

Railway dispatching command parsing algorithm based on generative summarization model and knowledge distillation algorithm
-
摘要: 随着铁路信息化的发展,利用算法自动解析大量铁路调度命令(简称:调令)的重要性日益凸显。文章提出了一种基于生成式摘要模型和知识蒸馏算法的铁路调令解析算法,该算法利用生成式摘要模型端到端解析铁路调令,拥有较高的精度和较强的鲁棒性,适应写法多样的调令。采用知识蒸馏算法等多种轻量化策略,设计了新的损失函数和多种模型初始化策略,精简模型尺寸,提升算法速度。该算法在铁路调令数据集上取得了21.6342的Rouge-2分数,推理时间达103 ms,为铁路调令解析技术在铁路场景中的部署提供了参考。Abstract: With the development of railway informatization, the importance of using algorithms to automatically parse a large number of railway dispatching commands has become increasingly prominent. This paper proposed a railway dispatching commands parsing algorithm based on a generative summarization model and a knowledge distillation algorithm. The algorithm used a generative summarization model to analyze railway dispatching commands end-to-end, which had high accuracy and strong robustness, and was suitable for railway dispatching commands of various writing styles. The paper used multiple lightweight strategies such as knowledge distillation algorithm to design new loss functions and multiple model initialization strategies to reduce model size and improve algorithm speed. The algorithm achieved a Rouge-2 score of 21.634 2 on the railway dispatching commands dataset, with an inference time of 103 ms. It provides a reference for the deployment of railway dispatching commands parsing technology in railway scenarios.
-
随着我国铁路运输系统的高速发展,铁路网日趋复杂,列车的换编、停运等调度也愈加频繁,由此产生了大量的调度命令(简称:调令)。这些调令记录着列车调度的各类信息,如换编、停运交路等,是列车运营及维护的重要记录。对不同铁路局集团公司记录的调令进行解析,提取关键词(如时间、车次等信息)并存储,有着重要的意义。同时,随着人工智能、大数据等技术在铁路的深入应用,铁路智能化成为了新的发展方向。调令数据对采用大数据技术分析列车运营也有着重要的作用。
