

Design and application of storage architecture of railway data service platform
-
摘要: 针对当前“数据沼泽”日益突出的问题,从铁路数据服务平台存储架构层面提出一种新的顶层设计。该设计包括存储组件分区管理模块、全链路存储组件监控模块、无感存储组件访问中间件模块3个部分。存储组件分区管理模块根据数据的数据类型、使用频度、应用场景等方面,灵活将数据存储在高性价比、高可靠的各个存储组件中;全链路存储组件监控模块提供数据全生命周期流转过程,实时监控各类数据在存储组件中的存储状况;无感存储组件访问中间件提供无感、跨组件的数据访问服务。并结合铁路数据服务平台应用实例,更直观地描述数据在平台中的存储、管理及访问,使得“数据沼泽”问题在铁路数据服务平台中得到解决。Abstract: The current "data swamp" problem has become increasingly prominent. This article combined the application of railway big data and proposed a new top-level design from the storage architecture of the railway data service platform. The design included three parts: storage component partition management module, full-link storage component monitoring module, and non-inductive storage component access middleware. The storage component partition management module flexibly stored the data in cost-effective and highly reliable storage components according to the data type, frequency of use, and application scenarios of the data. The full-link storage component monitoring module provided the data flow process throughout the life cycle, real-time monitoring of the storage status of various types of data in storage components. Non-sense storage component access middleware provided non-sense, cross-component data access services. Finally, combined with the application examples of the railway data service platform, the article made a more intuitive description of the data storage, management and access in the platform, so that the "data swamp" problem could be solved in the railway data service platform.
-
Keywords:
- railway big data /
- data service platform /
- data storage /
- data management /
- data access
-
随着中国高速铁路的飞速发展和铁路信息化建设逐步完善,中国铁路积累了大量与铁路相关的结构化、半结构化、非结构化数据[1]。对这些数据进行全面有效管理和深入分析挖掘,充分发挥数据的价值,对提高铁路运输生产效率、降低运输成本、提升客货运产品服务质量、提高运营管理水平等具有重要意义[2]。
铁路数据服务平台是大数据应用的基础和技术支撑,为大数据应用提供数据基础、存储、计算和分析等能力。铁路数据服务平台提供结构化数据与非结构化数据的接入能力,同时支持PB级离线数据的分析;在实时数据分析端,支持TB级数据的实时分析[3]。
存储作为大数据平台的重要组成部分,只有在合理而高效的大数据存储架构支撑下,才能对铁路行业的大数据进行快速存取、检索并提高整个系统的吞吐量,大数据及数据挖掘应用才可以开拓其核心价值。目前,Hadoop已成为大数据处理的标准,Hadoop处理数据的生态日渐丰富,它能够满足大数据的多种需求[4]。仅运用Hadoop作为数据存储组件,将海量铁路数据存入“数据湖”中,无法对这些数据进行管理监控,很容易形成“数据沼泽”[5],所以集合多种存储方式的存储架构才能适应当前数据存储的发展要求。