

Prediction technology of railway freight loading and unloading time based on gradient boosting decision tree model
-
摘要: 铁路货运装卸时间的精准预测可提升铁路货运系统的调度合理性和服务质量,但装卸时间受多种因素影响。文章针对铁路货运装卸时间预测问题,从铁路货运运单全流程信息中挖掘运单属性与货运装卸时间的关系,以分类与回归树为基础模型,在LightGBM框架下构建梯度提升决策树模型;对铁路货运运单全流程信息中的相关数据进行整合、对数变换、增加特征等预处理,形成运单数据集;采用该数据对构建的模型进行训练,结果表明,构建的模型对货运装卸时间的预测性能优于与其对比的其他机器学习模型。将该模型应用在实际货运装卸业务场景时,实际准确率依旧高于其他对比模型。Abstract: Accurate prediction of railway freight loading and unloading time can improve the scheduling rationality and service quality of railway freight systems, but freight loading and unloading time is affected by various factors. Aiming at the problem of railway freight loading and unloading time prediction, this paper excavated the relationship between freight bill attributes and freight loading and unloading time from the entire process information of freight bills, based on the classification and regression tree model, constructed a gradient boosting decision tree model under the LightGBM framework. The paper integrated, logarithmically transformed, and added features to the relevant data of the entire process of railway freight waybill information to form a waybill dataset, using this dataset to train the constructed model. The results show that the