当前,各个铁路局集团公司的调令多依赖于人工手动录入,不同铁路局集团公司记录的调令各有不同,缺乏统一的格式管理。为便于快速记录,调令的记录形式往往比较简洁,采用较多简写形式。
调令中的简写(如zes、ze2等)和专业术语(如crh380a型重联等)较多,且各个铁路局集团公司的简写方式不同,没有固定的模板和特征,难以制定规则。而当前工业界对于命令解析任务常采用正则匹配算法,这种算法依赖人工提取特征,制定模板,泛化性和鲁棒性较低,无法适应各铁路局集团公司的不同记录格式。
为解决这一问题,本文将调令解析视为一种特殊的摘要生成任务,将原始调令视为文档,解析后的数据视为摘要进行处理。针对摘要生成任务,当下研究主要聚焦于抽取式摘要算法和生成式摘要算法。文献[1]利用BERT(Bidirectional Encoder Representation from Transformers)的特性提出了抽取式摘要算法BERTSUM模型[2];文献[3]受到BERTSUM的启发,基于Transformer提出了抽取式摘要算法HIBERT模型[4];文献[5]和文献[6]同样利用预训练模型抽取原文中重要的句子来构成简短的摘要;文献[7]通过修改Transformer的预训练任务提出了生成式摘要模型PEGASUS;文献[8]提出了基于重新检索模块和快速重排模块的生成式摘要模型BiSET。
然而,上述方法也存在一些缺点,抽取式摘要算法多是对原文中的语句进行提取组合,无法生成原文中不存在的词语,不适用于调令解析任务。生成式摘要模型存在参数多、资源占用率高、运行速度慢的缺点,不适合在铁路场景中部署。
为解决上述问题,本文采用生成式摘要模型端到端解析调令,同时采用较小的模型结构进行推理和训练,以实现符合铁路场景的资源占用率和推理速度。为解决小结构模型准确率较低的问题,引入了知识蒸馏算法,利用预训练模型在训练过程中进行监督引导,促使模型学习到预训练模型中的“暗知识”,以达到更高的精度。
1 DistilBART模型
1.1 DistilBART模型结构
预训练模型分为自回归语言模型(Autoregressive Language Models)和自编码语言模型(Autoencoder Language Models)。前者根据上文预测下文或根据下文预测上文,典型代表有T5[9]、GPT( Generative Pre-training)[10]、ELMO(Embedding from Language Models)等[11],多用于生成任务。后者根据上下文语境来进行预测,典型的代表有BERT及其变种模型,常用于语义理解任务。生成式摘要模型(BART,Bidirectional and Auto-Regressive Transformers)结合了自回归语言模型和自编码语言模型的优势[12],通过编码器对输入的文本数据进行编码,提取上下文信息,再通过解码器输出目标文本,在诸多文本生成任务中,尤其是摘要生成任务,取得了较好的结果。
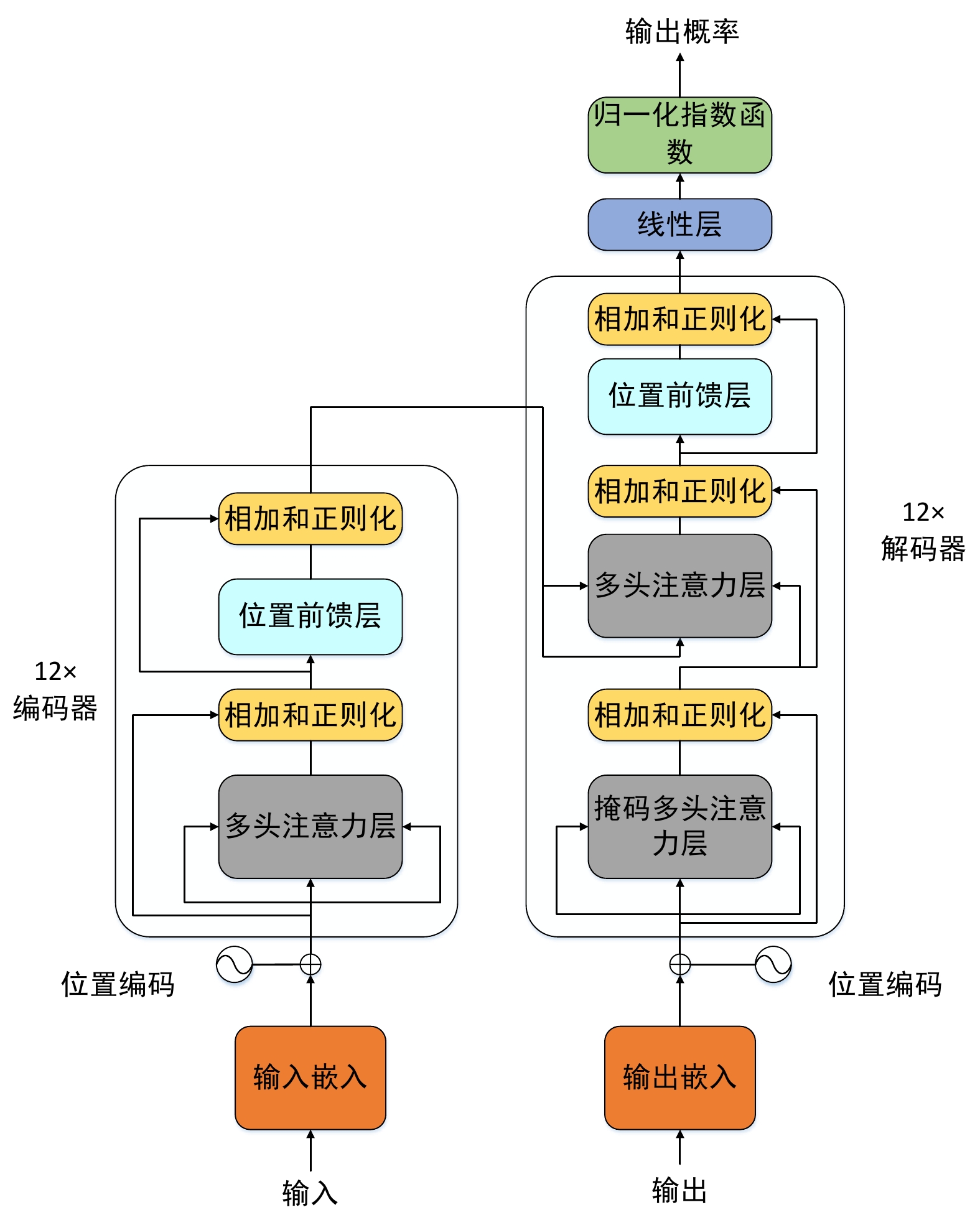
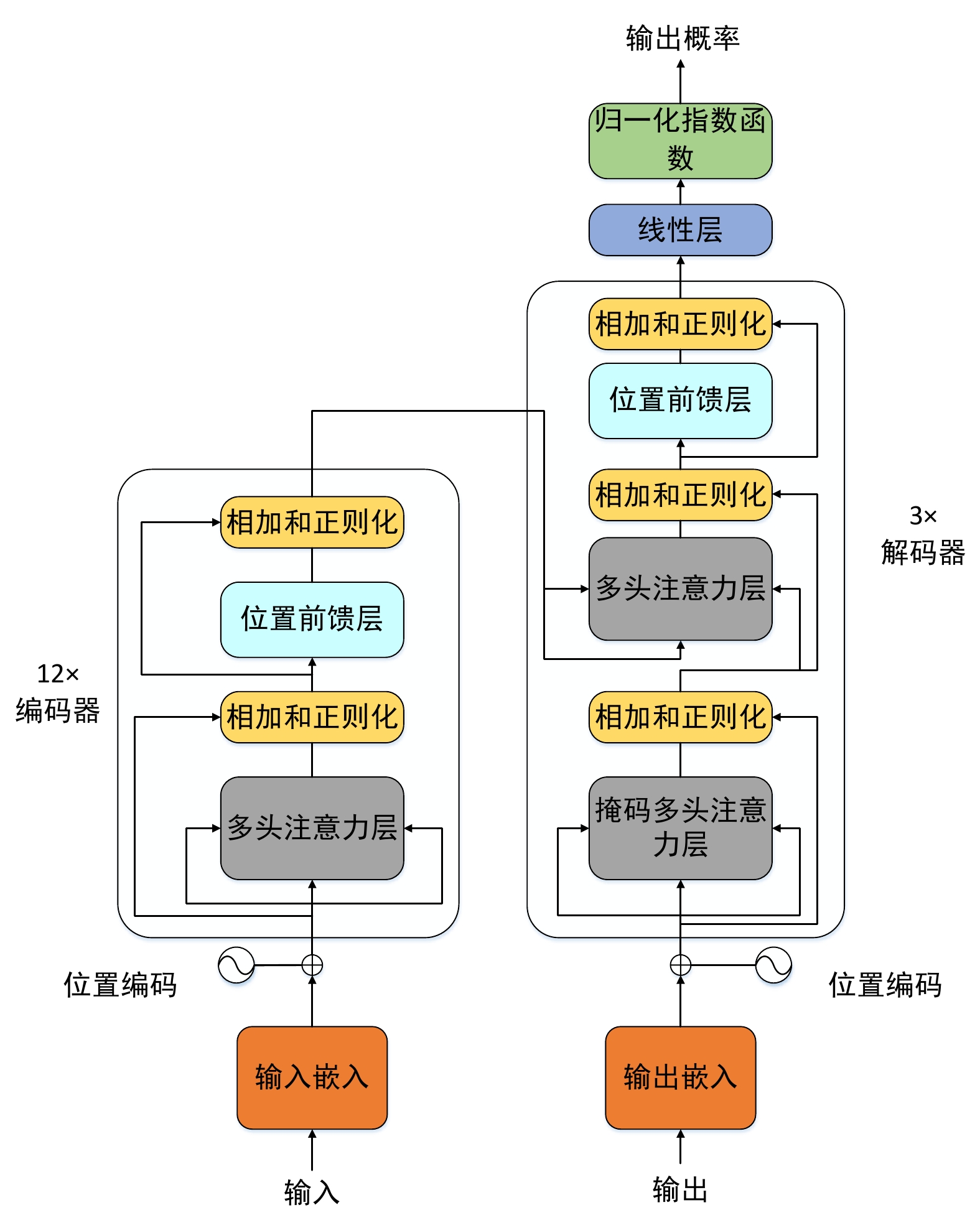
本文基于BART模型结构,提出了DistilBART模型,模型采用12层编码器和3层解码器,模型结构如图1所示。
图1左半部分是编码器(Encoder)由12个相同的模块组合而成,右半部分是解码器(Decoder)由3个相同的模块组合而成。 每个编码器模块由一个多头注意力层(Multi-Head Attention)和一个位置前馈层(Feed Forward)组成。与编码器模块相比,每个解码器模块都有一个额外的掩码多头注意力层(Masked Multi-Head Attention),这是因为解码器需要将编码器的输出视为生成的上下文。同时,为避免梯度消失和梯度爆炸,模型在神经层之间引入了残差连接和层归一化。