如何将数据安全稳定的存储,如何对数据在存储过程中进行全链路监控管理,如何跨存储组件无感共享,都是数据储存架构需要考虑的问题。本文将结合铁路数据服务平台的实际应用,通过研究各个存储组件的使用场景及利弊,探索使用何种存储方式使得各种数据安全稳定的存储,从存储组件分区管理,全链路存储组件监控模块,无感存储组件访问中间件模块3个部分对铁路数据服务平台存储架构进行全面阐述。
1 存储架构整体设计
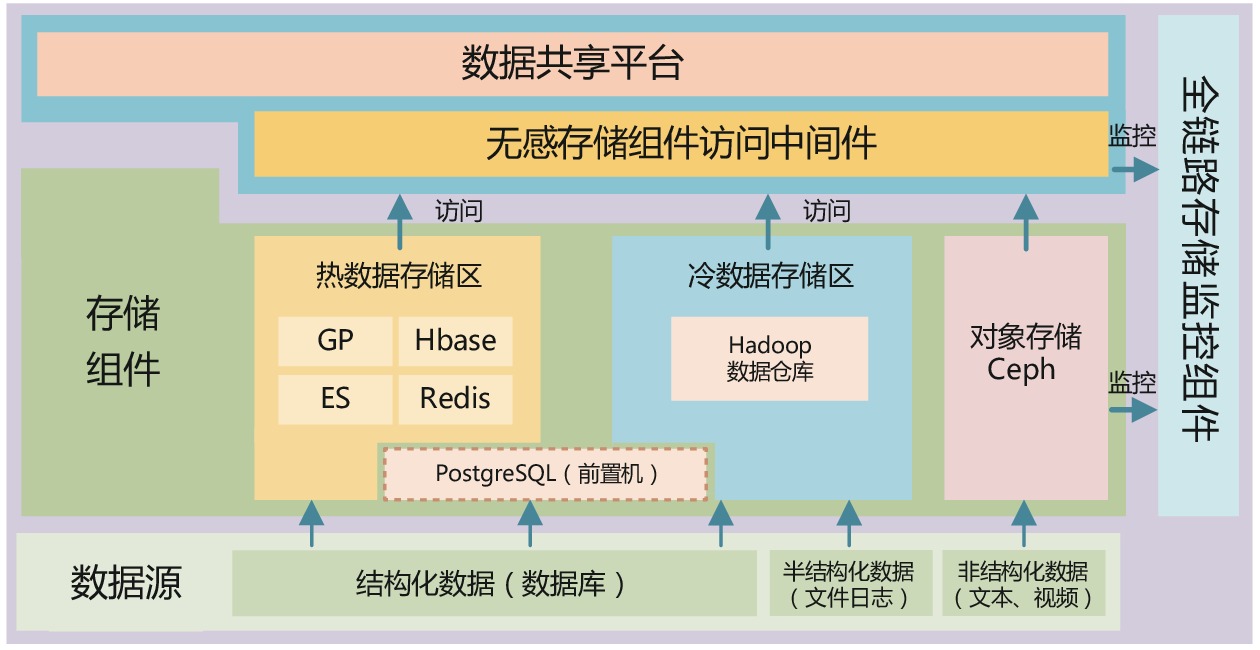
对海量多源异构数据进行高效处理是大数据平台核心能力之一[6]。由于计算需求的多样性,数据特征及计算性能要求差异性较大,铁路数据服务平台整合多种存储计算技术以满足需要。当前铁路数据服平台集成了PostgreSQL、Hive、Hbase、Green plum、Elasticsearch、Redis和Ceph等存储组件,不同业务、不同场景的数据采用不同的方式进行计算与存储。采用多种存储方式并存的形式,根据数据类型及数据处理的要求选择不同的数据存储方式。存储架构还包括全链路存储监控组件对平台存储组件进行监控,无感存储组件访问中间件模块提供数据访问服务。
铁路数据服务平台的存储架构,如图1所示。
2 平台存储组件分区管理
铁路数据服务平台要为铁路各类应用海量数据存储提供基础性支撑功能。根据不同业务不同场景的数据,提供多种数据存储,支持结构化数据、非结构化数据和半结构化数据等存储需求[7]。结合数据使用频度,业务使用场景,存储组件优缺点等方面,对数据进行分区存储。利用大数据的批量计算、内存计算等技术,结合各类业务逻辑和算法,实现海量数据的离线分析与处理功能[8]。
2.1 结构化数据存储
结构化数据通常采用传统数据仓库中关系型数据库存储,从数据处理维度看,对于业务处理层,鉴于其对事务完整性和高实时性的要求,可采用传统的高性能关系型数据库PostgreSQL作为数据服务平台的贴源层接收结构化数据。通过使用PostgreSQL作为贴源层,使得存储架构更加稳定。
针对不同的业务场景,数据也可按实际情况直接接入其它存储组件,铁路数据服务平台具备直接接入ES、Redis、Greenplum和Hbase等存储组件的能力,可结合业务场景将这些数据及时共享出去。
铁路数据服务平台根据数据的访问频次将数据分为冷、热数据存储区。热数据存储区主要存放近期使用频次较高的数据,冷数据存储区主要存放访问频次较低的历史数据。平台既支持数据在各自分区内根据业务场景进行数据迁移,也支持数据在冷热分区间跨区迁移查询。