prediction performance of the constructed model for freight loading and unloading time is superior to other machine learning models compared. When this model was applied to actual freight handling business scenarios, the actual accuracy was still higher than other comparison models.
-
铁路货运运单经历需求提报受理、进货装车、挂运出发、倒换装、到达卸车、内外交付、送货等流程[1],相较于铁路客运,其整体作业链条较长,过程复杂。货运的装车预计完成时间可为列车调度人员进行列车调度提供重要参考,对其精确预估可显著降低调度过程中存在的排队延迟,减少大量等待时延,从而提升铁路货运效率。对发起运单的客户来说,对货运时间的精准预测,特别是卸车预计完成时间的精准预测,有助于客户合理安排取货时间,提升铁路货运服务质量。目前,针对铁路货运装卸时间预测技术的研究还在起步阶段,本文从数据出发,构建梯度提升决策树模型,挖掘货运运单中的各项特征与对应装卸时间的相关性,使模型更加精准地预测货运装卸时间。
1 相关技术
梯度提升决策树(GBDT ,Gradient Boosting Decision Tree)是集成学习的一种经典算法,被广泛应用在工业场景中[2]。GBDT的基础模型是分类与回归树(CART ,Classification And Regression Tree)模型。
1.1 CART模型
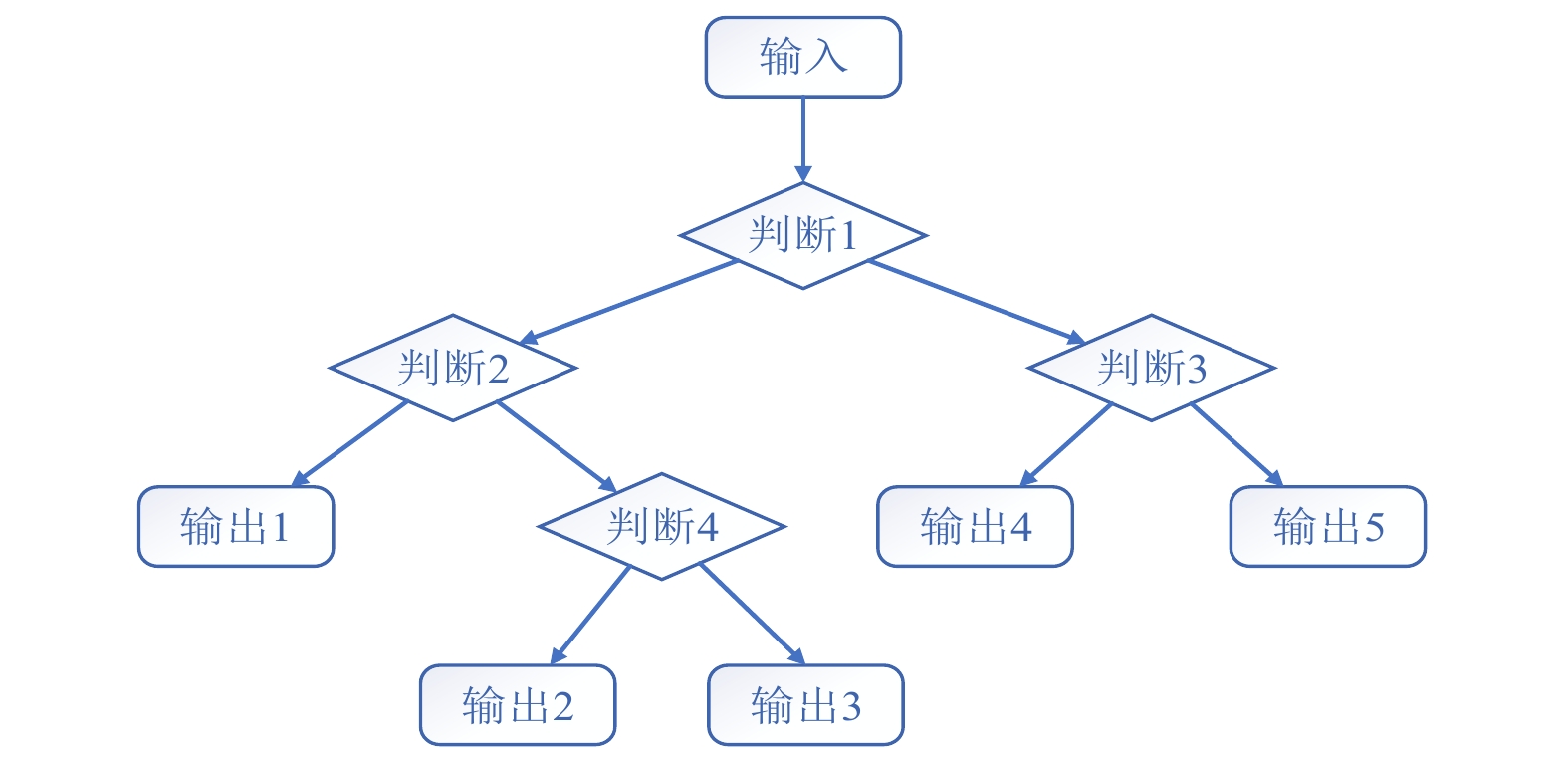
CART模型是一个二叉树,其整体结构如图1所示。其中,每一个判断代表一次划分。其计算过程为:输入数据从树的根节点出发,经过一系列分支节点的判定后,得到目标叶子节点,并将该叶子节点中对应的数值作为树的输出结果。该数值来源于训练集中所有划分到该节点的输出值的算术平均值。
CART模型的构建是一个特征空间的划分过程。切分变量
$j$ 和切分点$s$ 的选择取决于划分后的数据$y$ 与该集合的对应数值$c$ 的误差。满足所有距离之和最小的$j$ 和$s$ 的选择,即为最优切分变量与切分点,可表示为$$ \mathop {\min }\limits_{j,s} \left[ {\mathop {\min }\limits_{{c_1}} \sum\limits_{{x_i} \in {R_1}(j,s)} {{{({y_i} - {c_1})}^2}} + \mathop {\min }\limits_{{c_2}} \sum\limits_{{x_i} \in {R_2}(j,s)} {{{({y_i} - {c_2})}^2}} } \right] $$ (1) 其中,Rm 表示所训练数据中所有被划分到第 m 个叶子节点的数据的输入 x 的集合。在获得最优切分变量
