

Design of railway passenger lost item management system based on Chinese-CLIP and DeepSeek
-
摘要:
针对铁路旅客遗失物品管理业务效率低、人工匹配查找工作量繁重等问题,文章设计了基于 Chinese-CLIP+DeepSeek的铁路旅客遗失物品管理系统,借助 Chinese-CLIP模型的跨模态表示学习能力,对遗失物品图像和文本描述进行联合表征,实现跨模态语义对齐;同时结合 DeepSeek 大语言模型的自然语言理解能力,构建智能客服机器人,优化旅客遗失物品申报和查询的人机交互,支持上传遗失物品图像,提高物品信息采集的准确性、完整性和规范性,并基于多模态融合与向量检索的遗失物品匹配技术,实现跨模态高效匹配。该系统为铁路旅客遗失物品管理提供了智能化解决方案,也为 人工智能(AI,Artificial Intelligence)技术在铁路行业应用实践提供了参考。
-
关键词:
- 铁路旅客遗失物品管理 /
- 图文检索 /
- Chinese-CLIP /
- 客服机器人 /
- 自然语言处理 /
- DeepSeek
Abstract:Aiming at low efficiency of railway passenger lost item management and heavy workload of manual matching and retrieval, this paper designs a railway passenger lost item management system based on Chinese-CLIP model and DeepSeek model. By leveraging the cross-modal representation and learning ability of the Chinese-CLIP model, the system jointly represents the images and text descriptions of lost items to achieve cross-modal semantic alignment. At the same time, it combines the natural language understanding ability of the large language model DeepSeek to build an intelligent customer service robot, optimizing the human-computer interaction for passengers to report and query lost items, supporting the upload of lost item images so as to improve the accuracy, completeness, and standardization of item information collection. Based on the multi-modal fusion and vector retrieval technology for lost item matching, it realizes efficient cross-modal matching. This system provides an intelligent solution for railwaypassenger lost item management and also offers a reference for the application of AI technologies in railway.
-
铁路旅客遗失物品管理业务是铁路客运服务的重要组成部分,提供旅客遗失物品登记与查询、拾得物品登记与保管、物品匹配与通知、认领与核销等服务,关系到旅客的财产安全和出行体验。随着我国“八纵八横”高铁网络的全面建成和城际铁路的快速发展,铁路客运量呈现持续增长态势。2024年全国铁路旅客发送量高达40亿人次,日均客流量突破
