

Visual safety detection method based on improved YOLOv8 personnel detection model
-
摘要:
针对影响铁路接触网智能自轮运营维护装备车组(简称:运维车组)作业安全的人员侵入问题,提出了一种基于改进YOLOv8人员检测模型的视觉安全检测方法。以YOLOv8模型为基础,引入FasterNet Block、高效多尺度注意力模块(EMA,Efficient Multi-Scale Attention Module),学习跨空间聚合像素特征;针对单模型漏检,同场景下分别进行头部目标检测和身体实例分割,融合2个识别框,得到精确的识别结果;采用坐标转换法实现人员精准定位,确定人车距离并划分危险等级。该方法实现“识别—定位—预警”全流程,将其应用于智能运维车组中,通过对作业区域人员的检测定位,提升智能运维车组作业安全性。
Abstract:This paper proposed a visual safety detection method based on improved YOLOv8 personnel detection model to address the issue of personnel intrusion that affected the operational safety for intelligent self wheel operation and maintenance equipment vehicle sets (referred to as operation and maintenance vehicle sets) of railway catenary system. Based on the YOLOv8 model and introduced FasterNet Block and Efficient Multi Scale Attention Module (EMA), the paper learned cross spatial aggregated pixel features, focused on single model missed detection and performed head target detection and body instance segmentation separately in the same scene, fusing two recognition boxes to obtain accurate recognition results, and used coordinate transformation