$j$ 与切分点$s$ 后,需要重新计算2个叶子节点对应的输出值。将上述步骤分别在2个子空间上递归进行,直到所有节点都不可划分。1.2 GBDT模型
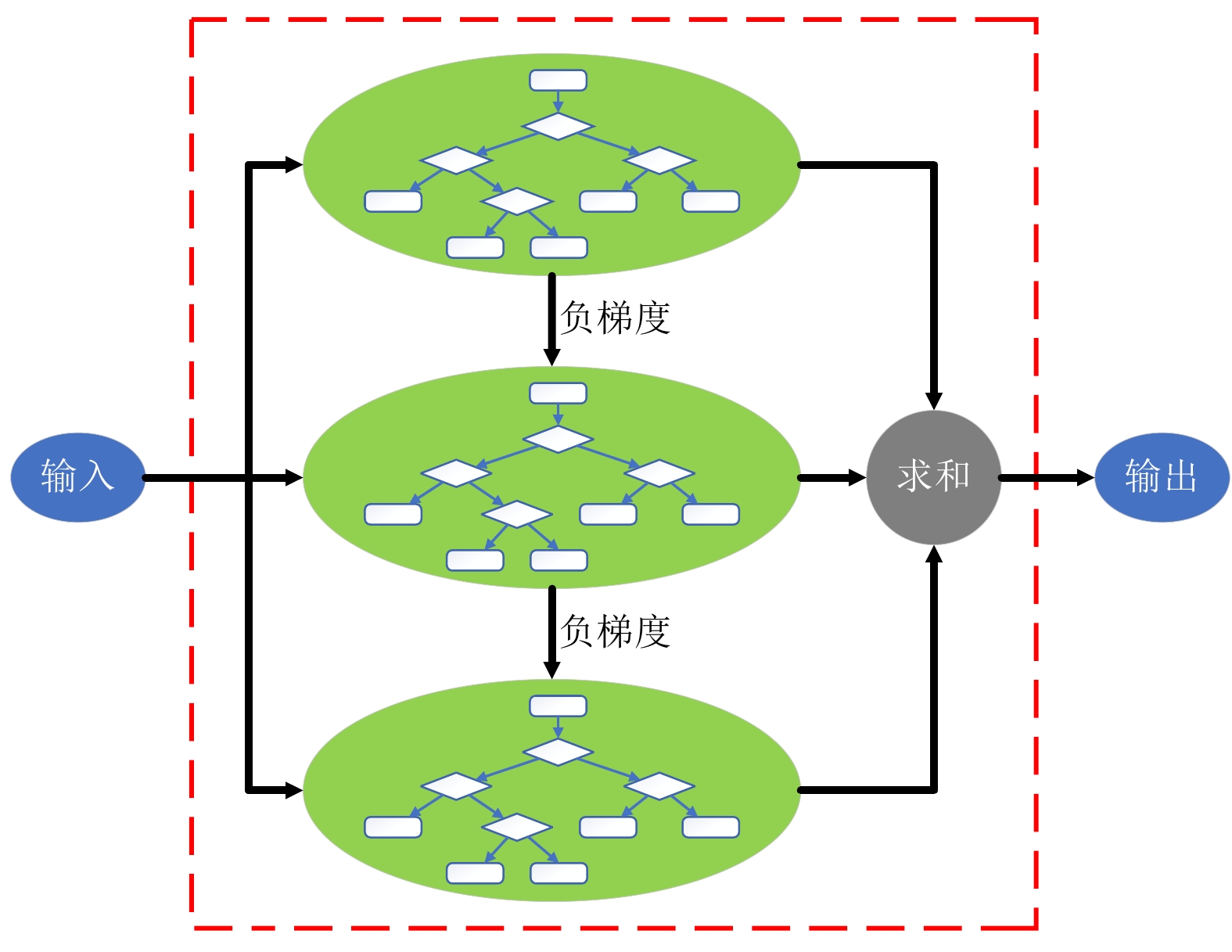
GBDT模型以CART模型为基础学习器,利用损失函数的负梯度在当前模型的值作为GBDT算法中残差的近似值[3]。GBDT模型的结构如图2所示。
图2中,除第1个CART模型之外,每个CART模型学习的都是上1个CART模型的预测结果与目标输出的损失函数的负梯度。设GBDT模型的计算符号为
$\mathcal{F}( \cdot )$ ,其中,第$i$ 个CART模型的计算符号为${T_i}( \cdot )$ ,前$k$ 个CART模型得到的预测值记为${\mathcal{F}_k}(x)$ ,那么${T_k}(x)$ 的更新表示为$$ {T_k}(x) = \mathop {\arg \min }\limits_{{T_k}(x)} \left[ { - {\nabla _{{\mathcal{F}_{k - 1}}(x)}}L\left( {y,{\mathcal{F}_{k - 1}}(x) + {T_k}(x)} \right)} \right] $$ (2) 其中,
$L(y,{\mathcal{F}_{k - 1}}(x))$ 表示前$k - 1$ 个CART模型的输出与目标结果经过损失函数计算出的误差值。使用负梯度代替残差,显著增加了普适性,可使GBDT模型在优化中自由选择不同的损失函数。2 铁路货运数据分析处理
本文使用国家铁路智能运输系统工程技术研究中心2021年6月铁路货运运单全流程信息中心相关数据作为实验数据集,对其进行分析处理后,形成运单数据集。
2.1 相关数据
铁路货运运单全流程信息中与货运装卸相关的数据有时间戳表和运单属性表。时间戳表统计了每条运单从需求提报到内外交付各操作流程的具体时刻;运单属性表统计了每条运单所对应的各项属性信息,包括货物属性、托运人与收货人的姓名、装卸股道的部分记录及其他信息。2021年6月铁路货运运单全流程信息中,时间戳表含有1821417条数据,运单属性表含有3498464条数据。
在装卸车预测中,输入的10个特征为运单属性表中的收货人、托运人、装/卸车工作站、品名、装/卸车专用线、货物重量、车数、运输方式、运单类型和箱数,而输出结果即装卸车时间,来源于时间戳表,因此需要对2个表中的各项数据进行整合。2个表中共同拥有的属性有5个,分别为:运单号码、需求单号、发站名称、到站名称及制票时间。由于在实际业务中,运单号码与需求单号并不能建立一一对应的关系,为保证2个表数据的绝对对应,选择使用运单号码、需求单号、发站名称、到站名称作为匹配的关键字。匹配成功的数据共计1 096 206条。