由于某些业务场景的需要,平台同样适配数据直接接入Hadoop数据仓库。
2.2 半结构化数据存储
半结构化数据是结构化数据的一种形式,常见的半结构化数据有XML和JSON[9]。半结构化数据一般是结构化的数据,但它的结构变化较为突出。所以铁路数据服务平台通常将半结构化数据直接存储在Hadoop数据仓库中,利用Hadoop强大的文件处理能力灵活处理,发挥半结构化数据的特点,高效地对XML、JSON等日志文件等半结构化数据进行分析计算。
2.3 非结构化数据存储
非结构化数据是数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据[10]。铁路数据服务平台采用对象存储Ceph来存储非结构化数据。对象存储Ceph克服了读写速度慢、存储空间不足等的劣势,在海量存储图片、音视频、日志等文件的存储与内容分发网络和云端数据处理等方面展现出优势。数据服务平台通过使用对象存储Ceph,使其具有较强的横向拓展、动态伸缩、冗余容灾、负载平衡的能力,并通过相关技术实现了对接Hadoop生态搭建的大数据存储实现数据的无缝流转,为大数据分析共享提供了良好的数据衔接。用户可以通过页面上传或者接口上传非结构化数据。
3 全链路存储监控
3.1 存储监控原理
在大数据应用场景中,结合业务场景,运用多种存储组件的现象已经较为普遍,如果不能梳理清楚存储组件间数据流转过程,将会使数据服务平台数据杂乱无章,因此,建立全链路存储组件监控能够使得这一问题得到解决。
铁路数据服务平台全链路存储组件监控模块实现数据在平台内各存储组件间数据流转的监控及管理。监控模块可以对各个组件内的元数据自动化采集、探查、帮助绘制数据地图,标明数据关系,分析各存储组件内数据关系,管理模型变更。通过元数据管理,方便业务人员和技术人员快速定位数据来源,满足内部管理、审计或外部监管的需求,追溯业务指标、报表的数据来源和加工过程。
全链路存储组件监控模块提供跨工具和应用的企业级元数据统一视图,给出了盘点数据资源现状和分析跟踪数据流转的实际可行的解决方案。内置多种采集适配器,包括Oracle、Mysql、PostgreSQL、Hive和Hbase等,可快速对接各类元数据,建立统一、集中的元数据资源库,实现企业级元数据管理。
3.2 存储监控功能模块
(1)数据地图模块。提供跨工具和应用了解企业内系统以及系统之间数据流向关系,并支持从系统到数据库的钻取及相关表、字段信息的展示。