2000 万人次,车站和列车上的遗失物品管理面临巨大挑战。以上海虹桥站为例,作为亚洲最繁忙的高速铁路(简称:高铁)枢纽,月均遗失物品受理量逾万件。当前铁路旅客遗失物品管理业务存在以下主要问题:(1)拾得物品登记主要依赖人工,旅客服务人员在描述遗失物品特征时存在较大主观性,特别是对无文字标识物品的文字描述往往不够准确和全面,拾得物品登记时可能遗漏细节,加之缺乏统一的录入标准和规范化流程,不同站点、不同人员采用的描述方式和用语存在差异,导致拾得物品登记信息质量参差不齐,影响后续物品自动检索匹配的效果;(2)在旅客遗失物品申报和查询服务体验方面,现有系统提供的电话和表单查询方式交互性较差,旅客描述物品特征可能模糊(如简单描述为“黑色背包”),难以完整、准确地描述物品特征,导致信息收集不全,遗失物品匹配查询效率低下,用户体验不佳;(3)现有系统的检索匹配功能的智能化程度不够高,仅支持关键词匹配,无法有效处理包含多个特征的复合查询(如“带金色拉链的黑色皮质钱包”),对近义词、同义词和模糊表述的识别能力较弱,当旅客未能准确描述遗失物品特征时,系统无法完成遗失物品的自动检索匹配,导致旅客服务人员需要投入大量时间进行人工比对和处理,尤其在春运等客流高峰时段容易造成服务响应延迟,影响旅客满意度。
当前,人工智能技术在多模态模型和大语言模型(LLM,Large Language Model)方面取得重大突破,正加速推动社会智能化转型。多模态模型通过海量多模态数据训练,能有效处理图像、文本、语音等不同形式的数据,实现跨模态检索、内容生成等复杂功能。以Chinese-CLIP为代表的中文多模态模型,在图文特征计算、图文检索等任务中表现出色。大语言模型具有强大的自然语言处理能力,不仅能理解隐喻、上下文等复杂语义,还可用于内容创作、数据分析等场景,正在被广泛地应用于智能客服、在线教育等领域,通过模拟人类对话方式提升交互体验。我国自主研发的DeepSeek大模型凭借创新架构和高效性能,已在政务、医疗、通信等多个关键领域实现规模化应用,展现出良好的产业化前景。
本文尝试在铁路旅客遗失物品管理系统中应用Chinese-CLIP多模态模型和DeepSeek大语言模型,通过构建智能客服机器人,以自然语言交互方式实现旅客遗失物品登记与查询,实现物品特征智能识别和图文信息匹配,提升旅客遗失物品管理业务的效率与质量,有效地改善旅客服务。
1 系统架构设计
1.1 设计目标
(1)提升信息采集的准确性、完整性和规范性
针对当前旅客遗失物品人工登记过程中容易出现特征遗漏和表述偏差的问题,重点完善和优化遗失物品信息采集。通过集成DeepSeek大语言模型,以自然语言方式引导旅客在多轮对话中完成遗失物品申报和查询,确保遗失物品信息采集的准确性、完整性和规范性,支持上传遗失物品图像,并利用Chinese-CLIP模型自动提取视觉特征[1],为物品匹配检索提供更为丰富的特征数据。
(2)增强复杂特征检索能力
利用Chinese-CLIP的跨模态语义理解能力,对该模型进行微调,增强其对铁路旅客遗失物品匹配查询任务的适配性;并结合多模态特征融合与向量检索技术,在旅客遗失物品申报与查询时提供纯文本、纯图像及图文混合检索功能,以增强系统对复杂特征的检索能力。
(3)改善用户体验和提升业务效率
通过集成DeepSeek大语言模型,智能客服机器人与旅客以自然语言进行交互,在引导多轮对话的过程中,主动补全查询条件[2],减轻旅客在遗失物品申报与查询时准确描述物品特征的表达困难,并支持以图查物,显著改善旅客服务体验。
(4)提升业务效率和客运服务水平
为旅客服务人员提供物品自动匹配和智能审核辅助功能,减少人工对比查找的工作负担,通过提供业务数据分析,辅助客服管理人员优化车站资源配置和旅客服务,不断提升客运服务水平。
1.2 技术架构
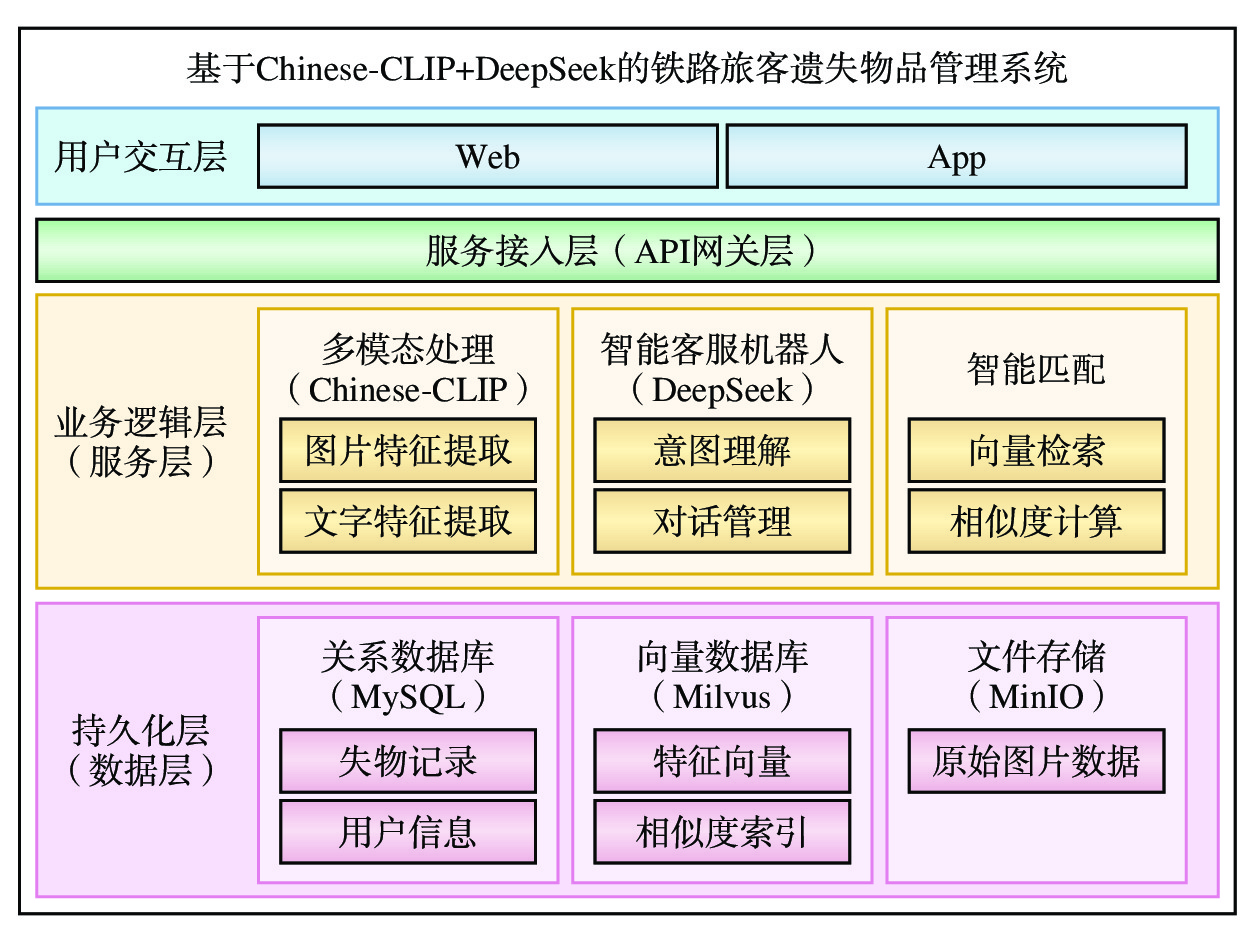
本系统采用分层架构设计,基于Chinese-CLIP多模态模型和DeepSeek大语言模型相结合的技术栈,针对铁路旅客遗失物品管理业务需求进行定制化开发,其架构如图1所示。系统自上而下分为用户交互层、服务接入层、业务逻辑层和持久化层,各层协同工作实现铁路旅客遗失物品全生命周期管理。
(1)用户交互层:提供Web端和智能手机App应用,为旅客、服务人员及管理人员提供优质的交互服务。
(2)服务接入层:采用Flask框架[3]处理HTTP请求和响应,实现身份验证、请求路由和负载均衡等功能。
(3)业务逻辑层:采用Chinese-CLIP模型构建多模态处理服务,基于DeepSeek大模型实现智能客服机器人,通过向量检索与相似度计算完成智能匹配,处理铁路旅客遗失物品管理业务流程和规则。
(4)持久化层:使用关系型数据库MySQL存储遗失物品记录、用户信息等数据;借助向量数据库Milvus管理特征向量,支持高效相似度搜索[4];使用开源的对象存储系统MinIO保存图像数据。
2 功能设计
系统用户主要包括系统管理员、旅客服务人员和旅客等3类,提供系统配置管理、遗失物品申报与查询、拾得物品管理、遗失物品招领与视频追溯、物品认领与核销、平台服务和数据分析等功能。