编码器主要用于提取全文的语义信息和语义结构,对调令解析任务有着重要的意义,过于简单的编码器结构不利于模型提取调令中的关键信息,因此,DistilBART的编码器设计为12层。而解码器的主要作用是对编码器提取出的语义信息进行解码,以还原成最终的结果。调令规范化后的文本格式较为固定,对解码器的要求较低,因此DistilBART的编码器设计为3层。
1.2 知识蒸馏算法
知识蒸馏算法是一种常用的模型轻量化算法[13],该算法利用大模型(teacher模型)的中间层和最终层输出作为标签,监督训练一个参数较少的小模型(student模型),训练目标是student模型模拟teacher模型的逻辑,输出与teacher模型相近的结果。
因BART模型与DistilBART模型结构相近,采用知识蒸馏算法效果更好,本文将BART-large模型作为teacher模型,对DistilBART模型进行模型训练。
BART-large模型采用了12层编码器和12层解码器的设计,模型结构如图2所示。
1.3 损失函数
本文参考DistilBert和TinyBERT设计了损失函数[14-15]。损失函数共分为3个部分,分别是知识蒸馏损失
$ {Loss}_{KD} $ 、隐藏层损失$ {Loss}_{hid} $ 、和输出损失$ {Loss}_{output} $ 。损失公式为$$ L{\text{oss}} = \alpha Los{s_{KD}} + \beta Los{s_{hid}} + \varphi Los{s_{output}} $$ (1) 其中,
$ \alpha $ 、β、$ \varphi $ 分别为$ {Loss}_{KD} $ 、$ {Loss}_{hid} $ 、$ {Loss}_{output} $ 在$ Loss $ 中的权重。(1)
$ {Loss}_{KD} $ $ {Loss}_{KD} $ 代表DistilBART模型输出的概率分布与teacher模型输出的概率分布间的差异,旨在鼓励DistilBART模型的输出与teacher模型相似,从而学习到更多的知识,2个概率分布间的差异用KL散度衡量,公式为$$ Los{s_{KD}} = \Bigg(\sum\limits_{t = 1}^T {{P_{t + 1}}\log \frac{{{Q_{t + 1}}}}{{{P_{t + 1}}}}} \Bigg){T^2} $$ (2) 其中,
$ {P}_{t+1} $ 和$ {Q}_{t+1} $ 分别代表DistilBART模型和teacher模型在 t+1 处预测的概率分布,并且引入了蒸馏温度$ T $ 来平滑teacher模型的输出,$ {Q}_{t+1} $ 的计算公式如公式(3)所示。$$ {Q_{T + 1}} = \frac{{\exp ({z_{T + 1}}/T)}}{{\displaystyle\sum\limits_j {\exp ({z_j}/T)} }} $$ (3) 其中,
$z$ 代表模型预测的概率值; j∈[0,1,···,n];n 为隐藏层输出结果的个数。$ {P}_{t+1} $ 计算方式相同,不再赘述。(2)