(2)全链分析模块。提供跨工具了解数据在系统中流动变化的全链分析,包括数据的上游链路来源情况和该数据影响的下游链路关联情况。
(3)血统分析模块。提供跨工具了解数据在系统中流动变化的。
(4)影响分析模块。提供跨工具追踪企业范围的数据变化影响;表关联程度分析,用于展现表在系统中的系统程度。
4 无感存储访问
4.1 无感存储访问组件原理
在一些实际业务场景中,包括存储结构化数据的PostgreSQL、GP、Hbase等,也包括存储非结构化数据的对象存储组件,每个组件对于数据读取方式不同、存储和读取的效率也存在很大差异,导致在进行数据访问时,不但需要了解数据存在哪个组件中,编写对应语法的查询语句,还需要考虑数据查询的实时性。为解决这一问题,铁路数据服务平台存储架构设计了无感存储组件访问中间件。
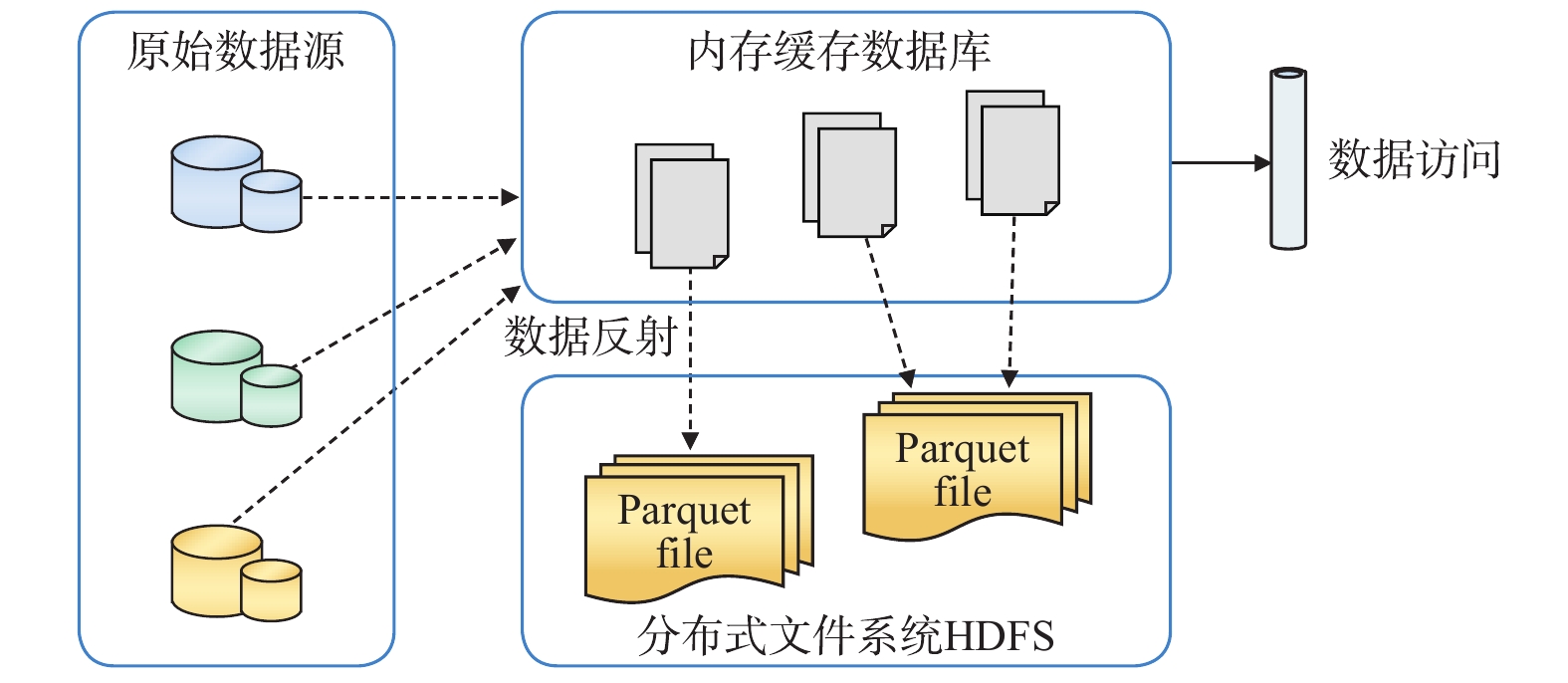
无感存储组件访问中间件,提供跨存储组件对数据进行查询并提供查询结果的能力,上层通过标准SQL进行封装并建立数据反射将批量处理的数据预先处理后存储到内存数据库中进行缓存,实现对大部分存储组件的调用,1 000万条数据查询时间为0.15 s,实现对存储组件的无感访问。无感存储访问组件原理,如图2所示。
4.2 无感存储访问组件特性
(1)跨数据环境的统一架构,支持多种数据源接入即用。
(2)数据虚拟化,用真实的数据,提供虚拟化视图。
(3)各类业务使用最合适的技术在原来的位置上独立处理数据,无论外部还是内部数据源。
(4)通用的统一访问接口,全量的数据检索。
(5)不搬移数据,处理链路短,支持实时业务响应。
铁路数据服务平台也支持直接连接存储组件的查询接口服务。提供多种方式的数据共享。
5 铁路数据服务平台应用实例
5.1 某铁路局集团公司安全大数据应用场景
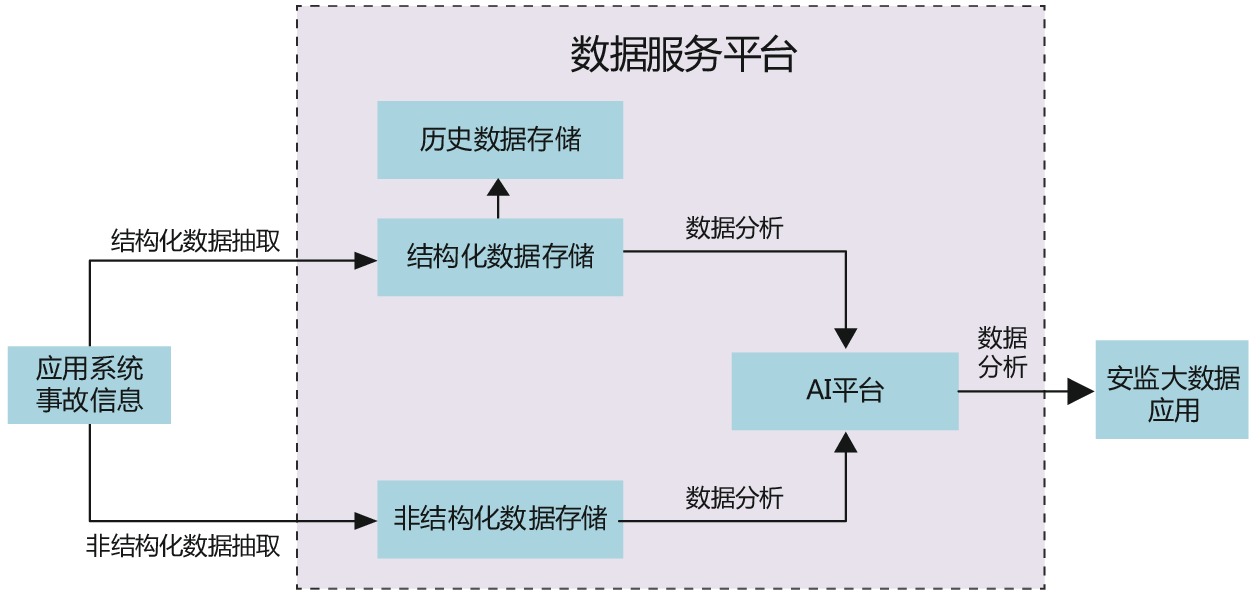
某铁路局集团公司安全大数据基于结构化数据与非结构化数据融合分析场景的实际应用,数据传输流程如图3所示。由于中国国家铁路集团有限公司(简称:国铁集团)安监局和铁路局集团公司安监室每日交班分析会对当日发生的事故进行汇总,而这些事故当前只有事故概况情况,尚无调查处理信息,从而无法对事故原因进行科学分析。
该应用运用大数据分析技术,通过对结构化的事故概况信息数据进行智能匹配,精准挖掘历史同类事故案例,为事故调查处理提供辅助参考。利用文本分析技术,对非结构化数据历史事故的调查报告进行格式化处理,对同类事故的原因进行挖掘分析,结合结构化的事故概况信息和非结构化的事故调查报告综合分析,从而精准地指导事故原因分析。