2.1 系统配置管理
系统管理员按照铁路旅客遗失物品管理业务要求,完成旅客服务人员管理、基础数据字典维护、业务参数配置和模型参数设置,使系统应用能够灵活适应实际业务管理需要。
(1)旅客服务人员管理:根据客服管理工作安排,系统管理员完成旅客服务人员基本信息录入,并分配遗失物品业务处理权限,如遗失物品登记、遗失物品匹配确认、遗失物品视频追溯等;管理旅客服务人员账号状态(启用/禁用),当人员离职或调岗时及时取消权限。
(2)基础数据字典维护:系统管理员维护系统运行所需的基础数据字典,包括物品类型字典(如电子产品、证件、箱包、衣物、食品、贵重物品等)、物品状态字典(已登记、匹配中、已匹配、确认匹配、待认领、已认领、已失效等)、招领点字典(即设置各车站或区域的遗失物品招领处的具体位置信息)、处置方式字典(销毁、捐赠、移交公安等,定义超过保存期限物品的标准化处理方式)。
(3)业务参数配置:系统管理员根据铁路运营的实际需求,完成相关参数的设置;短信、App 消息推送、邮件等通知渠道的开启或关闭,并设置通知频率,如在节假日高峰期提高通知频率,确保旅客能及时获取遗失物品相关信息;设置不同价值物品的保存期限,例如高价值物品保存60天,普通物品保存30天;设置最大预约次数,对预约次数进行限制,以平衡资源分配。
(4)模型参数设置:调整Chinese-CLIP 图文特征相似度阈值,直接影响系统自动匹配旅客申报的遗失物品与旅客服务人员登记拾得物品的相似性;阈值越高,匹配越严格,漏匹配的情况会增多。
2.2 遗失物品申报与查询
旅客可通过自助申报和智能申报2种方式,在系统中申报遗失物品信息,形成完整申报记录,查询业务受理进度,系统自动推送业务受理动态通知,实现高效透明的遗失物品申报管理流程。
(1)申报注册:旅客通过移动端App或者网站进入遗失物品申报注册界面,填写姓名、身份证号、联系方式、乘车日期、车次、车厢座位号、遗失时间等信息,系统通过客票信息数据接口,查询旅客对应的乘车记录,完成旅客身份信息确认。
(2)自助申报:旅客完成身份信息确认后,在自助申报页面选择物品类型,填写物品详细描述,如物品类型、颜色、尺寸、品牌型号等,还可上传遗失物品的照片或视频。
(3)智能申报:系统构建智能申报机器人,以友好的对话方式引导旅客提供关于遗失物品的关键信息,如“您好,请问您丢失了什么物品呢?”“请问您是在什么时间、什么地点丢失的呢?”“丢失的物品有什么特征,比如颜色、形状、品牌等?”;在获取关键信息后,向旅客确认信息的准确性,如“您看我理解得对不对,您是在{具体时间},在{具体地点}丢失了一个{物品特征}的{物品名称},是吗?”;当旅客确认信息无误后,告知旅客申报已完成,并提供相关的查询方式或后续处理流程,如“好的,您的遗失物品申报已成功提交。我们会尽快帮您寻找,您可以通过进度查询链接查询遗失物品的寻找进度。”
(4)申报记录生成:旅客完成申报后,系统自动生成受理编号,并将旅客通过自助申报填报的所有结构化信息或智能申报过程中最终确认的关键信息,连同申报注册环节已验证的旅客身份信息进行整合,生成结构化的遗失物品申报记录,存储在核心业务数据库的遗失物品申报表中。
(5)受理通知:在旅客完成遗失物品申报后,系统自动生成申报受理通知,并通过短信、邮件、系统消息推送等方式发送给旅客,告知其申报已成功受理及相关受理编号。
(6)进度查询: 旅客可通过移动端App或Web端查询遗失物品申报进度,实时显示“已受理、查找中、已找到”等处理状态及具体时间节点。
2.3 拾得物品管理
旅客服务人员在登记拾得物品信息时,系统能自动提取物品图像中的特征信息,并登记的拾得物品特征信息将与旅客申报的遗失物品信息进行匹配,匹配结果由旅客服务人员进行确认。
(1)拾得物品登记:旅客服务人员在接收到拾得物品后,填写拾得物品信息,包括接收时间、接收站点、接收人员姓名、物品编号、物品类型、品牌型号、颜色尺寸、物品状态、存放位置、编码等详细信息,从多个角度拍摄物品的照片并上传。
(2)拾得物品特征提取:系统使用Chinese-CLIP多模态预训练模型,对旅客服务人员上传的物品图像进行细粒度特征提取,通过深度学习算法解析物品的几何形状、主色调分布、材质纹理等视觉特征,生成高维特征向量,并存储在遗失物品特征向量数据库中。
(3)物品存储管理:对实物进行分类存放(如行李、证件、电子产品等),记录存储位置(如货架编号、储物柜号),支持扫码或 RFID 快速定位。
(4)遗失物品智能匹配:系统提取旅客申报的遗失物品特征信息和已登记的拾得物品特征信息,计算两者之间的相似度,自动完成匹配,包括文−图匹配、图−图匹配和图文结合匹配。
