

Research on Application of Data Warehousing and Data Mining Techniques in Railway Freight
-
摘要:
随着近年来中国铁路南宁局集团有限公司(简称:南宁局)货运量激增,既有货运业务系统的数据量增长迅速,由于数据分散存储在各系统独立建设的数据库中,对于需要跨库的复杂货运业务查询和联机分析应用效果不佳。为充分发掘货运业务数据资产的价值,文章选用基于大规模并行处理(MPP,Massively Parallel Processing)集群架构的数据仓库产品,对多源海量货运业务数据进行整合处理和高效存储,使联机分析数据查询的响应时间从传统数据库的分钟级优化至秒级,为开展数据挖掘应用研究奠定了基础。采用改进K-means聚类和朴素贝叶斯分类算法,开展货运客户价值分析与装车落空预测。结果表明,基于K-means算法构建货运客户细分模型,可帮助货运部门快速识别不同客户的价值,为货运营销找准营销方向及价格策略调整提供可靠依据;基于朴素贝叶斯算法构建装车落空预测模型,预测结果可增强货运组织对潜在风险的预见能力。研究成果有助于推动南宁局货运管理经验驱动向数据驱动转型,为货运业务高质量发展提供支撑。
Abstract:With the sharp increase in freight volume of China Railway Nanning Group Co., LTD. (referred to as: Nanning Bureau) over past years, the data volume of the existing freight business information systems has grown rapidly. Since the data is scattered and stored in the independently built databases of each system, the application effect for complex freight business queries and online analysis that require cross-database is not good. To fully explore the value of freight business data assets, this article selects the data warehouse product based on the MPP cluster architecture to integrate, process and efficiently store multi-source and massive freight business data, optimizing the response time of online analysis data query from minute-level of traditional databases to second-level, laying the foundation for conducting research on data mining applications. The improved K-means clustering and Naive Bayes classification algorithms are respectively adopted to carry out the analysis of freight customer value and the prediction of missed loading. The results show that constructing a freight customer segmentation model based on the K-means algorithm can help the freight department quickly identify the value of different customers and provide a reliable basis for freight marketing to accurately identify the marketing direction and adjust the price strategy. The loading failure prediction model is constructed based on the Naive