性能分别提升1.18%和2.06%,这是因为,ASM模块通过属性预测得分生成可重复使用的属性空间注意力图,指导属性空间特征融合,提高属性定位精度。
(3)在Swing Transformer主干网络上引入MCL框架,可在行人图像上生成随机遮挡,评估其预测结果与正常输入预测结果的差异。通过抑制区域相关性来提高属性定位能力,相比于只使用Swing Transformer主干网络,引入MCL框架后,在PA100K和PETA公共图像数据库的mA性能分别提升了0.39%和0.47%。
(4)本文方法的mA性能指标在PA100k和RETA公共图像数据库上分别比只使用Swing Transformer主干网络提高了1.79%和2.34%。
2.4 白银南站现场验证
基于AL-Transformer模型的铁路客运站旅客属性识别方法已在中国铁路兰州局集团有限公司白银南站试用。
(1)针对安检区域采集的图像,通过本文方法可自动识别进站人员的结构化信息,如性别、年龄范围、穿戴物品(帽子、眼镜、背包、短袖、长外套、长裤、短裤、裙子、连衣裙)、衣物颜色、旅客所在位置/区域、是否携带轮椅\婴儿车\折叠自行车等特征。
(2)根据旅客的上述属性特征进行主动服务,例如:针对坐轮椅的旅客,可及时将信息下发给附近区域的车站工作人员,对其进行重点关注;针对携带折叠自行车的旅客,可及时将其信息推送给站台和候车厅内相关值班人员。
(3)提升旅客描述颗粒度。针对视频分析系统中识别出来的异常行为人员,可提升报警信息的精确性,进一步细化报警信息,例如,细化内容为:身着红色衣服的长发女性,在1站台距离南端口大约200 m处,出现越线行为等。从而,使车站工作人员及时发现异常行为人员,有效阻止事态发展。
3 结束语
本文提出了一种基于AL-Transformer模型的铁路客运站旅客属性识别方法,该方法在 Swing Transformer主干网络的基础上,通过融合MCL框架和ASM模块来精准选择属性信息的相关区域,从而更准确地获取旅客的结构化信息,为工作人员推送更加精准的报警信息,进一步提升铁路客运站的旅客服务质量。
-
表 1 多种方法的性能比较
方法 PA100k PETA mA Accu Pre Recall F1 mA Accu Pre Recall F1 位置信息嵌入 80.68 77.08 84.21 88.84 86.46 86.30 79.52 85.65 88.09 86.85 视觉属性聚合 - - - - - 84.59 78.56 86.79 86.12 86.46 视觉注意一致 79.04 78.95 88.41 86.07 86.83 83.63 78.94 87.63 85.45 86.23 本文方法 84.61 78.86 84.11 91.03 87.43 89.54 80.75 86.15 90.04 88.05  下载: 导出CSV
下载: 导出CSV
表 2 在PETA和PA100K上的消融实验
方法 PA100k PETA mA Accu Pre Recall F1 mA Accu Pre Recall F1 Swing Transformer网络 82.82 81.47 89.08 88.88 88.98 87.20 80.17 86.54 88.73 87.62 Swing Transformer主干网络+MCL框架 83.21 81.70 89.18 88.99 89.09 87.67 71.65 76.81 89.01 82.46 Swing Transformer主干网络+ASM模块 84.00 77.00 82.85 90.08 86.32 89.26 79.55 84.83 89.92 87.30 本文方法 84.61 78.86 84.11 91.03 87.43 89.54 80.75 86.15 90.04 88.05
下载: 导出CSV
-
[1] 贾 健,陈晓棠,黄凯奇. 监控场景中的行人属性识别研究综述[J]. 计算机学报,2022,45(8):1765-1793. DOI: 10.11897/SP.J.1016.2022.01765 [2] Kumar N, Berg A, Belhumeur P N, et al. Describable visual attributes for face verification and image search[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(10): 1962-1977. DOI: 10.1109/TPAMI.2011.48
[3] Kumar N, Belhumeur P, Nayar S. FaceTracer: a search engine for large collections of images with faces[C]//10th European Conference on Computer Vision, 12-18 October, 2008, Marseille, France. Berlin: Springer, 2008: 340-353.
[4] Bourdev L, Maji S, Malik J. Describing people: a poselet-based approach to attribute classification[C]//2011 International Conference on Computer Vision, 06-13 November 2011, Barcelona, Spain. New York: IEEE, 2011: 1543-1550.
[5] Liu X H, Zhao H Y, Tian M Q, et al. HydraPlus-Net: attentive deep features for pedestrian analysis[C]//Proceedings of the 2017 IEEE International Conference on Computer Vision, 22-29 October 2017, Venice, Italy. New York: IEEE, 2017: 350-359.
[6] Liu P Z, Liu X H, Yan J J, et al. Localization guided learning for pedestrian attribute recognition[C]//29th British Machine Vision Conference, 3-6 September 2018, Newcastle, UK. BMVA Press, 2018.