(5)遗失物品匹配确认:当完成系统遗失物品智能匹配后,由旅客服务人员进行匹配结果确认,对比申报信息和遗失物品登记信息的详细内容,包括物品特征、遗失时间、地点等关键要素,结合实际情况判断匹配结果是否准确;若确认匹配成功,则更新物品状态为 “已匹配”;若旅客服务人员认为匹配错误,可重新将物品状态标记为 “匹配中”,并填写原因,以便后续进一步处理遗失物品,以及用于优化匹配算法。
(6)物品状态跟踪:实时更新物品状态(待认领、已认领、过期处理等),自动提醒工作人员定期清理无人认领物品。
2.4 遗失物品招领与视频追溯
系统为旅客提供移动端App和Web端的遗失物品招领功能,可分类展示各站点拾得的旅客遗失物品信息,方便旅客主动查找遗失物品,并为旅客提供高价值遗失物品视频追溯服务,进一步提升旅客服务水平。
(1)遗失物品招领展示:系统将各站点登记的拾得物品按照物品类型、遗失站点、遗失时间等不同维度,在招领平台上进行分类展示。
(2)遗失物品招领浏览:旅客在招领平台上浏览查找遗失物品,当查找到疑似自己遗失物品后,可进行认领预约。
(3)遗失物品智能查询:系统构建智能客服机器人,当旅客与其进行交互时,智能客服机器人可识别其遗失物品查询意图,引导对话形成完整的查询条件,执行遗失物品查询匹配任务并将结果反馈给旅客。
(4)遗失物品视频追溯:系统通过与车站视频综合监控系统的接口,获取旅客高价值物品疑似遗失地点的监控视频数据,运用视频目标检测分析技术,结合旅客申报的遗失时间、地点等信息,自动筛选相关时间段的监控视频进行分析,通过对视频画面中人员、物品移动轨迹的识别和跟踪,辅助追溯物品的轨迹,判断物品是否被他人拾取、移动方向等情况。
2.5 物品认领与核销
对于已确认匹配的遗失物品,系统通知旅客认领,旅客预约认领时间,去往指定站点完成认领。
(1)认领通知:当旅客服务人员完成遗失物品匹配确认后,系统自动生成认领通知,并通过短信、App 推送、邮件等多种渠道发送给旅客;通知信息包含乘客及遗失物品基本信息、认领时间、地点、需携带的证件等内容,确保旅客清晰了解认领流程和要求。
(2)认领预约:旅客在收到认领通知后,可通过手机App 或登录客服网站线上预约认领时间,并填写预约相关信息;旅客可在规定的次数或时间范围内,对已预约的时间进行再次修改或取消预约。
(3)签领登记:旅客按照预约时间前往指定站点进行遗失物品认领时,旅客服务人员首先对照系统核对旅客的身份信息,确保认领人是失主本人或经授权的代理人,旅客检车物品,确认无误后,旅客或旅客服务人员在系统中完成签收操作,系统更新物品状态为 “已认领”;旅客服务人员记录认领相关信息,如认领时间、签收人等。
(4)核销记录:旅客认领完成后,系统记录核销时间、经手人,并生成电子凭证,如认领回执单,供后续查询。
(5)逾期提醒:对超过保管期限(如设置为 90 天)的物品,提前通知旅客,逾期未认领则按规定移交相关部门(如公安机关)或进行无害化处理。
2.6 数据分析
通过数据分析,掌握旅客遗失物品规律,辅助旅客服务管理人员改善内部管理,提升旅客服务。
(1)高频遗失物品分析:基于 DeepSeek大模型生成高频热力图,对大量的遗失物品数据(包括遗失站点、遗失时间、物品类型等)进行分析,计算各要素在不同区域或时间段的出现频率,直观展示遗失物品分布特征,统计各站点遗失物品的数量,生成以铁路站点为坐标的热力图,帮助客服管理人员快速了解遗失物品的高发区域和时间段,为加强重点区域和时段的管理、优化服务资源配置提供数据依据,如在高发站点增加遗失物品宣传提示、加强巡查等。
(2)遗失物品关联分析:利用关联规则算法,结合旅客信息、乘车信息、遗失物品信息等多维度数据进行综合分析,例如分析不同年龄段、性别旅客的遗失物品类型偏好,发现年轻旅客更易遗失电子设备,老年旅客更易遗失证件;分析遗失物品种类与乘车时间段,统计各类遗失物品高发的乘车时段,发现旅客遗失物品的规律和特点,为制定针对性的预防措施和服务策略提供可靠依据,如在特定时间段加强车厢广播提醒,向不同旅客群体主动推送遗失物品预防提醒等。
2.7 平台服务
系统通过基于标准化协议和加密机制的接口服务,实现与相关系统的安全对接,为旅客提供信息核验、遗失物品追溯和消息推送等功能;提供较为完善的日志管理,支持安全审计与异常分析,确保系统运行安全可靠、异常情况可追溯。
(1)接口服务:通过标准化的接口协议,实现与其它相关系统的互联互通,例如与铁路票务系统对接,获取旅客的乘车信息,辅助验证旅客身份和遗失物品申报信息的真实性;与车站视频综合监控系统对接,实现高价值遗失物品视频追溯功能;与短信或邮件发送平台对接,完成各类通知的推送;接口服务采用安全可靠的加密传输和认证机制,构建安全可信的数据交互通道。