Bayes algorithm, and the prediction results is condusive to enhance the risk foreseeing capability of freight organization. The research results are conducive to promoting the transformation of Nanning Bureau's freight management from experience-driven to data-driven, and providing support for the high-quality development of freight business.
-
中国铁路南宁局集团有限公司(简称:南宁局)是中国西南地区重要的铁路运输枢纽,其货运业务在区域经济发展中扮演着重要角色。随着“一带一路”倡议的深入推进和西部陆海新通道的建设,铁海联运和跨境班列的协同发展,使得南宁局货运量快速持续增长。南宁局现有的货运业务系统主要包括铁路货票信息管理系统(简称:货票系统)、铁路运输调度管理系统-货运调度子系统(简称:货调系统)、铁路货运站安全监控与管理系统(简称:货运站系统)、铁路集装箱运输管理信息系统(简称:集装箱系统)。这些系统已建成多年,运行稳定。随着南宁局近年来货运量的激增,货运业务数据量增长迅速;其中,货票系统2024年内产生的货票数据记录多达366.1万条,货运站系统2024年内产生的作业数据记录多达523.9万条、集装箱系统2024年内产生的业务数据记录多达330.9万条,分别较上年增长3.7%、8.8%、27.2%。从这些海量数据中筛选出对管理层和业务人员具有价值的信息变得尤为重要。由于这些数据分散存储在各个业务系统独立建设的数据库中,对于需要跨库的复杂货运业务查询和联机分析应用效果不佳,现有货运业务数据资产的价值没有被充分发掘。
数据挖掘技术能够对数据仓库中的大量复杂历史数据进行深入的研究和分析,进而识别出潜在的信息,从而为企业的管理阶层决策时提供参考[1-2]。为进一步优化南宁局货运作业组织、完善营销服务体系,需要运用数据仓库、数据挖掘等大数据技术,整合既有货运业务信息系统的数据资源,通过挖掘数据价值赋能货运业务,达到提质增效、货运增量的目的。如何将不同来源、不同结构的数据进行有效整合,构建面向联机分析应用的货运数据仓库,并运用数据挖掘技术进行货运业务分析,为货运管理提供准确、可靠的决策依据,成为南宁局当前数字化转型的关键挑战之一。
目前,南宁局货运业务发展态势良好,但也需要正视市场竞争,做好客户服务,不断提升货运服务质量,满足客户对运输时效、成本和安全性的多样化需求。另外,南宁局货运部门需要解决好运力与需求的匹配问题,在空箱不足、货运设备老化等条件下,通过加强调度管理,避免出现货运装车落空,提升运输效率。为此,本文选用高性能数据仓库产品,构建货运数据集市,整合货票、货调、集装箱等多个既有货运业务系统的数据资源,聚焦货运客户价值分析与装车落空预测两项应用,研究利用数据挖掘技术,为货运业务管理提供准确可靠的决策依据,推动货运管理从基于经验决策到基于数据决策的转变。
1 南宁局货运业务信息系统现状及货运分析应用面临的瓶颈
1.1 南宁局货运业务信息系统应用现状
南宁局现有的货运业务信息系统基本上实现了对货运生产作业各主要环节的信息化支撑服务,具体应用情况如表1所示。
表 1 南宁局现有货运业务信息系统应用现状系统 应用现状 货票系统 主要用于车站制票、货运和税控信息查询统计、票据信息流程管理等;系统能对票据基础信息进行查询和统计,但缺少对票据信息中蕴含的重要信息进行分析,如发货人、运费收入率等 货调系统 主要用于货运装卸日计划编制、装卸计划进度填报等作业流程管理。系统可以查询日常装卸计划的执行和兑现等情况,但对于计划落空只能掌握结果,不能提前分析和应对 货运站
系统车站级系统主要用于货运业务受理申报、生产组织、安全监控等;铁路局集团公司级系统主要用于生产作业监督、安全检测监控等;只受理整车业务,与集装箱业务数据不共享,难以统计货运总运量 集装箱
系统主要用于对车站办理集装箱业务全流程的管理。只受理集装箱业务,货运部门统计货运发送量需分别统计整车和集装箱数据 南宁局现有的货运业务信息系统应用已相对成熟,涵盖了各类货运业务全部作业流程管理,但各系统处于独立运用状态,未形成有机整体,且普遍存在重生产应用、轻数据分析的问题,系统间的数据资源共享不足,缺乏对各类货运业务数据价值的深入挖掘。
1.2 南宁局货运数据分析的需求