method to implement precise personnel positioning, determine the distance between people and vehicles, and classify the danger level. This method implements the entire process of "recognition - positioning - warning" and can be applied to intelligent operation and maintenance vehicle sets. By detecting and locating personnel in the work area, it improves the safety of intelligent operation and maintenance vehicle sets.
-
Keywords:
- YOLOv8 /
- object detection /
- instance segmentation /
- coordinate transformation /
- danger level
-
随着高速铁路的快速发展,接触网作为电气化铁路的重要组成部分,其零部件数量巨大、失效模式复杂多样,接触网智能自轮运营维护装备车组(简称:运维车组)的作用日益凸显,及时发现和杜绝运维车组周界人员入侵现象,对保障车组行车环境安全具有重要意义。
围绕运维车组作业安全性,针对影响铁路接触网运维车组作业安全的人员入侵问题,结合目标检测、实例分割、相机标定、坐标转换等技术,本文提出一种基于改进YOLOv8人员检测模型的视觉安全检测方法。该方法通过提取视频序列动态特征并建立目标检测模型,实现人员识别;使用相机标定技术,获取车顶工业相机内外参数矩阵;结合相机内外参数、工业相机坐标转换原理,实现人员定位,确定人车距离并划分危险等级。人员识别是将待测图像输入至已训练完成的目标检测模型,输出人员边界框;人员定位是采用相机标定法获取相机参数,并使用坐标转换法实现人员像素坐标与世界坐标的转换,涉及相机标定技术、坐标转换算法。目前,经典的相机标定方法[1-5]包括:Tsai的两步标定法、张正友的棋盘格标定法,后者解决了切向畸变问题,精度高、简单易标定;坐标转换算法基于针孔相机模型的像素坐标系[6]、图像坐标系、相机坐标系和世界坐标系的关系进行转换。
1 视觉安全检测系统设计
YOLO(You Only Look Once)目标检测和图像分割模型[7-14]自2015年提出以来,不断优化模型结构设计,在保持目标检测速度的同时,提升了检测精度;YOLOv8模型的改进内容包括主干网络、Ancher-Free检测头、损失函数,进一步提升了其性能和灵活性。