$ {Loss}_{hid} $ $ {Loss}_{hid} $ 代表DistilBART模型隐藏层输出的概率分布与teacher模型中隐藏层输出的概率分布之间的差异,旨在鼓励DistilBART模型从teacher模型特定的隐藏层中学习知识。隐藏层概率分布间的差异用均方差损失函数衡量,如公式(4)所示。$$ Los{s_{hid}} = \frac{1}{T}\sum\limits_{{\text{t = 1}}}^T {\sum\limits_{l = 1}^L {{{(H_l^S - H_{\varphi (l)}^T)}^2}} } $$ (4) 其中,
$ {H}_{l}^{S} $ 代表DistilBART模型隐藏层$ l $ 层的输出;$ {H}_{\varphi \left(l\right)}^{T} $ 代表teacher模型隐藏层$ \varphi \left(l\right) $ 层的输出;$ \varphi \left(l\right) $ 为DistilBART模型和teacher模型的映射函数;L代表隐藏层的层数。(3)
$ {Loss}_{output} $ $ {Loss}_{output} $ 代表DistilBART模型最终输出与真实标签间的差异,旨在微调DistilBART模型,用交叉熵损失函数来衡量,如公式(5)所示。$$ Los{s_{output}} = - \sum\limits_{t = 1}^T {\log p({y_{t + 1}}|{y_{1:t}},x)} $$ (5) 其中,
$ x $ 代表输入;$ y $ 代表模型输出。1.4 DistilBART模型初始化
相较于传统的深度学习模型在训练前随机初始化模型参数,本文的DistilBART模型直接复制teacher模型中编码器的全部参数及解码器中的部分参数,因teacher模型训练自大规模数据集,模型参数包含大量从数据集中学习到的知识,DistilBART模型复制这些参数可继承这些知识,从而在训练中更好地收敛,并获得更好的性能。
由于teacher模型中每个解码器层所包含的知识并不相同,采用teacher模型中不同的解码器层初始化DistilBART模型也会对模型的性能造成较大的影响。本文采用公式(6)作为映射函数。
$$ \varphi ({{L)}} = L \cdot \frac{{{L_T}}}{{{L_S}}} - 1 $$ (6) 其中,
${L}_{T}$ 为teacher模型解码器层数;${L}_{S}$ 为DistilBART模型解码器层数;$L$ 从1开始计数。将teacher模型和DistilBART模型中的解码器层进行映射。利用teacher模型中映射后的解码器层层初始化DistilBART模型的3层解码器,并在训练中进行监督。2 实验验证
本文采用Rouge-2作为衡量模型性能的标准,计算公式为
$$ \begin{split} &ROUGE2 =\\ & \quad \frac{{\displaystyle\sum\limits_{S \in \{ {Re} feremceSummaries\}, \;gra{m_2} \in S} {\displaystyle\sum {Coun{t_{match}}(gra{m_2})} } }}{{\displaystyle\sum\limits_{S \in \{ {Re} feremceSummaries\} ,\;gra{m_2} \in S} {\displaystyle\sum {Count(gra{m_2})} } }} \end{split} $$ (7) 其中,
$ ReferemceSummaries $ 代表真实标注;S代表调令;$ {gram}_{2} $ 代表对文本进行分词后得到的二元词对;$ {Count}_{match}\left({gram}_{2}\right) $ 代表生成的文本和真实标注中重合的二元词对个数;$ Count\left({gram}_{2}\right) $ 代表真实标注中二元词对个数。2.1 数据集