2024年,广西壮族自治区货物发送总量23.71亿吨。其中,铁路的货物发送量为1.1亿t,仅占广西货运发送总量的4.6%,远低于公路74.9%和水路20.5%的市场份额。铁路运输占广西货运市场的份额不高,还有较大提升空间。2024年,国铁集团推出了加大运输组织优化力度,加强卸车组织,加大市场营销力度,实施分层营销、带着物流解决方案营销等举措,旨在推动铁路货运向现代物流转型,实现货运增量提质。上述举措落实的关键之一就是要解决货运数据资产有效利用问题,多年来这个问题始终是南宁局货运部门的痛点。
由于货运业务数据分散在货票、调度、集装箱等多个独立系统中,货运业务人员在制作分析报表的实际工作中,例如,在制作客户画像、装车兑现率分析等复杂分析报表时,现有系统无法直接生成,货运业务人员需要分别从多个系统查询相关数据,需要手动将不同系统的查询结果建立关联,完成数据转换、排序、复杂计算等数据整理后,才能形成所需的各类报表。数据收集、整理和分析的工作效率很低,需要耗费大量的时间和精力,而且电子表格形式的报表也不能直观地展示分析结果。
为此,货运业务人员迫切期望构建一个货运数据分析平台,实现货票、调度、集装箱等货运业务数据的高效整合与统一管理,实现一站式便捷查询,无需在不同系统间来回切换操作。同时,能够大幅提升查询分析效率,无需长时间等待,提升数据处理效率,使货运业务人员能够从大量繁琐的数据整理工作中解放出来,将工作重点转移到业务分析和流程优化中,管理层可实时掌握全局运力与收入趋势,实现数据驱动的高效管理与服务质量提升。
1.3 货运数据分析面临的瓶颈
(1)数据存储载体难以支撑复杂分析需求:南宁局既有的货运业务信息系统采用传统关系型数据库(如Oracle RAC集群)存储和管理数据,主要用于支持联机事务处理(OLTP,On-Line Transaction Processing),难以满足复杂的联机分析处理(OLAP,On-Line Analytical Processing)应用要求,在复杂的货运业务查询中性能表现不佳。例如,当货运业务人员查询“近五年高价值客户运输趋势”时,涉及TB级历史货运数据的聚合查询,平均响应时间超1 h,且因锁表冲突导致40%查询失败。进行一次跨系统的客户与货物的关联分析,需要先从货票系统的基础客户信息表找到发货人ID,再从海量货票数据中筛选出与之关联的目标货物,通过跨库脚本与货调系统装车基础信息表的发货人名称建立映射关系,最终分析出目标货物的装车情况,整个过程耗费大量时间,并严重挤占系统计算资源。尽管前些年曾经尝试使用Hadoop大数据技术管理货运业务数据,但因海量数据的复杂查询延迟较大、数据一致性无法保证等问题,未达到货运部门的预期要求。
(2)数据分析的算法适配性不足:南宁局货运部门曾尝试使用数据挖掘技术,但所使用的算法与铁路业务场景契合度较低,例如早期将随机森林模型应用于客户细分,由于特征选取时未考虑运费收入率等关键指标,导致分类结果中高价值客户漏报率高达25%。例如,某化工企业年运输量仅8万t,但单吨运费为普通货物的3倍,模型却将其归类为“一般客户”。另外,曾尝试将LSTM模型用于装车落空预测,预测准确率88%,但其黑箱特性令业务人员难以理解风险成因;例如,2023年某次预测显示“南宁南站装车落空概率达80%”,但因模型未考虑具体影响因素,如“专用线拥堵”或“车种匹配失败”,导致应急调整措施缺乏针对性,最终实际落空率仍达75%。
2 研究目标
2.1 构建货运主题数据仓库
选用高性能数据仓库产品,构建货运主题数据仓库(即货运数据集市),对多源海量货运业务数据进行整合处理和高效存储,实现千万行级别的货运数据记录的快速处理,使联机分析应用数据查询的响应时间从传统数据库的分钟级优化至秒级,并且能支持50个以上并发用户的高效访问,并为数据挖掘应用研究提供高质量数据。
2.2 实现客户精细化管理
客户细分管理是市场营销和客户关系管理中的核心策略,旨在通过将客户群体划分为具有相似特征的子群,实现精准营销、资源优化和客户价值最大化。铁路货运客户细分管理是通过对客户需求、行为、价值等特征进行分类,制定差异化的服务策略,以提升运输效率、客户满意度和企业盈利能力。基于货运主题数据仓库,构建客户价值分层模型,精准识别高价值客户群体,为个性化营销策略制定提供数据支持,从海量货票数据中识别高价值客户,提升客户留存率与运费收入。
2.3 提升装车落空预测能力
铁路装车落空是指在铁路货运计划中,已安排装车的车皮或列车因各种原因未能按计划完成装车任务,导致运力资源闲置的现象。这种现象会影响铁路运输效率,增加运营成本,甚至影响客户满意度。基于历史装车数据与实际装车信息,构建装车落空预测模型,提前识别运力缺口风险,动态优化全局车流计划,提升装车计划兑现率。
3 技术选型
3.1 数据仓库选型