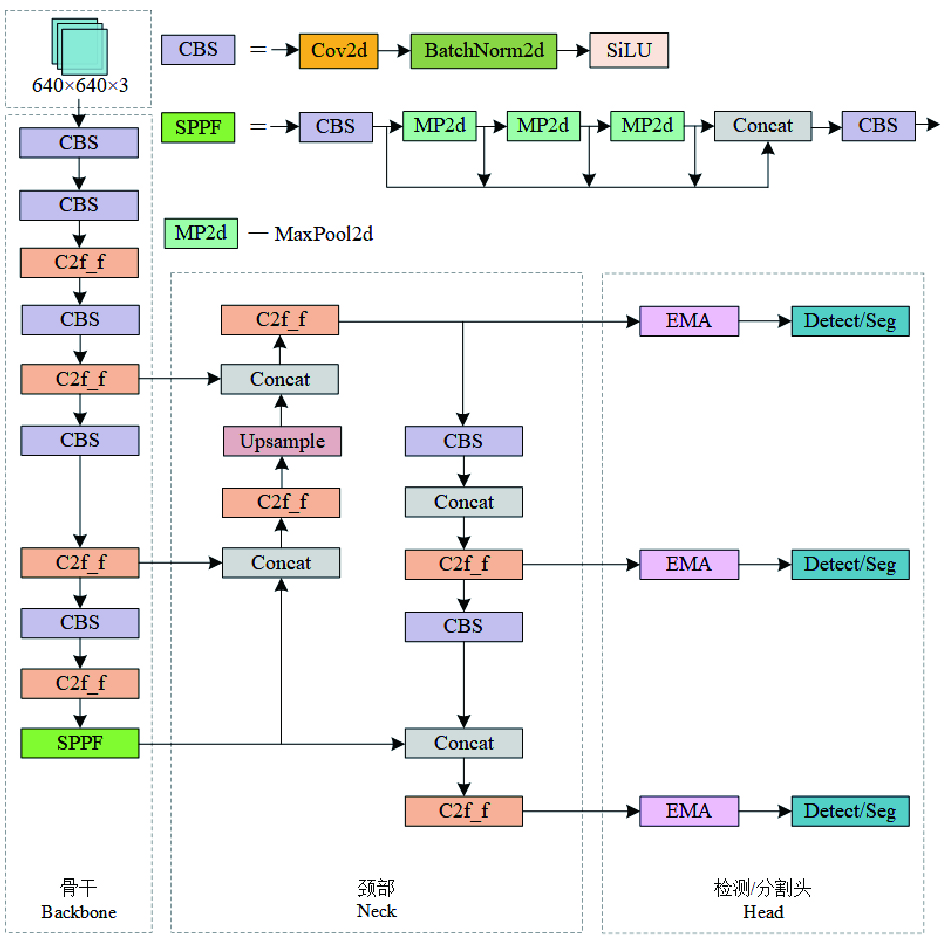
基于YOLOv8模型的视觉安全检测系统结构如图1所示。(1)使用工业相机采集智能运维车组周围环境图像,将其作为数据源;(2)人员检测识别模块实现同场景下人员头部目标检测、身体实例分割,通过融合2个识别框,得到精确的人员像素坐标;(3)人员定位模块利用相机标定法获取运维车组工业相机的内外参数矩阵,并结合坐标系转换关系完成人员定位;(4)安全预警模块根据人员定位信息,确定人车距离并划分危险等级。
2 视觉安全检测方法
2.1 图像数据采集与预处理
采用高分辨率工业相机进行数据采集,相机位置位于运维车组两侧,拍摄角度设置为−45°,主要采集车体两侧人员图像。剔除人员目标信息过少、图像模糊的图片,得到
1982 张图片;采用labelImg、Labelme标注工具对这些图片分别进行头部矩形框标注和身体多边形标注,将其作为目标检测、实例分割模型的数据源,并划分为训练集、验证集和测试集。为增强模型鲁棒性,对训练集部分图像使用±12°亮度、旋转±90°、模糊化等方法进行训练集扩充,其中,训练集和验证集占90%,测试集占10%,训练集和验证集比例为9:1,数据划分如表1所示。表 1 人员图像数据集样本信息单位:张 种类 初始数据集 增强数据集 训练集 验证集 测试集 总计 矩形框头部集 1982 2676 298 330 3304 多边形身体集 2609 290 322 3221 2.2 YOLOv8模型改进
YOLOv8模型可以进行人员的目标检测和实例分割。但考虑到实际应用场景要求目标检测性能、较高的检测速度均衡化,对YOLOv8模型进行了改进,得到改进后的YOLOv8人员检测模型,如图2所示。
对YOLOv8模型的改进点如下:(1)对于主干、颈部网络,使用FasterNet Block更新主干、颈部网络中C2f模块,在保证精确度的同时提升运行速度;(2)对于注意力机制,在每个检测分支前引入高效多尺度注意力模块(EMA,Efficient Multi-Scale Attention Module),跨空间聚合像素特征,提高网络的特征提取能力。
2.2.1 FasterNet Block模块
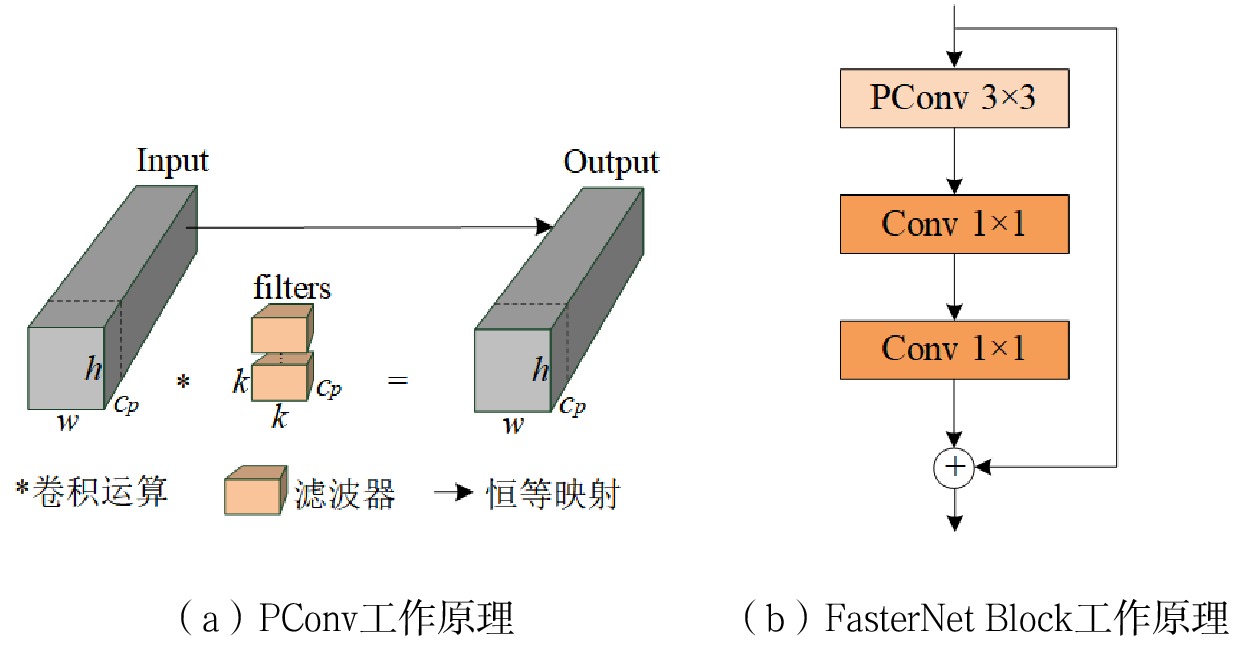
FasterNet Block是FasterNet[15]中核心模块,该模块引入PConv部分卷积算子,对输入特征图的部分通道应用卷积操作,保留其余通道不变,减少计算量和内存访问量,PConv工作原理如图3(a)所示。FasterNet Block包括1个PConv部分卷积层、2个1