2.2 特征分析与处理
2.2.1 离散型数据和连续型数据
运单属性的数据分为离散型数据和连续型数据。离散型数据在货运运单数据集中可表现为汉字文本或代号,用于表示不同的类别。当整数作为离散型数据时,数值的大小不代表两类间的距离,仅表示分类。连续型数据表现为整数或浮点数,其数值大小具有业务含义。本文把所有离散型数据全部替换为整数类型的索引码,基于以下2点考虑:(1)由于铁路货运的数据隐私性[4-5],托运人、收货人、货物品名等数据应尽量避免明文使用,降低隐私泄露风险;(2)由于LightGBM框架可直接将数据设定为类别数据,因而支持以不同方式分别处理离散型数据和连续型数据。
本文选择装卸车的完成时间和入线时间之差作为货运装卸任务下的目标预测值。这两个时间差以小时为单位,分别叫做装车时间和卸车时间,认为装卸车时间差不应超过7天,因此仅保留数值范围在0~168的数据项。此外,本文取入线时间对应的星期和作业时点为额外特征输入模型,以挖掘货运装卸过程中的作息规律。由于星期和作业时点都存在循环性,我们将其当作离散型数据处理。
2.2.2 “长尾”分布
货运装卸车数据中的连续型数据普遍存在着“长尾”分布特征。分布较为集中的数据在总样本中占比较大,被称为头部类数据。而少量数据的数值多样性大、分布零散,被称为尾部类数据。铁路货运中,按运单统计,98%的货车数为1辆,最大货车数为73辆;98%的货物重量小于80 t,最大货物重量为4 799 t。这种不平衡会导致特征空间发生扭曲,从而忽略尾部类数据。但直接忽略尾部类数据并不适合铁路货运业务场景。为使数据分布更加合理,本文对这几类数据采用对数变换的操作,公式为
$$ \log (1+x) \leftarrow x(x \geqslant 0), \text { 满足} \left\{\begin{aligned} &\lim \limits _{x \rightarrow+\infty} \log (1+x) \ll \lim\limits _{x \rightarrow+\infty} x \\ &\lim \limits_{x \rightarrow 0} \log (1+x) \sim \lim\limits _{x \rightarrow 0} x \end{aligned}\right. $$ (3) 在装卸时间的评估中,计算还原后的数据以保证真实性。
3 装卸时间预测
3.1 预测建模
铁路货运的装车和卸车完成时间预测是基于业务生成的运单数据计算出对应的装车和卸车的预计完成时间。装卸时间受多方因素的影响[6],包括装卸线、车站工作效率、货物属性等因素,同时,这些因素之间也相互影响。
假设已知的运单信息为
${x^{(1)}},{x^{(2)}}, \cdots ,{x^{(n)}}$ ,其中,每一个${x^{(i)}}$ 表示运单信息中用于预测装卸时间的一维特征。那么,装卸预计完成时间为$$ \hat y = \mathcal{F}\left( {{x^{(1)}},{x^{(2)}}, \cdots ,{x^{(n)}}} \right) $$ (4) 其目标是找到一个最优的装卸预测模型