数据仓库的主要用途是支持OLAP应用,以数据应用主题为导向,为管理决策提供数据支持[3]。大规模并行处理(MPP,Massively Parallel Processing)是一种高性能计算架构,通常用于大型数据仓库和数据分析系统,以处理大量数据和提供实时分析结果[4]。Greenplum 是一款开源的MPP架构数据仓库产品,相比Hadoop生态而言,更适合本文应用场景,如表2所示。
表 2 MPP与Hadoop对比指标 MPP架构(Greenplum) Hadoop生态(Hive+Spark) 查询延迟 毫秒级(复杂查询<10 s) 分钟级(复杂查询>5 min) 数据一致性 强一致性(ACID) 最终一致性(BASE) 适用场景 支持实时调度与高并发查询 适合离线批处理 3.2 客户细分数据挖掘算法选择
聚类技术多应用于客户细分、新闻分类和文章推荐等领域,对比K-Means、K-中心点、系统分类等常用聚类分析方法,如表3所示;针对货运客户细分、挖掘客户价值的实际需求,选用K-Means算法。
表 3 客户细分算法选择算法 优点 缺点 适用场景 K-Means 计算高效,适合处理
大规模数据集对初始质心敏感,可能收敛到局部最优 客户细分、图像压缩、文本主题聚类 K-中
心点对噪声和离群点更
鲁棒计算复杂度高,不适合大数据集。 医学诊断、位置服务 系统分类 能展示数据的层次结构,适合探索性分析 计算复杂度高,难以处理大数据 生物分类学、文档主题层次分析 3.3 装车落空分析算法选型
对比朴素贝叶斯、随机森林、LSTM等几个常见的分类分析方法,如表4所示。装车落空分析涉及的主要特征(车种、吨数、品类等9项)在业务逻辑上相互独立,且装车计划需要快速响应实时预测需求;朴素贝叶斯在支持结构化数据的特征独立性和计算效率上更契合装车落空分析应用场景。
表 4 货运落空预测算法选型维度 朴素贝叶斯 随机森林 LSTM 数据类型 结构化数据
(独立特征)结构化数据(特征可交互) 序列数据(时间/文本依赖性强) 计算效率 高(时间复杂度低,适合实时动态调度) 中(内存占用高,
实时性差)低(数据与算力
需求高)可解释性 高 中 低 4 解决方案
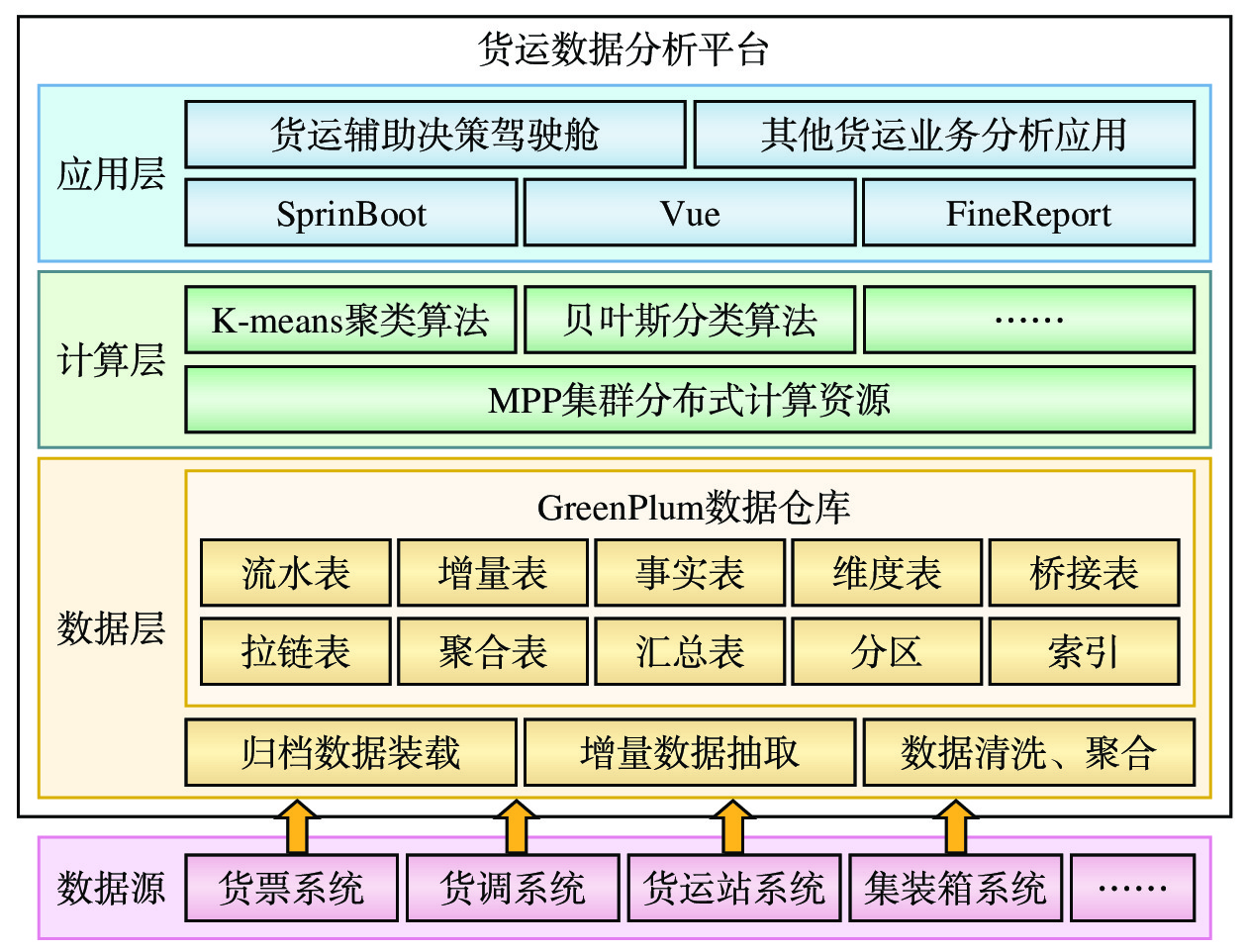
本文提出的货运数据分析平台的总体架构如图1所示。
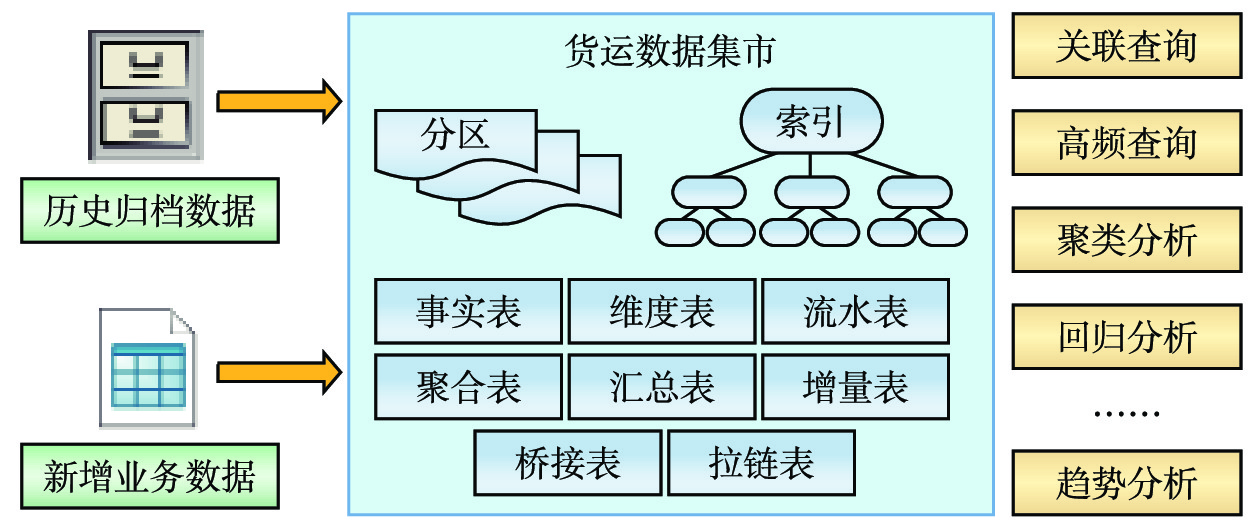
(1)数据层:基于Greenplum数据仓库,构建货运数据集市,批量装载既有货运业务系统已归档的货运历史数据,并通过数据抽取任务定期从货运业务系统提取增量数据,经过数据清洗、关联、聚合、汇总处理后,存储在相应的流水表、增量表、事实表、维度表、桥接表、拉链表、聚合表、汇总表中,并创建分区和索引。
(2)计算层:结合具体货运分析任务,研究选取适用的数据挖掘模型,利用MPP集群的并行计算能力,对模型进行训练和调优,形成有效的算法模型;例如,将改进K-means聚类、朴素贝叶斯分类算法分别用于货运客户细分、装车落空预测。
(3)应用层:基于SpringBoot+Vue+FineReport技术栈,定制开发数据驾驶舱等货运分析应用,将复杂查询结果和模型计算结果转化为各种可视化图表,提高数据的可读性,支持多维度数据钻取分析,将二维复杂报表转化成易于比较和分析的多维图表,帮助货运管理人员理解数据之间关系、洞悉变化和规律,从而做出更准确的判断和决策。
4.1 数据层设计
4.1.1 数据源接入与抽取
数据源主要来自货调系统、货票系统、货运站系统、运输信息集成平台、集装箱系统等,涉及的历史数据共计近10亿条,如表5所示。
表 5 数据源系统名称 数据表名称 货调系统 装车日班计划表、落空车记录表等 货票系统 货票车辆子表、货票费用子表、货票基本信息表、货票集装箱表、货票里程子表、货票结账信息表等 集装箱系统 到卸车信息表、到卸箱信息表、集装清单总表等 运输调度管理系统 甩挂车信息表、货运计划时间表、货运计划配空需求表等 货运站系统 卸七甲(卸车作业统计表)、装七甲(装车作业统计表)等 运输信息集成平台 确报目录和正文表、站存车表、车辆货物信息表、车辆作业信息表等 现车系统 车辆基础信息表、股道占用表等 (1)数据抽取:主要采用ETL、Kettle、任务计划程序等工具,构建自动化数据抽取流水线,支持多线程并发抽取,并根据业务数据更新时间及频次的不同,通过时间戳与触发器机制捕获新增或变更数据,使用批处理脚本,并结合任务计划程序,实现数据的增量抽取,在Greenplum数据仓库中进行整合和存储。