5.2 某铁路局集团公司安全大数据应用存储架构
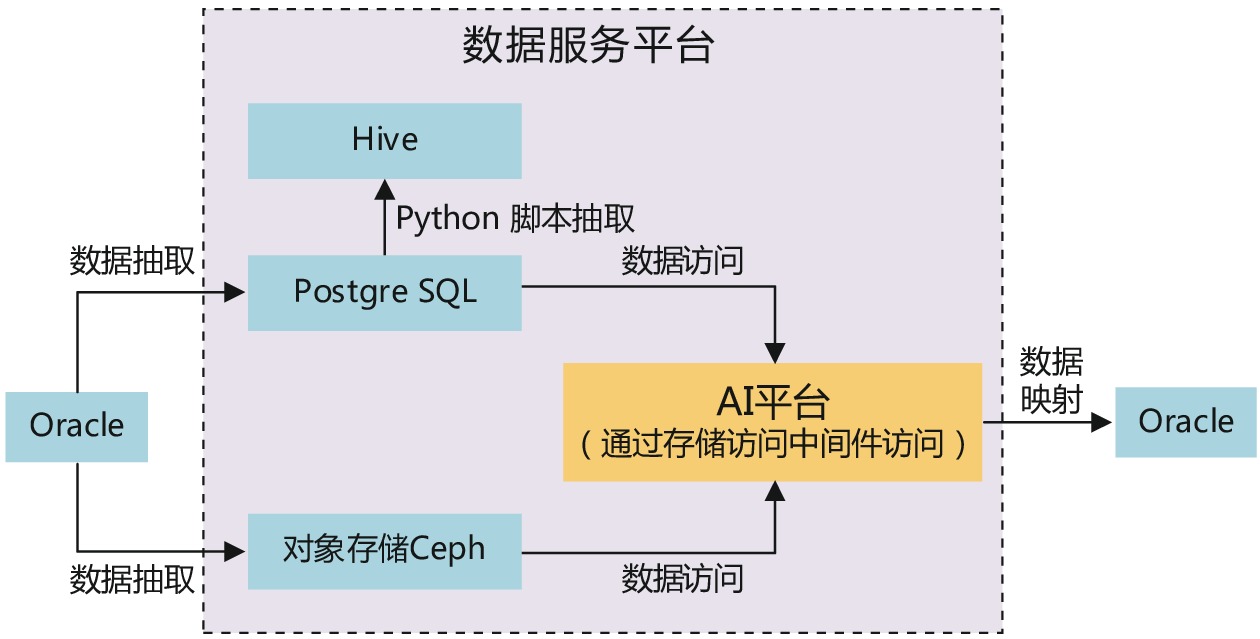
基于结构化数据与非结构化数据融合分析场景,该场景下的数据链路图,如图4所示。
(1)该存储架构将结构化数据通过接口方式抽取到前置机PostgreSQL数据库中,并在PostgreSQL数据库中对数据进行清洗加工,将完整可用的数据通过Python脚本抽取到Hive库中,这样可以将清洗后的历史数据全部存入冷数据区中。
(2)对象存储Ceph将非结构化数据抽取存储,AI平台通过存储访问中间件,借助中间件调度工具,根据日期和实际业务逻辑,实现结构化数据增量访问,从而保证数据的完整性。
(3)通过存储访问中间件从对象存储Ceph中对非结构化数据进行数据访问,结合结构化数据挖掘同类事故的原因。
(4)将分析结果数据同步到安全大数据平台的Oracle数据库中。
该场景铁路数据服务平台的存储组件分区管理,为安全大数据应用提供了多种存储方式,并将数据安全、可靠存储在各存储组件中;存储组件监控模块,实时监控各存储组件中的数据流转过程;无感存储组件访问中间件,为AI平台提供了跨结构化和非结构化的数据访问,从而提升安全大数据平台的分析能力。
6 结束语
铁路数据服务平台存储架构,通过丰富的存储组件满足各种存储需求,建立数据存储的冷热分区,保障数据安全可靠存储。该存储架构还设计了全链路数据存储监控组件和无感存储组件访问中间件,全链路数据存储监控组件,实时追踪数据在各存储组件间流转过程,从而达到对存储组件的监控管理;无感存储组件访问中间件,解决了不同组件,不同版本数据访问差异化的问题,为数据访问提供便捷服务。该存储架构的优势在某铁路局集团公司关于结构化与非结构化数据融合的安全大数据应用上得到充分展现。
当前,数据服务平台存储架构在数据存储安全管理方面仍有待改进,随着个人信息保护面临新威胁与新风险,在数据存储安全管理方面,应从存储架构层面设计相应的模块,对其进行管控,从而提高铁路数据服务平台的存储安全管理能力。
-
[1] 陈 润. 面向铁路运维的大数据流式处理技术的研究与应用[D]. 北京: 北京交通大学, 2017. [2] 武 威,马小宁,刘彦军,等. 铁路数据服务平台安全策略研究 [J]. 中国铁路,2019(8):63-68. [3] 苏尔慈,刘 敏,李 平,等. 基于铁路数据服务平台的铁路工务设备安全画像应用设计方案 [J]. 铁路计算机应用,2020,29(6):34-38. [4] 马小宁,李 平,史天运. 