$\mathcal{F}$ ,使其满足在输入数据为运单特征${x^{(1)}},{x^{(2)}}, \cdots ,{x^{(n)}}$ 时,输出结果$\hat y$ 与该运单的实际装卸时间$y$ 最为接近。3.2 模型训练
本文使用LightGBM[7]框架直接构建GBDT模型, LightGBM是实现GBDT模型常用的框架之一,相同于XGBoost[8],目前已有成熟的应用编程接口,可直接使用。本文采用48核Intel(R) Xeon(R) Silver 4214R CPU @ 2.40 GHz及256 GB内存的硬件设备,以保障海量数据下的模型训练。
运单数据集在使用过程中被划分为3部分:(1)2021年6月20日之前(含20日)的数据为训练集;(2)2021年6月21~25日的数据为验证集;(3)2021年6月25日之后(不含25日)的数据为测试集。在训练中,由于“长尾”分布的影响,本文选择L1损失计算误差并更新参数。但L1损失容易忽略尾部类数据,因此,在输入数据中添加了不同站点装卸时间的平均数(简称:历史平均时间),辅助模型关注尾部类特征。输入的每条数据都是1个13维向量,表示输入的货运运单的13个特征。而每条输出数据只有1个维度,为装卸作业时间。
在经过多轮训练的模型中,选择在验证集下损失值最小的模型作为最终训练结果,从而减少过拟合问题的发生。在LightGBM框架下构建GBDT模型需要多个超参数定义模型结构及训练细节,学习率、叶子节点数、最大树高、特征随机选择比例等对模型预测的准确率也会产生一定影响。本文使用Optuna库中的框架,从由9项超参数构成的50个组合中,选择最优结果作为模型的默认超参数组合。
4 实验结果与分析
4.1 误差评估
本文采用运单数据集对构建的GBDT模型进行训练,并采用平均绝对误差 ( MAE ,Mean Absolute Error)、均方根误差(RMSE,Root Mean Square Error)和平均绝对百分比误差( MAPE,Mean Absolute Percentage Error)3个指标对模型预测能力进行评估。
$$ {{E_{{\rm{MAE}}} }} = \frac{1}{n}\sum\limits_{i = 1}^n {\left| {{y_i} - {{\hat y}_i}} \right|} $$ (5) $$ {{E_{\rm{RMSE}}}} = \sqrt {\frac{1}{n}\sum\limits_{i = 1}^n {{{\left( {{y_i} - {{\hat y}_i}} \right)}^2}} } $$ (6) $$ {E_{\rm{MAPE}}} = \frac{1}{n}\sum\limits_{i = 1}^n {\left| {\frac{{{y_i} - {{\hat y}_i}}}{{{y_i}}}} \right|} $$ (7) 上述指标的数值越低,代表预测值和真实值的误差越小,模型性能越优。