(2)数据清洗与处理:由于所采集的原始数据多为现场手工录入,数据内容可能含有特殊字符、异常值等;另外,因各系统中数据字典不统一,还存在数据编码不一致的问题,需使用字符串替换、JavaScript脚本对数据进行清洗。例如,替换所有记事栏字段中的空格、半角字符等规范字符存储,剔除运费为0的自备箱回空异常数据。
4.1.2 利用数据仓库工具构建货运数据集市
数据集市是数据仓库的轻量级分支,其本质是构建面向部门或工作组的精简型数据仓库[5],仅存储企业特定子业务的数据,以快速响应部门级数据分析需求。本文选用MPP架构数据仓库产品构建货运数据集市,如图2所示。
基于货运数据集市,开展货运数据分析具有以下几个方面的优势:
(1)显著减少高频聚合/汇总查询和跨系统表间关联查询开销:针对高频分析场景,如运量分析、装车分析,增加数据聚合表和汇总表,提前计算好聚合关键指标(如按品类、客户计算的发送量、装车数等)和汇总指标,存储在聚合表和汇总表中备查,避免重复执行同一查询任务的计算开销,还能减少复杂的跨表连接操作,大幅降低查询延迟。对于复杂货运业务分析(例如高价值客户运输趋势),原先需要跨多个系统中的数据表进行查询,在货运数据集市中,可直接在单个高维事实表上,或通过桥接表与2个事实表联结完成查询,响应时间从分钟级缩短至秒级。
(2)面向高频查询优化数据分区:对于客户运输次数统计、运费贡献率分析、装车落空风险预测等业务分析,确定高频查询字段(如客户ID、装车日期、到发站、车种、品类等),设计相应的分区键和分区类型,结合建立数据索引,提升高频数据查询性能。例如,对货调数据按月份分区,可快速定位特定时间段内的数据,避免查询时全表扫描。
(3)保证数据一致性与标准化:通过数据集市的标准化数据建模,无需人工进行数据转换来解决系统间数据编码、格式不一致的问题,使跨系统数据分析过程能够自动顺畅完成。例如,统计“铁海联运班列运量”时,无需再由分析人员手动核对各系统的集装箱编码差异。
(4)支持快速与历史数据融合分析:为保证性能,传统业务系统OLTP应用仅支持当前数据库的数据查询,进行时间跨度较大的历史数据分析,需要从归档的数据库手动提取数据,且无法实现当前数据与历史数据的联合分析。通过在数据集市中构建时间序列聚合表(如按日/月汇总的运量趋势表),依托强大的MPP并行计算能力,还可支持快速的时间维度钻取。例如,在春运期间分析装车缺口时,可直接读取近几年同期数据进行分析。
4.2 计算层设计
本文针对铁路货运业务,分别利用K-means算法和朴素贝叶斯算法构建货运客户细分模型和装车落空预测模型。
4.2.1 货运客户细分模型
货运客户细分的目标在于聚合属性特征相似的客户群体,基于海量客户数据分析,通过聚类划分形成差异化价值簇[6],对客户群体进行合理划分,实现精细化分类管理。
(1)特征选取:选择运输次数、平均货运量、平均运输里程、平均运费收入率作为货运客户分类的特征数据。
(2)数据预处理:K-means算法是基于距离的算法,对数据异常值和数据尺度较为敏感。清除各项分类特征数据中的异常值,例如剔除运费收入率为0(均为自备箱回空)的15个客户;为消除各个特征的尺度差异,对各项特征数据进行归一化变换,将特征数据映射到0~1范围内,最后再乘以特征的权重,以控制分类结果的偏向性。例如,某一类客户平均运输里程为500 km,平均货运量为50 t,数值上相差10倍,如果直接计算欧氏距离,平均运输里程的影响会远大于平均货运量,导致分类结果出现偏向性,需通过归一化,将所有特征数据缩放到相同尺度范围(0~1),使每个特征对模型训练的贡献均衡。
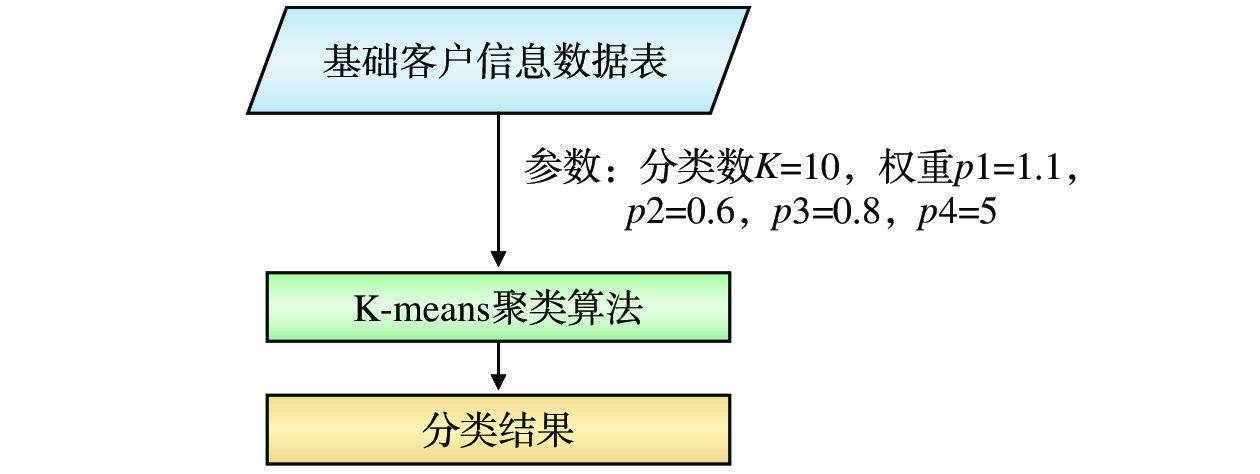
(3)模型建立:为获得较好分类结果,需不断调整分类数K,以及运输次数、平均货运量、平均里程、平均运费收入率4项分类指标的权重值p1、p2、p3、p4,如图3所示。
K-means算法是通过计算数据对象间的欧氏距离来评估相似性,距离值越小表明对象间相似度越高,距离值越小的对象更可能被划分至同一簇中。对于数据对象X和Y,其距离dist(X,Y)计算公式为
dist(X,Y)=√n∑i=1(xi−yi)2 (1) 式中,xi、yi分别为数据对象X和Y的第i个特征值。
将K-means算法应用在货运客户细分中,分类特征共有4个,较大的K值才能更好地区分结果,故选取K=10,将客户细分为重要客户、保持客户、重要挖潜客户、重要发展客户、一般挖潜客户、一般发展客户、普通客户、储备客户、低价值客户和无价值客户10个类别。鉴于分类特征中运费收入率与收入密切相关,最为重要,故将p4设为5;运输次数与客户忠诚度相关,重要性次之,故将p1设为1.1;货运量、里程相对影响较小,故将p2设为0.6,p3设为0.8;p1=1.1,p2=0.6,p3=0.8,p4=5。