本文采用的数据集为自建数据集,测试集与训练集分别占总数据集的20%和80%。原始数据采样自历年各铁路局集团公司留存的调令信息。由于数据量较大,全部采用手工标注的方式费时费力,本文采用自动标注和手动标注混合的方式对数据集进行标注。其中,自动标注方式采用正则匹配算法,自动解析数据集中格式匹配的调令,并将解析的结果存储为标注文件。手动标注则是对数据集中正则匹配算法无法解析的调令进行手动标注。混合标注的方式可有效节省人力物力,提高标注效率。
本文参考了Kim等人提出的伪标签(PL,Pseudo -Labeling)[16]算法生成新的数据集以提升模型的学习能力和性能。同时,为确保teacher模型生成的文本与原始数据相近,本文提出了带阈值的PL算法,即只有当teacher模型生成的文本与原始数据的Rouge-2大于阈值时,本文才会将生成的文本放入新数据集中,否则将原始数据放入。
2.2 实验设置
本文实验采用的操作系统为Linux,编程语言为Python,算法框架为Pytorch,CPU型号为Xeon E5-2698,GPU型号为Tesla V100。本文的所有实验学习率均为0.0003,生成最大长度为60,batch size为16,迭代次数为6。公式(1)中的权重
$ \alpha $ 为0.2, β 为3,$ \phi $ 为0.2,公式(3)中的 T 为2。2.3 实验结果及分析
2.3.1 DistilBART与其他算法实验结果对比
DistilBART与其他算法实验结果如表1所示,其中,BART-large模型代表teacher模型,DistilBART模型代表文本提出的模型。
表 1 本文模型与其他算法实验结果对比模型名称 模型尺寸/Mbyte 推理时间/ms Rouge-2 正则匹配 20 10.1325 BART-large 1550 204 22.2897 DistilBART 973 103 21.6342 由表1可知,基于本文模型的解析算法精度远超正则匹配算法,基于BART-large模型的解析算法虽然精度更高,但速度较慢,资源占用较多,难以在实际中应用。而本文提出的DistilBART模型相较BART-large模型损失了2.9%的精度,但模型尺寸减少37.2%,推理速度提升49.5 %。在不损失太大精度的前提下,速度提升和尺寸减少明显,便于后续在铁路中部署和落地。
2.3.2 PL算法对实验结果的影响
为验证PL算法对于实验结果的影响,本文分别在原始数据集、PL算法生成的数据集、带阈值的PL算法生成的数据集(简称: PL-10 数据集)上进行实验。本文模型的3层解码器初始参数分别复制自teacher模型的0、6、11层,采用同样的解码器层进行监督,实验结果如表2所示。
表 2 本文模型在不同训练数据集上的实验结果训练数据集 Rouge-2 原始数据集 21.5375 PL数据集 21.3485 PL-10数据集 21.5549 由表2可知,本文提出的PL-10数据集较原始数据集可有效提升模型的性能,让DistilBART模型更好地学习数据集中包含的信息。而由于teacher模型生成的部分文本与原始数据差距较大,影响了DistilBART的学习,导致PL算法生成的数据集效果较差。
2.3.3 模型初始化及监督策略对实验结果的影响
为验证模型初始化时的参数选择及训练过程中隐藏层监督对DistilBART模型的影响,本文在PL-10数据集上分别实验了3个结构相同、初始化及监督策略不同的模型,分别是初始化时复制teacher模型0、6、11解码器层参数且训练时采用相同层监督的DistilBART-0,初始化时复制teacher模型0、6、11解码器层参数且训练时采用公式(6)映射后的解码器层(简称:映射层)监督的DistilBART-1,以及初始化时复制映射层参数且训练时采用相同层监督的DistilBART-2模型(即本文提出的模型),实验结果如表3所示。