与本文模型进行对比的机器学习模型有:线性回归(LR,Linear Regression)、支持向量机(SVM,Support Vector Machine)、多层感知机(MLP,Multilayer Perceptron)、决策树(DT,Decision Tree)及随机森林(RF,Random Forest)。其中,RF模型和GBDT模型采用LightGBM框架构建,其他模型均基于Scikit Learn框架构建。对货运装车和卸车任务分别进行训练和评估,统计结果如表1所示。
表 1 不同方法对货运装卸预测指标统计模型 MAE MAPE RMSE 装车 卸车 装车 卸车 装车 卸车 LR 1.745 1.904 0.998 0.979 4.758 4.839 SVM 3.794 2.863 3.435 2.695 7.677 5.607 MLP 1.797 2.044 1.332 1.283 4.547 5.095 DT 2.421 2.248 1.211 1.069 7.908 5.731 RF 1.755 1.760 1.076 0.956 4.886 4.744 GBDT 1.413 1.662 0.808 0.847 4.070 4.536 由表1可知,在铁路货运装卸时间预测任务上,对于3种不同的评估指标,相对于其他模型,GBDT模型的预测误差最低。
4.2 业务评估
4.2.1 限定误差时间内的准确率
在铁路货运实际业务流程中,限定误差时间内的准确率是一项重要指标。假定预测装卸时间与真实装卸时间的误差在
$k$ 之内,则认定为正确预测,限定误差时间在$k$ 内的准确率(ACC)是正确预测数量占全部预测数量的百分比,其公式为$$ {{ACC}_k} = \frac{1}{n}\sum\limits_{i = 1}^n {{{{I_\alpha}}_{|{y_i} - {{\hat y}_i}| < k}}} \times 100\% $$ (8) 其中,Iα表示指示函数,当条件α满足时,其值为1,否则为0。对本文来说,ACC的值越高,代表模型越契合实际货运装卸业务场景。本文计算了限定误差时间为3 h、6 h和12 h的准确率,其结果如表2所示。由表2可知,在3个货运业务中常用的限定误差时间下,GBDT模型的准确率均优于其他模型。
表 2 不同限定误差时间下的准确率统计模型 ACC3 ACC6 ACC12 装车 卸车 装车 卸车 装车 卸车 LR 88.42% 85.36% 93.75% 94.46% 97.11% 98.08% SVM 62.87% 70.49% 88.51% 93.84% 94.78% 97.60% MLP 87.35% 85.64% 93.48% 94.54% 97.44% 97.93% DT 86.01% 82.65% 92.34% 92.96% 95.73% 97.16% RF 88.19% 87.55% 93.97% 95.25% 97.22% 98.19% GBDT 90.50% 88.48% 95.23% 95.72% 98.02% 98.24% 4.2.2 货运装卸车时间预测特征重要性排序