铁路大数据应用体系架构研究 [J]. 铁路计算机应用,2016,25(9):7-13. DOI: 10.3969/j.issn.1005-8451.2016.09.003 [5] 邱燕娜. 数据湖不能成为数据沼泽[N]. 中国计算机报, 2015-09-28(11). [6] Teradata US Inc. Optimization Of Database Queries With Multiple Heterogeneous Database Systems[J]. Information Technology Newsweekly, 2020 :1738.
[7] 何 遥,刘 维,程岳寅,等. 云时代的高清存储 [J]. 中国公共安全,2015(20):126-134. [8] 徐 砚,谷 鹏. 电力监控网大数据分析平台研究与设计 [J]. 通信技术,2018,51(8):1908-1913. DOI: 10.3969/j.issn.1002-0802.2018.08.026 [9] 陈真勇,徐州川,李清广,等. 一种新的智慧城市数据共享和融合框架−SCLDF [J]. 计算机研究与发展,2014,51(2):290-301. [10] 程 平,杜 姗. 基于数据仓库的行政事业单位采购管理内部控制评价−以重庆海事局为例 [J]. 财会月刊,2019(17):53-57. -
期刊类型引用(6)
1. 李国华,邹丹,李海军,孙思齐,王建强. 铁路数据分布式湖仓一体架构分析与设计. 现代信息科技. 2024(01): 54-58 .  百度学术
百度学术
2. 位志强. 关于铁路综合视频监控系统存储服务的研究. 现代信息科技. 2024(05): 154-157 . 百度学术
3. 刘朝晖. 数仓平台在重载铁路监测系统中的应用. 智慧轨道交通. 2023(02): 65-71 . 百度学术
4. 许丹亚,欧阳慎,齐晨虹,朱志,尹文志. 基于大数据技术的铁路工务检测数据平台方案研究. 电脑知识与技术. 2023(13): 76-78 . 百度学术
5. 廉小亲,杨凯,程智博,王万齐,吴艳华. 面向建设期铁路大数据的分级存储方法研究. 铁路计算机应用. 2022(02): 17-22 . 本站查看
6. 刘强. 一种工业互联网云平台交互搭建方式. 信息技术与信息化. 2021(09): 124-126 . 百度学术
其他类型引用(0)
 下载:
下载:
计量
- 文章访问数: 268
- HTML全文浏览量: 352
- PDF下载量: 74
- 被引次数: 6