[7] Sarafianos N, Xu X, Kakadiaris I A. Deep imbalanced attribute classification using visual attention aggregation[C]//Proceedings of the 15th European Conference on Computer Vision, 8-14 September, 2018, Munich, Germany. Berlin: Springer, 2018: 708-725.
[8] Tang C F, Sheng L, Zhang Z X, et al. Improving pedestrian attribute recognition with weakly-supervised multi-scale attribute-specific localization[C]//Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, 27 October 2019-02 November 2019, Seoul, Korea (South). New York: IEEE, 2019: 4996-5005.
[9] Liu Z, Lin Y T, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision, 10-17 October 2021, Montreal, Canada. New York: IEEE, 2021: 9992-10002.
[10] Deng Y B, Luo P, Loy C C, et al. Pedestrian attribute recognition at far distance[C]//Proceedings of the 22nd ACM International Conference on Multimedia, November 2014, 0rlando, USA. New York: ACM, 2014: 789-792.
[11] Li D W, Zhang Z, Chen X T, et al. A richly annotated pedestrian dataset for person retrieval in real surveillance scenarios[J]. IEEE Transactions on Image Processing, 2019, 28(4): 1575-1590. DOI: 10.1109/TIP.2018.2878349
[12] Guo H, Zheng K, Fan X C, et al. Visual attention consistency under image transforms for multi-label image classification[C]//Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 15-20 June 2019, Long Beach, CA, USA. New York: IEEE, 2019: 729-739.
-
期刊类型引用(2)
1. 谭宇文,刘瑞敏,王晓东,赵栋,曾雅雯. 基于改进U-Net的单轨受电弓滑块图像分割方法. 轨道交通材料. 2024(04): 63-67 .  百度学术
百度学术
2. 朱俊霖,姚小文,邢宗义. 基于激光位移传感器的城轨列车受电弓滑板磨耗检测方法. 铁路计算机应用. 2023(08): 87-93 . 本站查看
其他类型引用(0)
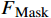
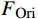
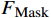
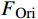
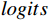
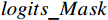
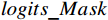
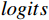
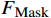
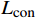
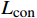
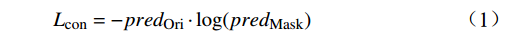
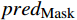
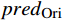
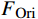
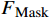


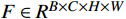

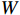

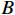
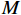

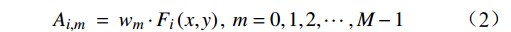
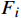

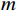
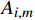
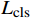
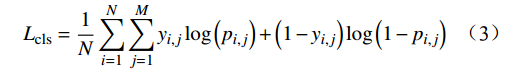


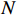

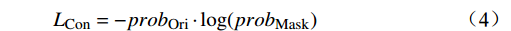

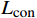

计量
- 文章访问数: 85
- HTML全文浏览量: 24
- PDF下载量: 20
- 被引次数: 2