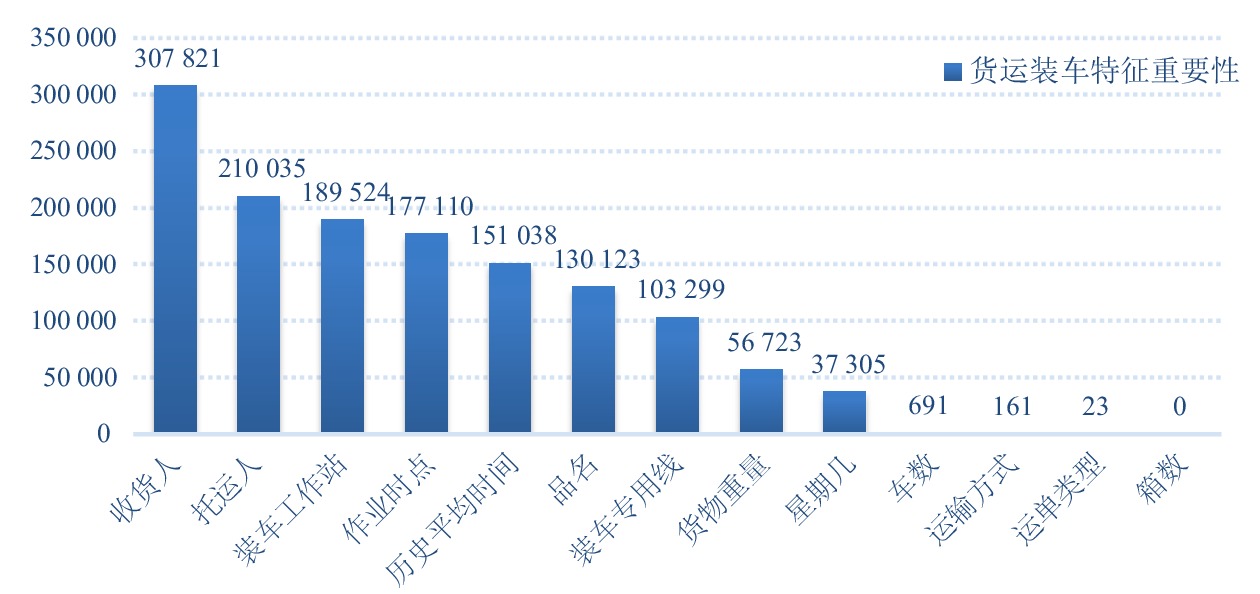
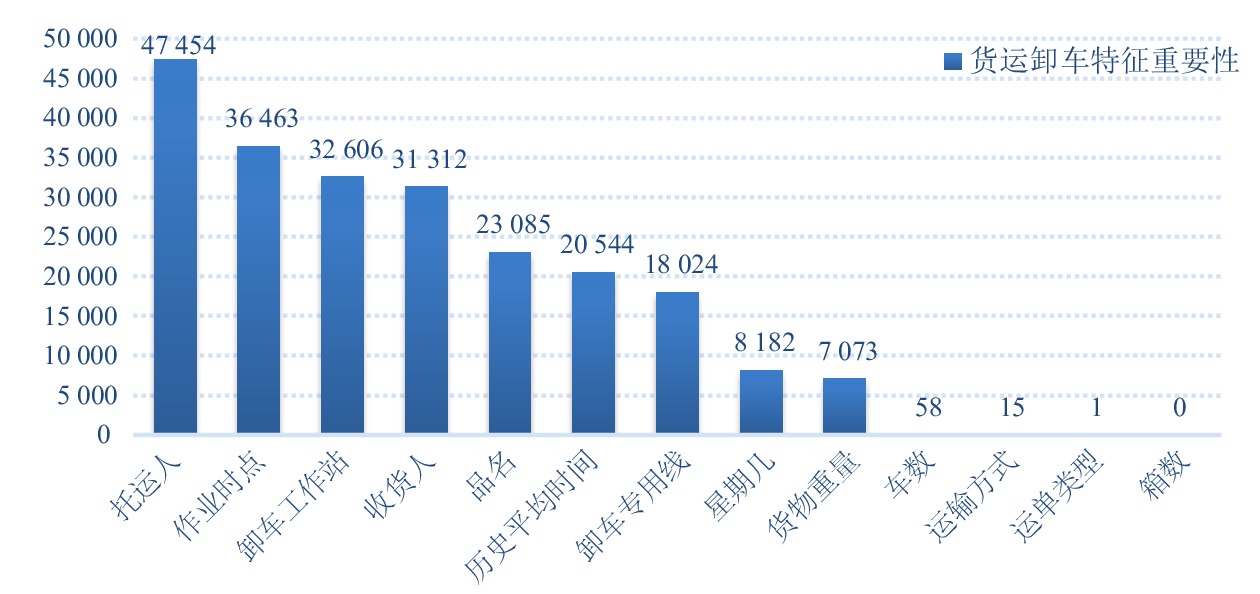
本文统计了输入特征的重要性,将GBDT模型中特征对应的树结点分裂的次数(该特征的使用次数)作为其重要性数值,预测过程中使用次数越多,表示该特征在模型预测中的重要性程度越高。货运装车时间和卸车时间预测的特征重要性从高到低排序分别如图3和图4所示。其中,横坐标为各输入特征,纵坐标为代表特征重要性的数值,特征重要性数值越大,代表该特征对于货运装卸时间的影响越大。
由图3、图4可知,无论是装车任务还是卸车任务,托运人与收货人都极为重要。货运业务中,那些经常发起运单的托运人与收货人存在隐藏的偏好,例如与公司业务相关等,会导致其发起的运单有相似的特征。另外,相对重要的因素还有历史平均时间及作业时点。前两者衡量的是不同站点的装卸能力,而后者体现的是站点每天工作状态的周期性规律。
5 结束语
本文基于GBDT模型对铁路货运装卸时间进行预测。先对数据进行预处理,获得运单中记录的各项属性数据;在LightGBM框架下构建了GBDT预测模型;并比较多个机器学习模型在预测货运装卸时间中的性能表现。实验结果表明,相较于其他模型,GBDT模型预测的结果误差最小,且在实际业务场景中,GBDT模型也可在限定误差时间内达到高的准确率。
-
表 1 不同方法对货运装卸预测指标统计
模型 MAE MAPE RMSE 装车 卸车 装车 卸车 装车 卸车 LR 1.745 1.904 0.998 0.979 4.758 4.839 SVM 3.794 2.863 3.435 2.695 7.677 5.607 MLP 1.797 2.044 1.332 1.283 4.547 5.095 DT 2.421 2.248 1.211 1.069 7.908 5.731 RF 1.755 1.760 1.076 0.956 4.886 4.744 GBDT 1.413 1.662 0.808 0.847 4.070 4.536  下载: 导出CSV
下载: 导出CSV
表 2 不同限定误差时间下的准确率统计
模型 ACC3 ACC6 ACC12 装车 卸车 装车 卸车 装车 卸车 LR 88.42% 85.36% 93.75% 94.46% 97.11% 98.08% SVM 62.87% 70.49% 88.51% 93.84% 94.78% 97.60% MLP 87.35% 85.64% 93.48% 94.54% 97.44% 97.93% DT 86.01% 82.65% 92.34% 92.96% 95.73% 97.16% RF 88.19% 87.55% 93.97% 95.25% 97.22% 98.19% GBDT 90.50% 88.48% 95.23% 95.72% 98.02% 98.24%