4.2.2 装车落空预测模型
各货运单位每日都会通过货调系统提报装车完成、落空原因等信息。货调系统中沉淀了大量的装车历史数据,利用这些数据对未来落空情况进行预测,辅助调整生产组织策略,以提升货运装车日计划的兑现率、满足率。
(1)特征选取:选择请求类型、请求车种、请求车数、请求吨数、发站名称、品类、发货人、订单状态、专用线名9项数据作为特征数据。
(2)数据预处理:预测模型算法要求使用数值数据进行训练,需要将字符串类型的特征数据转化为数值类型特征数据,且要求保证特征数据不能为空。为保证特征数据不为空[7],需要剔除9项特征数据中存在空值的数据记录,例如订单状态为空、发货人为空的数据记录都必须剔除;请求车种、发站名称、品类、发货人、订单状态、专用线名都是字符串类型数据,要将字符串类型数据进行数值化编码,其中,车种数值化编码如表6所示。
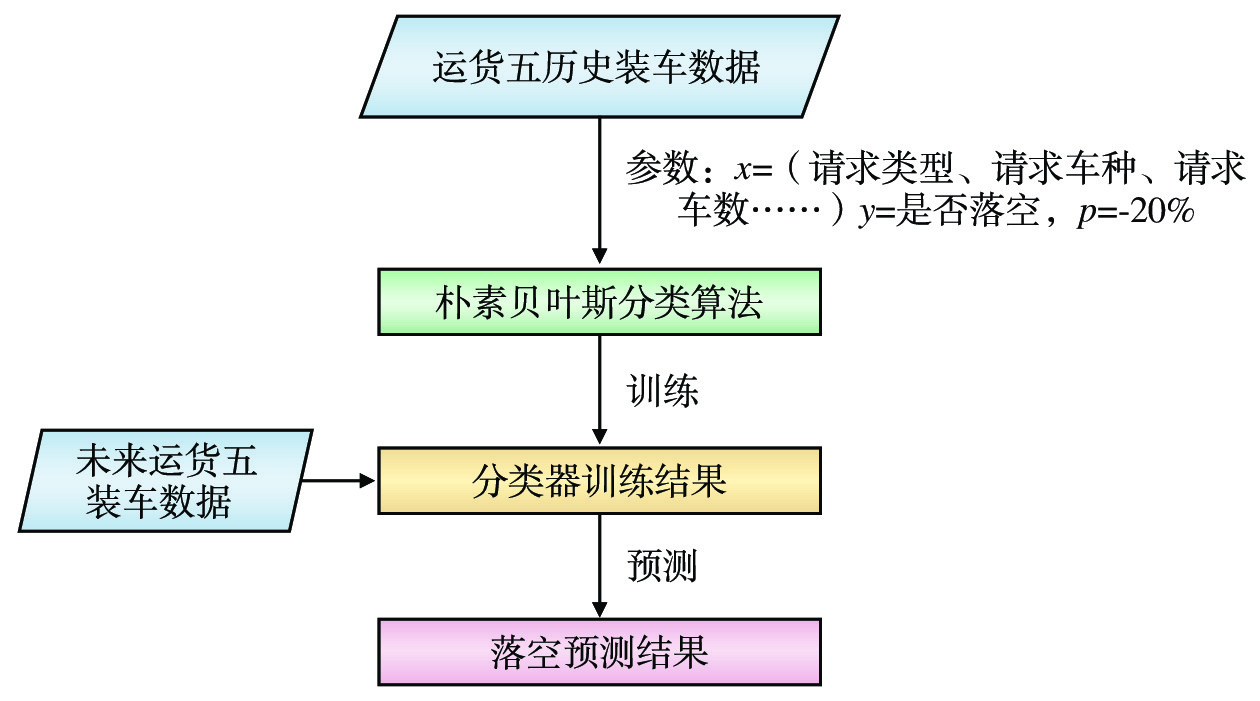
表 6 车种数据的数值化编码示例车种 编码 敞车(C) 1 棚车(P) 2 罐车(G) 3 平车(N) 4 集装箱车(X) 5 粮食车(L) 6 矿石车(K) 7 冷藏车(B) 8 (3)模型建立:将朴素贝叶斯分类算法应用于装车落空预测,最终类别仅有2类:落空与不落空。在货调系统生成装车日班计划数据后,将计划中的请求类型、请求车种、请求车数、请求吨数、发站名称、品类、发货人、订单状态、专用线名等9个特征向量值作为模型分类器的输入,通过计算可以得到每条计划装车落空的概率。利用数据集市中的历史数据对模型进行训练,得到训练好的模型分类器。分类器根据装车落空的概率,判定每条计划的装车落空结果,即落空或不落空(设定1为落空,0为不落空)。装车落空预测模型如图4所示。
X为输入特征(如请求车种、请求车数、请求吨数等9维向量),Y为输出类别(落空或不落空),则X与Y的联合概率和条件概率为
P(X,Y)=P(Y|X)×P(X)=P(X|Y)×P(Y) (2) 其中,P(Y)为先验概率,即历史数据中落空(或非落空)的总体比例;P(X∣Y)为似然概率,表示在已知落空(或非落空)情况下,特征X出现的概率(如棚车在落空订单中的占比);P(X)为证据因子,即特征X在所有数据中的出现概率。
由公式(2),可推导似然概率P(X∣Y)为
P(X|Y)=P(X|Y)×P(Y)P(X) (3) 利用历史数据统计先验概率和似然概率,可计算新装车计划的落空风险。例如:若某订单的P(落空∣X)=0.9,则提示调度员需优先调配资源。
根据贝叶斯的条件独立假设,则有
P(X|Ci)=m∏k=1P(Xk|Ci) (4) 条件概率
P(X1|Ci),P(X2|Ci),⋯,P(Xm|Ci) 可从训练数据集求得。根据此方法,对一个未知类别的样本X,可以分别计算出X属于每一个类别Ci 的概率P(X|Ci)P(Ci) ,然后选择其中概率最大的类别作为其类别,分类步骤如下:步骤1:设
x={a1,a2,⋯,a9} 为一个待分类项,而每个a为x的一个特征属性;例如,12月1日某条装车计划为:请求车种(a1)是敞车(编码1)、请求车数(a2)是10车、请求吨数(a3)是700吨、发站(a4)是南宁南站(编码32),···;经过数据预处理后,得到量化后的模型输入向量为{1,10,700,32,···};步骤2:有类别集合
C={y1,y2} ,其中 y1为“落空”,y2为“不落空”;步骤3:计算
P(y1|x),P(y2|x) ;步骤4:如果
P(yk|x)=max{P(y1|x),P(y2|x),⋯,P(yn|x)} ,则x∈yk 。训练数据中“落空”样本占比不到3%,且“落空”样本存在部分特例(受天气、路外环境等影响),直接使用原始预测值会高估落空风险。为获得较好的预测结果,需对最终概率进行微调[8],使预测结果更准确地反映实际生产中的落空风险。通过历史数据验证,将所有概率均下调20%(如原始P=0.8,则调整为P=0.64),结果与实际较为接近。
4.3 应用层设计
为货运管理人员提供简单明了、清晰易懂的货运业务分析应用。例如,基于货运客户细分模型的计算结果,定制开发辅助决策驾驶舱,如图5所示;运用环形图、折线图、条形图、雷达图展示客户数、客户占比、收入占比、运输次数、平均货运量、平均里程、平均运费收入率等各项客户指标。货运业务人员可通过对各项指标按照时间、到发站、品类等不同维度属性的逐级钻取,从海量数据中快速识别出高价值客户,以制定针对性的营销策略和运力配置,提升客户满意度和服务质量。
5 应用效果
5.1 运行环境配置