表 3 不同初始化及监督策略对模型的影响模型名称 Rouge-2 DistilBART-0 21.4361 DistilBART-1 21.5549 DistilBART-2 21.6342 由表3可知,由于teacher模型中的不同解码器层代表着从数据集中学习到的不同知识,不同的初始化及监督策略对模型有着较为重要的影响。DistilBART-2模型的Rouge-2数值证明在调令解析数据集上,公式(6)映射后的解码器层包含着更多相关的知识。
2.3.4 解码器层隐含知识对实验结果的影响
为进一步验证公式(6)映射后的解码器层包含着更多调令解析相关的知识。本文参考sft算法[17],去掉了隐藏层监督,在初始化时选择不同解码器层进行复制后,在数据集上进行fine-tuning,此处选取的数据集同样是是PL-10数据集,模型初始化时分别选择sft算法的初始化策略(0、6、11解码器层)和公式(6)映射后的解码器层,实验结果如表4所示,其中DistilBART-xsum-12-3-sft 代表sft算法;DistilBART-xsum-12-3-sft mapping代表映射后的模型。
表 4 采用不同transformer层初始化对模型的影响模型名称 Rouge-2 DistilBART-xsum-12-3-sft 21.3454 DistilBART-xsum-12-3-sft-maping 21.5552 由表4所示,不同下游任务依赖于teacher模型中不同的解码器层,在调令解析任务中,公式(6)映射后的解码器层包含的知识更为重要,去掉隐藏层监督,选择映射后的解码器层初始化的模型在性能上甚至比采用了隐藏层监督但初始化时选择不同解码器层的DistilBART-0和DistilBART-1更高,这证明了本文提出的初始化策略可以有效提升模型在调令解析上的精度。
3 结束语
本文提出了一种基于生成式摘要模型和知识蒸馏算法的调令解析算法DistilBART模型。相较传统的正则匹配算法,本文提出的算法鲁棒性更高,在测试集上取得了更好的效果。同时,本文提出了新的损失函数、新的模型初始化及监督策略,相较BART-large模型,DistilBART模型在不损失太多精度的前提下,模型尺寸缩小了约37%,推理速度提升了约49%,为今后调令解析技术在铁路上的部署和落地提供了参考。
下一步,我们希望可通过模型轻量化策略优化模型中的编码器,在保留上下文语义信息的前提下缩减模型尺寸,削减解码器层数,提升模型推理速度,减少资源占用。同时进一步研究teacher模型中不同解码器层与调令解析任务的依赖关系,选择更好的映射函数,提升算法的解析精度。
-
表 1 本文模型与其他算法实验结果对比
模型名称 模型尺寸/Mbyte 推理时间/ms Rouge-2 正则匹配 20 10.1325 BART-large 1550 204 22.2897 DistilBART 973 103 21.6342  下载: 导出CSV
下载: 导出CSV
表 3 不同初始化及监督策略对模型的影响
模型名称 Rouge-2 DistilBART-0 21.4361 DistilBART-1 21.5549 DistilBART-2 21.6342
下载: 导出CSV
表 4 采用不同transformer层初始化对模型的影响
模型名称 Rouge-2 DistilBART-xsum-12-3-sft 21.3454 DistilBART-xsum-12-3-sft-maping 21.5552