下载: 导出CSV
-
[1] 苑晓明. 北京局集团公司铁路货运业务流程优化与设计 [J]. 铁道货运,2021,39(6):20-25. [2] 胡 瑞,文 超,张梦颖,等. 高速列车晚点预测的机器学习模型 [J]. 中国铁路,2020(11):72-77. [3] Friedman J H. Greedy function approximation: a gradient boosting machine [J]. Annals of Statistics, 2001, 29(5): 1189-1232. DOI: 10.1214/aos/1013203450
[4] 张 骁. 铁路数据安全与隐私保护管理策略研究 [J]. 铁路计算机应用,2021,30(11):43-46. [5] 王明哲,金久强,李 健,等. 铁路旅客信息安全与大数据应用管理流程研究 [J]. 铁路计算机应用,2019,28(4):28-30,35. [6] 王文科. 广铁集团铁路货运装卸现状分析及思考 [J]. 铁道货运,2018,36(9):79-84. [7] Ke G L, Meng Q, Finley T, et al. LightGBM: a highly efficient gradient boosting decision tree[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems, 4-9 December, 2017, Long Beach, USA. Red Hook, USA: Curran Associates Inc. , 2017: 3149-3157.
[8] Chen T Q, Guestrin C. XGBoost: a scalable tree boosting system[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 13-17 August, 2016, San Francisco, USA. New York, USA: ACM, 2016: 785-794.
-
期刊类型引用(1)
1. 李小庆,蔡俊平,曹记胜. 动客车“一日一图”客调命令管理安全风险的研究与对策. 太原铁道科技. 2020(02): 30-32 .  百度学术
百度学术
其他类型引用(3)
































计量
- 文章访问数: 297
- HTML全文浏览量: 47
- PDF下载量: 61
- 被引次数: 4