为利用Greenplum数据仓库分布式存储与并行计算能力,部署由1台管理节点服务器(MasterNode)和3台数据节点服务器(SegmentHosts)组成的数据仓库集群。每个数据节点配置为8 CPU(每CPU 64核)和96 GB内存,在数据节点上共配置48个存储计算实例,48个备用实例,采集和存储了共计2.56 TB的货运业务数据。
5.2 联机分析查询效率
对于联机分析查询实例,分别在原有货运业务系统中的数据库和货运数据分析平台中数据仓库上进行测试,查询效率对比如表7所示。
表 7 联机分析查询效率对比查询实例 数据量 原有货运业务系统数据库查询时间 货运数据分析平台数据仓库查询时间 货票登记的整车装车重量与实际装车重量对比(需关联货票和货调系统数据) 2243.5 万行101.24 s 1.259 s 货票集装箱的计划重量与实际重量对比(需关联货票和集装箱系统数据) 2923.5 万行82.109 s 1.337 s 由表7可知,对于千万行级别的数据联机分析查询任务,使用货运数据分析平台,均能在10 s以内响应,联机分析查询效率提高了5倍以上,且支持50个以上的并发用户的高效访问。
5.3 货运客户细分
5.3.1 数据集选取
货运客户细分数据集选取南宁局2024年度出发货票作为样本数据,共计
2934208 条记录。通过将样本数据进行特征合并,得到1773 个客户的信息。5.3.2 细分结果分析
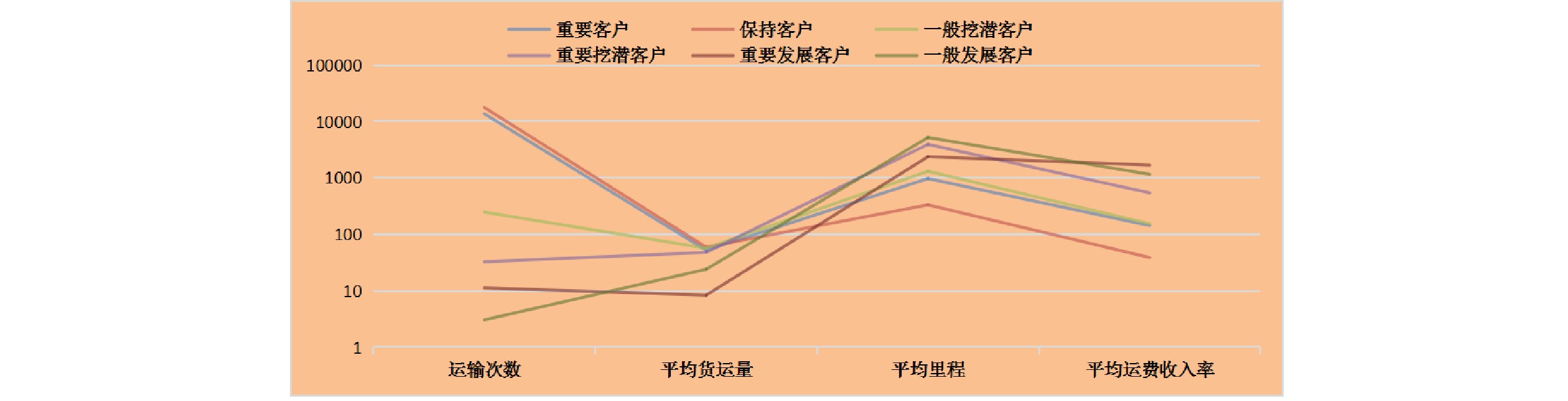
采用K-means算法构建货运客户细分模型,从运输次数、平均货运量、平均运输里程、平均运费收入率等4个维度综合考量客户价值,将货运客户细分为重要客户、保持客户、重要挖潜客户、重要发展客户等10类,对货运客户进行合理的分类,为货运部门制定营销方案提供可靠的数据依据,实现货运营销精细化管理。
如图6所示,为直观地揭示客户价值和贡献,排除贡献程度较低的普通客户、储备客户、低价值客户和无价值客户等4类客户,重点展示重要客户、保持客户、重要挖潜客户、重要发展客户、一般挖潜客户和一般发展客户等6类客户,可以清晰的看出每一类客户在4方面的贡献程度。
5.4 装车落空预测
5.4.1 测试数据集选取
装车落空预测的数据集选取南宁局2023年1月—2024年11月的货调系统运货五大表的历史数据作为训练数据,共计
443020 条记录,2024年12月的装车计划数据作为测试数据。5.4.2 测试结果分析
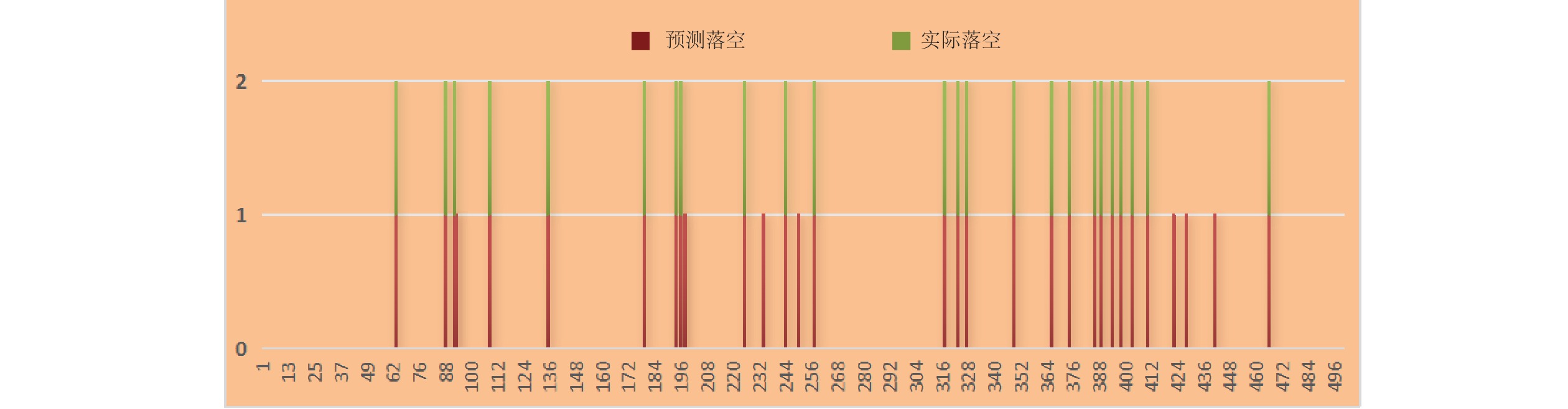
采用朴素贝叶斯分类算法构建装车落空预测模型,在2024年12月进行为期一个月的连续测试,预测每日装车计划是否落空,并将每日落空预测结果量化为1(落空)和0(不落空)。通过预测,可为各货运单位及时掌握装车计划兑现进度,及时提醒调度所、车务站段加强配空、排空车组织,保证当天装卸任务完成提供技术支撑。
测试期满后与实际落空情况进行对比,如图7所示。因数据过多,图7中只节选了该月货运装车计划中的500条计划的预测对比情况,绿色是实际落空情况,红色是预测落空结果,预测命中情况良好,日装车落空预测准确率最高可达90%。
6 结束语
本文选用基于MPP集群架构的数据仓库产品,整合货票、货调、集装箱等多系统当前的业务数据和历史数据,构建货运数据集市,为开发货运OLAP应用奠定了基础;结合南宁局当前货运发展面临的挑战,采用改进K-means聚类和朴素贝叶斯分类算法,开展货运客户价值分析与装车落空预测;数据挖掘模型中引入业务规则,如运费贡献权重、装车需求,增强模型可解释性。基于K-means算法构建货运客户细分模型,可帮助货运部门从海量数据中快速识别客户价值,对客户合理分类,为货运精准营销及价格策略调整提供可靠依据;基于朴素贝叶斯算法构建装车落空预测模型,通过历史数据训练和概率阈值调整,提升预测准确率,预测结果可增强货运组织对潜在风险的预见能力。
本文采用的数据挖掘模型仅在南宁局验证,后续考虑获取更多铁路局集团公司货运数据,通过联邦学习整合多源数据增强模型泛化性。在客户价值分类的基础上,进一步构建货运动态定价辅助决策模型,结合市场需求预测,分析不同时期、不同项目货运价格变化规律,为运价弹性调整提供决策支持。另外,通过与物流基地、港口数据交换,在货运数据集市中补充公路、水运等外部数据,构建多式联运协同分析模型,尝试开展多式联运协同分析,优化多式联运方案,为提高多式联运整体效率提供决策依据,以降低客户物流综合成本。
-
表 1 南宁局现有货运业务信息系统应用现状
系统 应用现状 货票系统 主要用于车站制票、货运和税控信息查询统计、票据信息流程管理等;系统能对票据基础信息进行查询和统计,但缺少对票据信息中蕴含的重要信息进行分析,如发货人、运费收入率等 货调系统 主要用于货运装卸日计划编制、装卸计划进度填报等作业流程管理。系统可以查询日常装卸计划的执行和兑现等情况,但对于计划落空只能掌握结果,不能提前分析和应对 货运站