下载: 导出CSV
-
[1] Liu Y, Lapata M. Text summarization with pretrained encoders[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, 3-7 November, 2019, Hong Kong, China. Hong Kong, China: Association for Computational Linguistics, 2019.
[2] Devlin J, Chang M W, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]//Proceedings of 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, June 2 - June 7, 2019, Minneapolis, Minnesota . Minneapolis, Minnesota: Association for Computational Linguistics, 2019: 4171-4186.
[3] Zhang X X, Wei F R, Zhou M. HIBERT: document level pre-training of hierarchical bidirectional transformers for document summarization[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, July 28 - August 2, 2019, Florence, Italy. Florence, Italy: Association for Computational Linguistics, 2019: 5059-5069.
[4] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]∥Proceedings of the 31st Conference on Neural Information Processing Systems, 4 December, 2017, Long Beach, USA. Morehouse Lane, Red Hook: Curran Associates Inc. , 2017: 5998-6008.
[5] 赵江江, 王 洋, 许楹楹, 等. 基于知识蒸馏的抽取式自动摘要模型[J/OL]. 计算机科学: 1-7[2022-09-07]. http://kns.cnki.net/kcms/detail/50.1075.TP.20220811.1545.004.html. [6] 魏鑫炀,唐向红. 基于BERT的抽取式裁判文书摘要生成方法研究 [J]. 软件工程,2022,25(5):1-4. DOI: 10.19644/j.cnki.issn2096-1472.2022.005.001 [7] Zhang J Q, Zhao Y, Saleh M, et al. PEGASUS: pre-training with extracted gap-sentences for abstractive summarization[C]//Proceedings of the 37th International Conference on Machine Learning, 13-18 July, 2020, 13-18 July. Vienna, Austria: PMLR, 2020: 11328-11339.