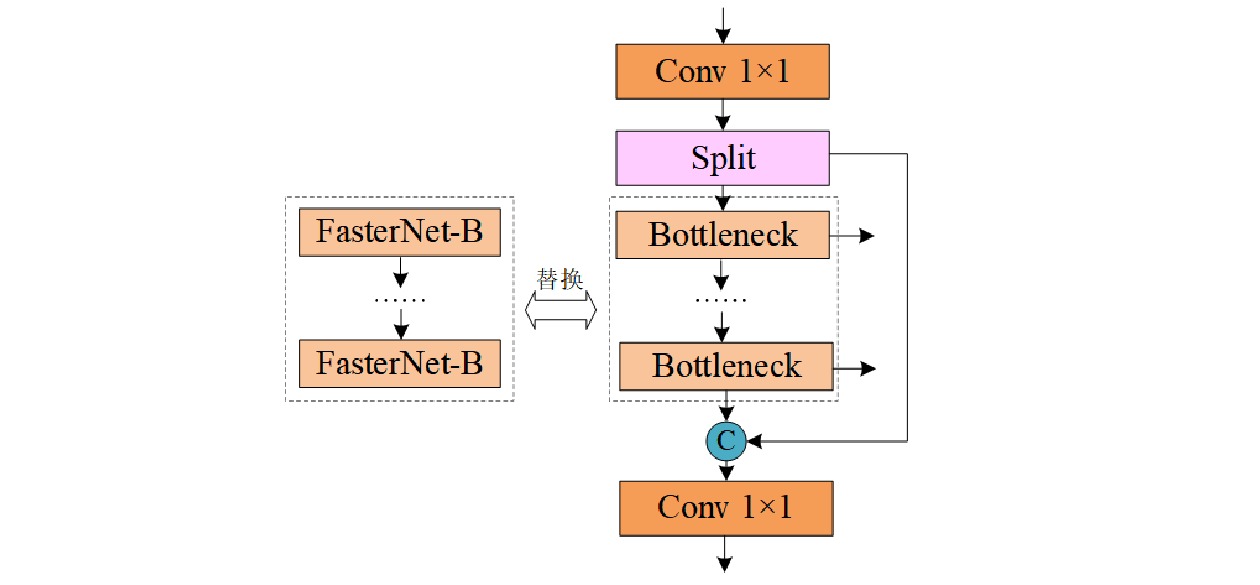
× 1卷积层,其工作原理如图3(b)所示。本文采用FasterNet Block替换主干、颈部网络中C2f模块的Bottleneck结构,改进位置如图4所示。
2.2.2 EMA
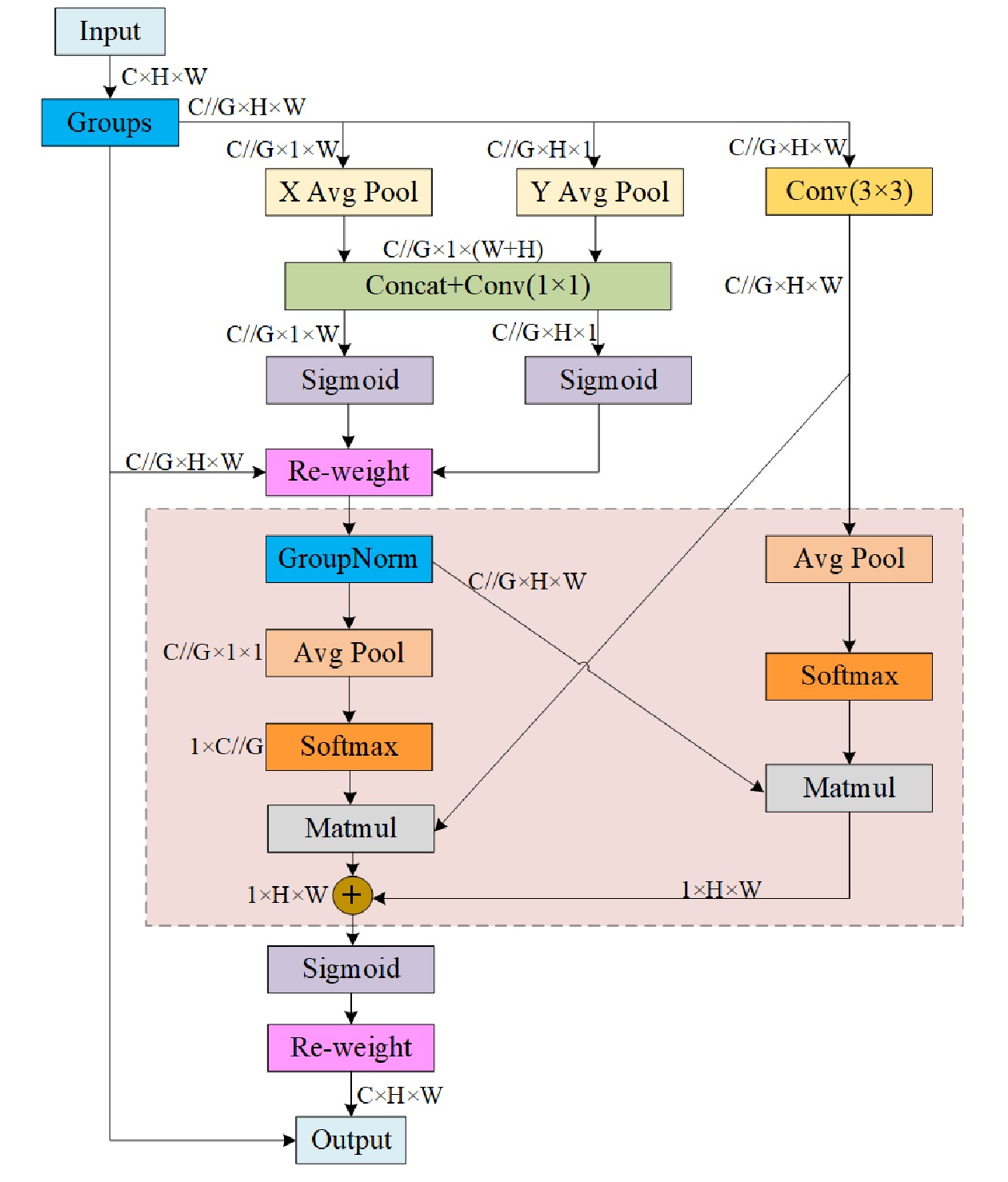
重构模型的主干、颈部网络后,算法的计算量得到了减少,但并未提升模型的准确度。因此,为了弥补网络轻量化造成的精度损失,在每个检测分支前增添EMA[16]。
EMA网络结构如图5所示。对于任何给定的输入特征图,EMA将其划分为跨通道维度方向G个子特征,以学习不同的语义;采用3个平行路径提取分组特征图的注意力权重,其中,X Avg Pool、Y Avg Pool、Conv(3
× 3)分别记为1× 1分支、1× 1分支、3× 3分支,2个并行的1× 1分支中通过一维全局平均池化操作,分别对水平、垂直方向通道进行编码,3× 3分支设置3× 3卷积进行多尺度特征提取。跨通道学习方面,将水平、垂直方向编码的2个特征相连接并共享1
× 1卷积;重新分解为2个向量后,采用Sigmoid函数进行线性拟合;使用乘法融合两方向通道注意力权重因子,实现1× 1分支间的跨通道特征交互。跨空间学习方面,采用二维全局平均池化将1
× 1分支和3× 3分支的输出编码至1× 1分支的输出中,接着对上述并行处理的输出进行点积运算,获取第一个空间注意力图;采用二维全局平均池化编码3× 3分支的全局空间信息,并与1× 1分支进行融合,获取第二个空间注意力图;将生成的2个空间注意力权重用Sigmoid函数进行线性拟合,计算出每组内的输出特征图。YOLOv8模型利用EMA的特征分组和多尺度结构,有效建立了短期和长程依赖,增强了网络信息提取能力,减少网络对人员的漏检。
2.3 目标检测和实例分割极大值融合算法
为了进一步提高人员识别精确度和检测网络的鲁棒性,分别使用头部矩形框和身体多边形框数据集对改进后的YOLOv8人员检测模型进行目标检测、实例分割训练,分别得到YOLO-head目标检测模型、YOLO-body实例分割模型,YOLO-head目标检测模型识别人员的头部,YOLO-body实例分割模型识别人员的身体。
极大值融合算法指的是在运维车组作业场景下识别人员时,将同一张图像同时输入至YOLO-head目标检测模型和YOLO-body实例分割模型,分别得到被检测人员头部目标检测结果和身体实例分割结果,将此结果进行极大值融合,即选择人数较多的检测结果作为下一流程的输入。通过YOLO-head和YOLO-body检测结果的极大值融合技术,改善由于背景复杂、人员相互遮挡等场景下单模型漏检的情况,从而提高视觉安全检测的精确度和鲁棒性。