系统车站级系统主要用于货运业务受理申报、生产组织、安全监控等;铁路局集团公司级系统主要用于生产作业监督、安全检测监控等;只受理整车业务,与集装箱业务数据不共享,难以统计货运总运量 集装箱
系统主要用于对车站办理集装箱业务全流程的管理。只受理集装箱业务,货运部门统计货运发送量需分别统计整车和集装箱数据  下载: 导出CSV
下载: 导出CSV
表 2 MPP与Hadoop对比
指标 MPP架构(Greenplum) Hadoop生态(Hive+Spark) 查询延迟 毫秒级(复杂查询<10 s) 分钟级(复杂查询>5 min) 数据一致性 强一致性(ACID) 最终一致性(BASE) 适用场景 支持实时调度与高并发查询 适合离线批处理
下载: 导出CSV
表 3 客户细分算法选择
算法 优点 缺点 适用场景 K-Means 计算高效,适合处理
大规模数据集对初始质心敏感,可能收敛到局部最优 客户细分、图像压缩、文本主题聚类 K-中
心点对噪声和离群点更
鲁棒计算复杂度高,不适合大数据集。 医学诊断、位置服务 系统分类 能展示数据的层次结构,适合探索性分析 计算复杂度高,难以处理大数据 生物分类学、文档主题层次分析
下载: 导出CSV
表 4 货运落空预测算法选型
维度 朴素贝叶斯 随机森林 LSTM 数据类型 结构化数据
(独立特征)结构化数据(特征可交互) 序列数据(时间/文本依赖性强) 计算效率 高(时间复杂度低,适合实时动态调度) 中(内存占用高,
实时性差)低(数据与算力
需求高)可解释性 高 中 低
下载: 导出CSV
表 5 数据源
系统名称 数据表名称 货调系统 装车日班计划表、落空车记录表等 货票系统 货票车辆子表、货票费用子表、货票基本信息表、货票集装箱表、货票里程子表、货票结账信息表等 集装箱系统 到卸车信息表、到卸箱信息表、集装清单总表等 运输调度管理系统 甩挂车信息表、货运计划时间表、货运计划配空需求表等 货运站系统 卸七甲(卸车作业统计表)、装七甲(装车作业统计表)等 运输信息集成平台 确报目录和正文表、站存车表、车辆货物信息表、车辆作业信息表等 现车系统 车辆基础信息表、股道占用表等
下载: 导出CSV
表 6 车种数据的数值化编码示例
车种 编码 敞车(C) 1 棚车(P) 2 罐车(G) 3 平车(N) 4 集装箱车(X) 5 粮食车(L) 6 矿石车(K) 7 冷藏车(B) 8
下载: 导出CSV
表 7 联机分析查询效率对比
查询实例 数据量 原有货运业务系统数据库查询时间 货运数据分析平台数据仓库查询时间 货票登记的整车装车重量与实际装车重量对比(需关联货票和货调系统数据) 2243.5 万行101.24 s 1.259 s 货票集装箱的计划重量与实际重量对比(需关联货票和集装箱系统数据) 2923.5 万行82.109 s 1.337 s
下载: 导出CSV
-
[1] 欧常春. 基于数据挖掘技术的铁路货运客户价值预测[D]. 成都:西南交通大学,2020. [2] 张玉琨. 基于K-Means聚类分析的电商学生客户细分研究[J]. 商场现代化,2022(8):33-35. DOI: 10.3969/j.issn.1006-3102.2022.8.scxdh202208014 [3] 戴昭颖,尹 涛,范文娟. 企业级MPP数据仓库选型探索[J]. 中国管理信息化,2018,21(9):45-47. DOI: 10.3969/j.issn.1673-0194.2018.09.020 [4] 巫东来,汤仕磊. 大数据及海量数据处理架构:Hadoop vs MPP[J]. 软件导刊,2020,19(10):218-222. [5] 林 木. 企业数据仓库平台的技术架构研究与设计[J]. 软件,2020,41(12):175-179. DOI: 10.3969/j.issn.1003-6970.2020.12.041 [6] 叶坚. 基于数据挖掘的铁路货运产品营销研究[D]. 成都:西南交通大学,2015. [7] 黎琮莹,周玉松. 基于雷达数据和朴素贝叶斯模型的道路养护区车辆轨迹预测[J]. 公路,2023,68(11):338-341. [8] 任 迪,万 健,殷昱煜,等. 基于贝叶斯分类的Web服务质量预测方法研究[J]. 浙江大学学报(工学版),2017,51(6):1242-1251. DOI: 10.3785/j.issn.1008-973X.2017.06.023













计量
- 文章访问数: 50
- HTML全文浏览量: 11
- PDF下载量: 17