(2)日志管理:完整记录用户操作,提供日志查询和汇总统计,为安全审计、系统故障排查、安全防护、用户行为分析提供数据支持;支持日志数据进行定期清理和备份。
3 关键技术
3.1 面向铁路旅客遗失物品检索的Chinese-CLIP模型微调
Chinese-CLIP是面向中文的跨模态学习模型,通过对比学习实现图像与特征描述文本的语义对齐。该模型采用视觉编码器+文本编码器双塔架构;其中,视觉编码器基于ViT(Vision Transformer)提取图像特征,文本编码器使用RoBERTa处理中文描述,经归一化后图像与文本向量的余弦相似度来衡量语义关联强度,从而建立图像和特征描述文本之间的关联,实现图文匹配检索。
采用Chinese-CLIP模型匹配旅客遗失物品的特征描述本文和遗失物品图像,可自动实现遗失物品的快速匹配查找。由于该模型是在通用数据集(如MUGE、Flickr30K-CN等数据集)上进行预训练生成的,其参数在铁路旅客遗失物品场景下并非最优,需要结合铁路相关遗失物品数据对预训练模型进行微调,以提升模型在旅客遗遗失物品匹配查找业务上的适用性和准确性。
(1)数据集
本文共收集过往的
15000 张铁路旅客遗失物品图像,以及10000 份关于遗失物品的特征描述文本,部分特征描述文本对应多张相似图像,将数据集按8∶1∶1划分为训练集、验证集、测试集,将特征描述文本与相应的遗失物品图像作为模型的输入,例如特征描述文本“一个黄色的卡套上面有个狗狗图案”,所对应的图像如图2所示。为便于将特征描述文本与相应的遗失物品图像作为模型的输入,将图文对数据集预处理成lmdb数据格式进行读取。(2)模型微调与参数选择
结合预处理的遗失物品图文对数据集,对Chinese-CLIP预训练模型进行微调。Chinese-CLIP预训练模型采用模块化设计,将模型结构与预训练权重文件解耦,以增加模型微调的灵活性。其中模型结构文件(通常为.py或.yaml格式)明确定义了神经网络架构(包括视觉编码器的ViT-B/16结构和文本编码器的Transformer配置),以及文本分词器(Tokenizer)等核心组件的参数配置。权重文件(clip_cn_vit-b-16.pt)主要存储通过大规模中文图文数据集训练得到的模型参数权重,包括视觉编码器与文本编码器的联合参数,以及跨模态特征空间的投影矩阵权重。
微调是基于预训练的多模态基础模型,通过特定领域的图文对齐数据,以有监督学习方式调整模型参数的过程;其核心是通过特定应用领域的适应性训练,优化视觉编码器(ViT/CNN)与文本编码器(Transformer)的跨模态表征能力,以及特征空间的投影矩阵,以提升多模态模型在特定领域内图文检索等任务的性能。
微调策略主要有全参数微调(Full-tuning)和参数高效微调(如LoRA、Adapter)。鉴于本文数据集规模较小,选择参数高效微调方式[5],论文采用大规模中文图文对数据训练生成的Chinese-CLIP作为预训练模型,模型微调分2阶段进行。第1阶段冻结预训练好的视觉编码器,专注于优化文本编码器,使其更适应铁路旅客遗失物品描述文本的特征提取;第2阶段解冻视觉编码器进行联合微调,让模型同步学习视觉特征和图文对齐能力,通过对比学习优化跨模态嵌入空间。这种渐进式的两阶段训练既能避免双编码器同时调整带来的训练不稳定,又能逐步增强模型对铁路旅客遗失物品匹配场景下中文图文对的理解与匹配能力,以提升模型在图文检索、跨模态推理等任务中的表现。
模型微调训练的实验环境配置如表1所示。微调过程中所使用的超参数设置如表2所示;将batch size设置为64,learing rate初始值设为
0.0001 , warm up设为5进行训练预热,使模型逐渐适应训练过程。训练迭代次数epoch设为50,采用early stop策略进行最佳训练模型权重的保存。为了防止模型训练过程中的过拟合,将权重衰减参数weight delay设置为0.001。考虑到数据集规模较小,预训练过程中视觉编码模型选用Vit-B/16,文本编码模型选用RoBERTa-wwm-Base,文本句子长度设置为52。表 1 实验环境配置配置 版本及参数 主机CPU 12th Gen Intel(R) Core(TM) i5-12400 2.50 GHz 内存 8 GB 显卡 NVIDIA GeForce RTX 4070 编程语言 Python 3.9 深度学习框架 Pytorch 2.0 表 2 Chinese-CLIP预训练模型微调的超参数设置超参数 取值 Batch size 64 Learning Rate 0.00001 Epoch 50 Optimizer Adam Weight delay 0.001 Warm up 5 Vision-model ViT-B/16 Text-model RoBERTa-wwm-Base Context length 52 (3)效果评价