[8] Wang K, Quan X J, Wang R. BiSET: Bi-directional selective encoding with template for abstractive summarization[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, July 28 - August 2, 2019, Florence, Italy. Florence, Italy: Association for Computational Linguistics, 2019: 2153-2162.
[9] Raffel C, Shazeer N, Roberts A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer [J]. Journal of Machine Learning Research, 2020, 21(140): 1-67.
[10] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[EB/OL]. 2018.https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf.
[11] Peters M E, Neumann M, Iyyer M, et al. Deep contextualized word representations[C]//Proceedings of 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 1-6 June, 2018, New Orleans, Louisiana. New Orleans, Louisiana: Association for Computational Linguistics, 2018: 2227-2237.
[12] Lewis M, Liu Y H, Goyal N, et al. BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 5-10 July, 2020. Association for Computational Linguistics, 2020: 7871-7880.
[13] Furlanello T, Lipton Z, Tschannen M, et al. Born again neural networks[C]//Proceedings of the 35th International Conference on Machine Learning, 10-15 June, 2018, tockholm, Sweden. Stockholm, Sweden: PMLR, 2018: 1602-1611.
[14] Sanh V, Debut L, Chaumond J, et al. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter[EB/OL]. (2019-10-02).https://arxiv.org/pdf/1910.01108.pdf.
[15] Jiao X Q, Yin Y C, Shang L F, et al. TinyBERT: distilling Bert for natural language understanding[C]//Proceedings of Findings of the Association for Computational Linguistics: EMNLP 2020, 16-20 November, 2020. Association for Computational Linguistics, 2020: 4163-4174.
[16] Kim Y, Rush A M. Sequence-level knowledge distillation[C]//Proceedings of 2016 Conference on Empirical Methods in Natural Language Processing, , 1-5 November, 2016, Austin, Texas. Austin, Texas: Association for Computational Linguistics, 2016: 1317–1327.
[17] Shleifer S, Rush A M. Pre-trained summarization distillation[EB/OL]. (2020-10-24)[2022-09-07].https://arxiv.org/pdf/2010.13002v1.pdf.
-
期刊类型引用(2)
1. 游政,赵全赏,姚大鹏,费振豪. CTC/TDCS调度命令内容安全卡控技术研究. 铁道通信信号. 2024(04): 42-48 .  百度学术
百度学术
2. 孔庆玮,苗茁,冯小芳,杨国柱,龙勋. 基于知识图谱的高速铁路客运调度命令闭环管理方案研究. 铁道运输与经济. 2023(10): 89-98 . 百度学术
其他类型引用(0)
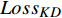
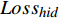
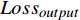
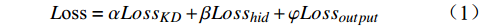
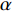
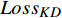
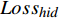
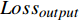
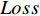
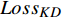
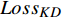
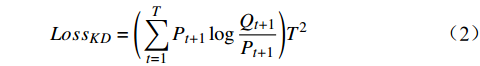
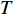
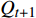
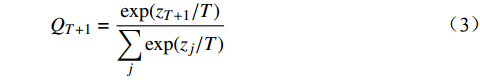

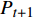
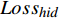
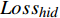
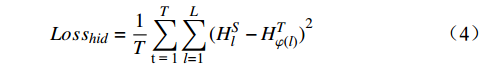
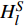
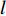
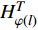
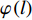
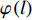
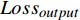
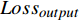
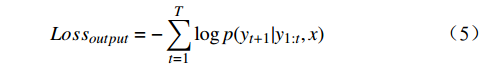
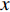
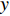

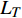
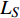
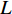
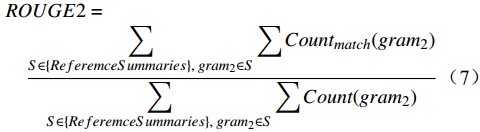
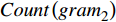
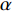
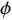
计量
- 文章访问数: 145
- HTML全文浏览量: 68
- PDF下载量: 35
- 被引次数: 2