为评价微调后模型的性能,本文采用跨模态检索标准评价指标,包括首位命中率Recall@1、前五命中率Recall@5、前十命中率Recall@10以及综合平均召回率MeanRecall。Recall@K(K=1,5,10)为查询结果中真实结果(Groundtruth)排序在前K的比率,计算公式为
Recall@K=MatchedTop−KGroundtruthTotal (1) 其中,GroundTruthTotal表示真实匹配结果出现的总次数, MatchedTop-K表示在排序前K个输出结果中出现匹配样本的次数。
MeanRecall表示Recall@1、Recall@5、Recall@10的平均值,用于综合评估模型在不同检索深度下的整体召回性能,一般作为图文检索模型的主要评价指标,计算公式为
MeanRecall=(Recall@1+Recall@5+Recall@10)/3 (2) 对Chinese-CLIP预训练模型进行微调前后的性能指标如表3所示。
表 3 Chinese-CLIP预训练模型微调前后性能指标对比Recall@1 Recall@5 Recall@10 MeanRecall 微调前 26.91 46.86 51.76 41.84 微调后 32.08 59.44 68.99 53.51 由表3可知,利用铁路旅客遗失物品数据集对Chinese-CLIP预训练模型微调后,相比于初始的Chinese-CLIP预训练模型,在以遗失物品描述文本检索相关图像的任务中,综合平均召回率超过50%,提升11.67%,表明模型微调增强了Chinese-CLIP预训练模型对铁路旅客遗失物品相关图文数据集的特征提取能力,提升了遗失物品检索的准确率。
3.2 基于DeepSeek-R1构建智能客服机器人
DeepSeek是通用大语言模型系列,其中DeepSeek-R1是专注于推理的聊天模型。它通过强化学习实现专业领域推理突破,在多轮对话、逻辑推理、代码生成等场景表现亮眼,能像人类思考般理解复杂查询,给出精准且有条理的回答。在铁路旅客遗失物品申报和查询服务场景中,传统表单申报和简单关键词匹配方式存在信息收集不全、交互效率低、旅客体验不佳等问题。为解决这些痛点,本文利用 DeepSeek-R1大语言模型在自然语言理解与对话交互方面的优势,构建智能客服机器人,以深度理解旅客意图,通过自然流畅的多轮对话引导旅客准确、完整地描述遗失物品主要特征,进而提升遗失物品匹配查找的准确性和效率,优化人机交互体验与服务质量[6]。
智能客服机器人的核心能力包括:构建智能客服对话状态跟踪机制,实现对话流程状态管理;通过多轮对话精准理解旅客,并填充关键信息意图−槽位。
(1)对话流程状态管理
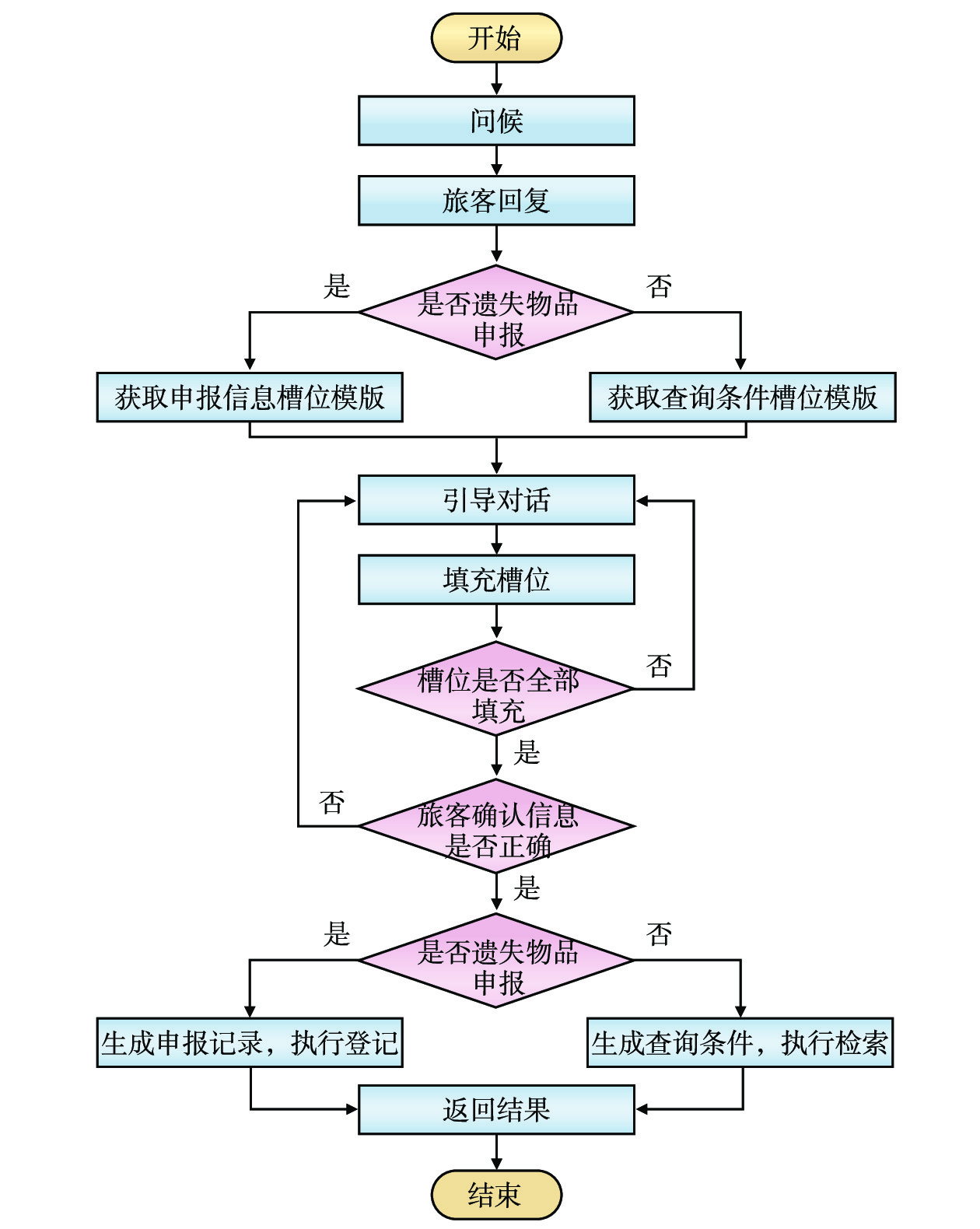
构建智能客服对话状态跟踪机制,智能客服机器人能够实现对话流程状态管理,按照“问候−>意图识别−>槽位填充−>信息确认−>执行操作−>结束”的基本流程如图3所示,根据当前对话状态和旅客输入信息,智能地决策下一步交互内容,确保对话过程逻辑清晰、目标明确。
通过预设的问候对话,智能客服机器人可识别旅客的交互意图。对于遗失物品申报,智能客服机器人获取到申报信息槽位模板,不断引导对话,直至完成申报信息全部槽位的填充,并让旅客确认信息是否正确,确认正确即生成完整申报记录并登记入库;对于遗失物品查询,智能客服机器人获取到查询条件槽位模板,在引导对话的过程中,完成所有槽位填充以及旅客确认,确认正确即生成完整的查询条件,在拾得物品特征库中进行匹配检索,并将匹配结果以自然语言形式反馈给旅客。当旅客确认信息存在疏漏或错误时,将再度进行对话引导与槽位填充。
(2)多轮对话理解和意图−槽位数据记录生成
基于DeepSeek-R1大模型强大的上下文理解与语义解析能力,智能客服机器人能够理解理解多轮对话中旅客提交的问答文本,生成结构化的旅客遗失物品申报和遗失物品查询记录,即意图−槽位数据记录[7],具体示例如表4所示。
表 4 意图−槽位数据记录示例意图 槽位列表 对话阶段 物品申报 名称 值 状态 信息确认完成 丢失时间 ****年**月**日 已填充 车次/地点 ***次列车***号车厢 已填充 物品类别 钱包 已填充 颜色 黑色 已填充 材质 皮质 已填充 特征 带金色扣子 已填充 内含物 身份证 已填充 当旅客输入交互语句,如“我钱包丢了”,智能客服机器人首先识别核心意图,并激活预设的对话流程模板。针对物品申报意图,机器人通过多轮问答,如“请问您是在什么时间、哪趟列车/车站丢失的呢?”“丢失的钱包是什么颜色、材质,有什么显著特征吗?”,主动引导旅客提供关键信息。在此过程中,DeepSeek-R1大模型实时解析旅客回复,精准填充“丢失时间”“车次/地点”“物品类别”“颜色”“品牌/特征”等预定义的槽位;最后,基于所记录的意图-槽位信息,智能客服机器人动态生成理解旅客全部申报或查询要求的确认询问文本,如“您确认是****年**月**日在***次列车的***号车厢,丢失了一个黑色皮质、带金色扣子的钱包,内含身份证,对吗?”,以确保所记录的意图−槽位信息的准确性与完整性。
通过识别意图和填充槽位,智能客服机器人可将旅客以自然语言表述的申报和查询内容转化为结构化数据,明确用户“想做什么”和“需要什么信息”,这种人机交互方式克服了传统的遗失物品表单填报和固定可选查询选项存在的描述信息项固定、无法灵活反映不同品类物品关键特征、查询条件受限的局限性,能够引导旅客较为准确、完整地描述遗失物品的信息,提出更为灵活的、满足自身实际需要的查询要求。
3.3 基于多模态融合与向量检索的遗失物品匹配技术
旅客在申报遗失物品时,以及客服人员在登记拾得物品信息时,都会提供物品的文本描述和图像特征信息。多模态融合与向量检索技术通过将文本描述与图像特征映射至统一语义空间,实现跨模态高效匹配[8]。
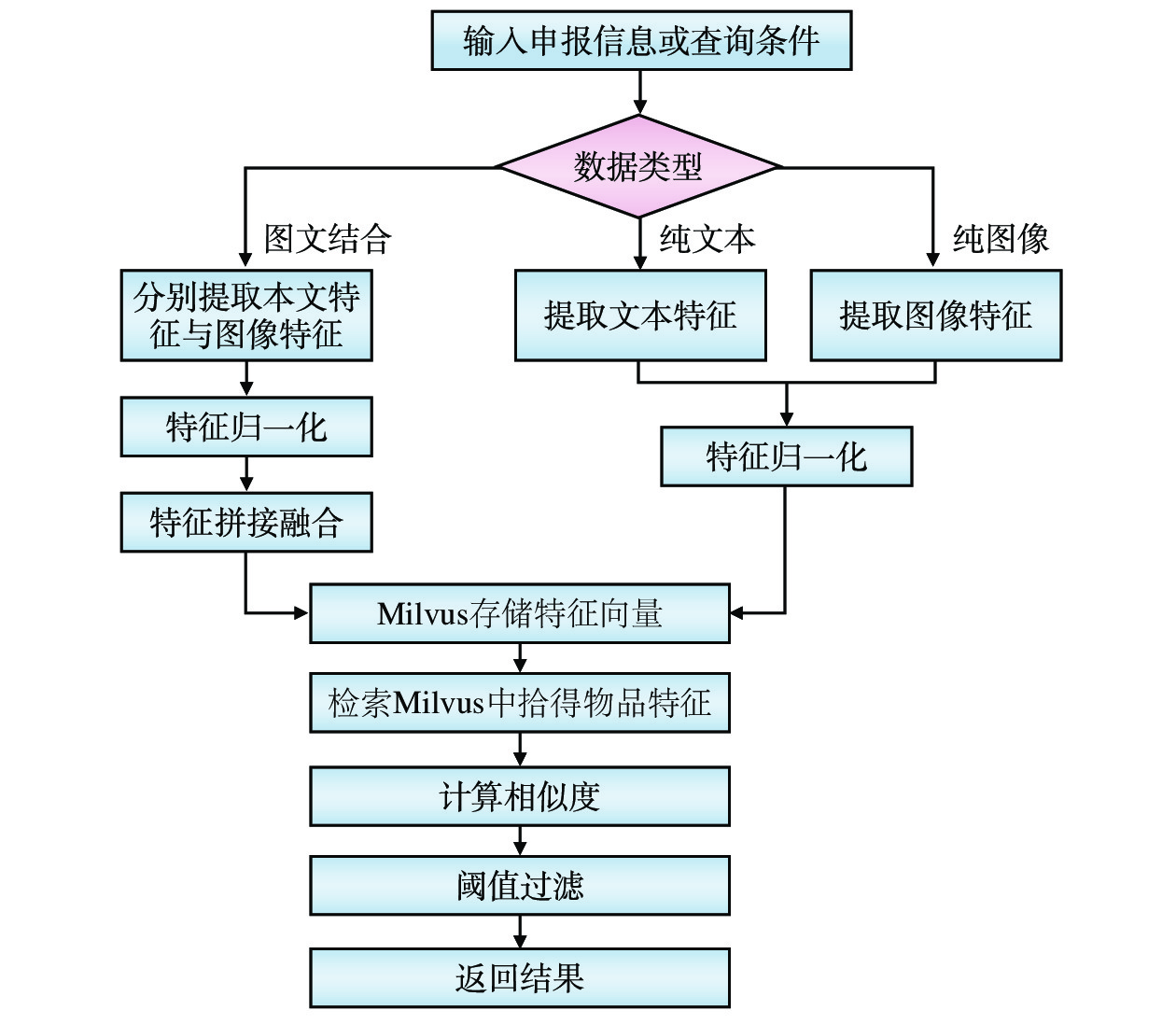
本文通过 Chinese-CLIP 生成多模态特征向量,结合Milvus向量数据库,实现遗失物品匹配,可支持特征向量快速检索,突破传统基于关键词的遗失物品匹配查询无法处理复合特征的局限性,可提升复杂场景下的检索精度,降低人工比对成本,具体原理如图4所示。
遗失物品匹配工作流程分为特征入库与相似检索两个阶段:入库时对于纯文本和纯图像数据,提取其特征后经归一化处理存储即可;对于图文结合数据,分别提取文本特征与图像特征,经归一化处理后拼接为融合向量存储至Milvus向量数据库;检索时将申报信息特征库或查询条件特征库中的特征向量与拾得物品特征向量进行相似度计算并通过阈值过滤返回匹配结果,实现跨模态特征融合与高效相似匹配。
(1)多模态特征向量生成与存储
图像特征提取:利用微调后的 Chinese-CLIP 视觉编码器(ViT)解析遗失物品图像,提取几何形状、主色调、材质纹理等归一化向量,重点优化铁路场景下低光照、复杂背景的细节捕捉能力。
文本特征编码:通过 Chinese-CLIP 文本编码器(RoBERTa)处理 DeepSeek-R1大模型提取的结构化槽位信息,如 “黑色皮质钱包”,生成语义向量并归一化,支持复合特征联合编码,如“颜色 + 材质 + 品牌”。
图文特征融合:对同时包含特征描述文本与图像信息的遗失物品申报记录,通过拼接图像向量与文本向量生成联合特征向量[9],提升跨模态语义对齐精度。
以上多模态特征向量均存储于Milvus向量数据库中,并建有索引,便于快速检索匹配使用。
(2)向量检索与相似度计算
在遗失物品匹配过程中,采用 Milvus 的 IVF-Flat 混合索引[10],即“倒排索引 + 精确搜索”,先通过倒排索引,在拾得物品的特征向量中快速定位包含目标特征的向量簇,如 “黑色”“皮质” 相关向量簇,再在簇内执行内积计算,检索耗时控制在50 ms以内。
纯文本检索时,与拾得物品的纯文本向量和纯图像向量别计算点积,并按文本匹配权重 0.6、图文匹配权重 0.4 进行加权融合,突出文本描述主导作用;纯图像检索时,与拾得物品的纯图像向量和纯文本向量分别计算点积,按图像匹配权重 0.7、图文匹配权重 0.3 加权融合,强化图像特征优先级;图文混合检索时将文本与图像的联合向量,直接与拾得物品的图文融合向量计算点积,实现跨模态语义深度对齐。利用归一化向量的内积等价计算余弦相似度,结果按相似度降序排列,相似度高于设定阈值的物品将由人工进行确认。
4 结束语
针对铁路旅客遗失物品管理业务效率低、人工匹配查找工作量大等问题,本文设计了基于 Chinese-CLIP+DeepSeek 的铁路旅客遗失物品管理系统。基于DeepSeek-R1 大语言模型构建智能客服机器人,引导旅客在多轮自然语言对话的过程中,完成遗失物品申报与查询,补全查询条件,减轻旅客在遗失物品申报与查询时准确描述物品特征的表达困难,显著改善旅客服务体验;通过微调Chinese-CLIP模型,提升其面向铁路旅客遗失物品的跨模态学习表示能力,能够更准确地提取旅客遗失物品申报形成的文本与图像特征;采用Milvus向量数据库管理特征向量,实现旅客申报遗失物品与拾得物品的智能匹配,减轻人工对比查找遗失物品的工作量。该系统涵盖遗失物品申报与查询、拾得物品管理、遗失物品招领与视频追溯、物品认领与核销、数据分析等铁路旅客遗失物品管理全流程业务,考虑到各车站管理的不同特点和要求,设计了许多可灵活设置的配置项,以适应不同车站的实际管理要求。该系统能够提升铁路旅客遗失物品管理的效率与服务水平,为铁路客运服务智能化管理提供可落地的技术方案。
后续将对模型的数据处理、语义理解等方面进行优化:针对同类别物品外观相似导致的局部特征区分难题,拟将引入注意力机制,以强化特征提取能力;针对旅客申报遗失物品时口语化表述通常存在语义解析精度不足的问题,考虑建立铁路旅客遗失物品领域专业知识库,通过整合行业术语标准和历史申报语料,优化 DeepSeek 大语言模型的领域适配性,实现口语化描述到标准化特征的精准转换。通过上述优化,进一步提升匹配精度和自然语言交互体验。
-
表 1 实验环境配置
配置 版本及参数 主机CPU 12th Gen Intel(R) Core(TM) i5-12400 2.50 GHz 内存 8 GB 显卡 NVIDIA GeForce RTX 4070 编程语言 Python 3.9 深度学习框架 Pytorch 2.0  下载: 导出CSV
下载: 导出CSV
表 2 Chinese-CLIP预训练模型微调的超参数设置
超参数 取值 Batch size 64 Learning Rate 0.00001 Epoch 50 Optimizer Adam Weight delay 0.001 Warm up 5 Vision-model ViT-B/16 Text-model RoBERTa-wwm-Base Context length 52
下载: 导出CSV
表 3 Chinese-CLIP预训练模型微调前后性能指标对比
Recall@1 Recall@5 Recall@10 MeanRecall 微调前 26.91 46.86 51.76 41.84 微调后 32.08 59.44 68.99 53.51
下载: 导出CSV
表 4 意图−槽位数据记录示例
意图 槽位列表 对话阶段 物品申报 名称 值 状态 信息确认完成 丢失时间 ****年**月**日 已填充 车次/地点 ***次列车***号车厢 已填充 物品类别 钱包 已填充 颜色 黑色 已填充 材质 皮质 已填充 特征 带金色扣子 已填充 内含物 身份证 已填充
下载: 导出CSV
-
[1] 聂 葳,叶成炜,杨家慧,等. 基于CHINESE-CLIP跨模态图像文本检索研究[J]. 电子制作,2024,32(22):61-66. DOI: 10.3969/j.issn.1006-5059.2024.22.016 [2] 施志晖,陆岷峰. DeepSeek驱动银行智能化转型:本地化模型优化与风险管理跃迁[J]. 区域金融研究,2025(2):1-9. DOI: 10.3969/j.issn.1674-5477.2025.02.002 [3] 李 超,徐云龙,华中伟,等. 一种基于Python Flask的Web服务器端设计[J]. 信息与电脑,2019,31(8):87-88. [4] 王 璐,胡忠秋. 基于Milvus的以图搜图技术的分析及应用[J]. 数字技术与应用,2024,42(7):134-136. [5] 尹文昕,于海琛,刁文辉,等. 遥感场景理解中视觉Transformer的参数高效微调[J]. 电子与信息学报,2024,46(9):3731-3738. [6] 侯佳腾,常 薇,林冠峰. 基于自然语言理解技术的智能客服机器人的设计与实现[J]. 电子技术与软件工程,2019(23):238-240. [7] 宋一培. 基于意图识别的多轮任务型问答系统的研究与实现[D]. 北京:北京邮电大学,2023. [8] 李 博,朱建生,戴琳琳,等. 铁路客运场景下基于图像搜索的遗失物品查找方法[J]. 铁道运输与经济,2024,46(5):89-99. DOI: 10.16668/j.cnki.issn.1003 [9] 赵雪峰,胡瑾瑾,吴德林,等. 一种基于特征拼接、标签迁移及深度学习组合的专利价值评估方法[J]. 情报学报,2023,42(6):663-680. [10] 黄中杰,郭莎莎. 基于深度语义的大规模图像检索[J]. 软件,2024,45(6):103-105,183.

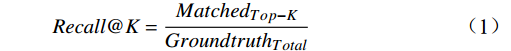
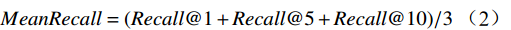
计量
- 文章访问数: 36
- HTML全文浏览量: 9
- PDF下载量: 10