2.4 人员定位技术
基于改进后的YOLOv8人员检测模型和极大值融合算法的联合使用,获取运维车组作业中两侧人员的像素坐标。为进一步求得人员实际位置,采用张正友的棋盘格标定法获取相机参数,结合坐标转换原理得到实际坐标。
2.4.1 工业相机标定
采用张正友的棋盘格标定法进行相机标定时,制作尺寸为
1.68 m×1.68 m 的6×6 棋盘格标定板,标定板图像如图6(a)所示;以运维车组主动力车单侧摄像头的标定为例,标定板位置如图6(b)所示,将标定板平行于车体放置,边缘角点重合于工业相机线和安全距离线的交点。该标定方法得到图像坐标系和世界坐标系的转换关系,并消除镜头使图像产生的图像畸变,其数学原理如式(1)所示。
\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\; {\boldsymbol{s}}=\left[\begin{array}{c}u\\ v\\ 1\end{array}\right]={\boldsymbol{A}}\left[\begin{array}{cc}{\boldsymbol{R}}& {\boldsymbol{t}}\end{array}\right]\left[\begin{array}{c}\begin{array}{c}{X}_{w}\\ {Y}_{w}\\ {Z}_{w}\end{array}\\ 1\end{array}\right]=\left[\begin{array}{ccc}{f}_{x}& 0& {u}_{0}\\ 0& {f}_{y}& {v}_{0}\\ 0& 0& 1\end{array}\right]\left[\begin{array}{cc}{\boldsymbol{R}}& {\boldsymbol{t}}\end{array}\right]\left[\begin{array}{c}\begin{array}{c}{X}_{w}\\ {Y}_{w}\\ {Z}_{w}\end{array}\\ 1\end{array}\right] (1) 式(1)中,s为尺度因子;R、t为相机外参数矩阵;A为相机内参数矩阵;u、v为目标点的像素坐标;(
{X}_{w} ,{Y}_{w} ,{Z}_{w} )为目标点的世界坐标。式(1)进一步转换得到相机坐标和像素坐标的对应关系,其数学描述如式(2)所示,其中,
{X}_{c} 、{Y}_{c} 、{Z}_{c} 为目标点在相机坐标系下坐标。\left[\begin{array}{c}{X}_{c}\\ {Y}_{c}\\ {Z}_{c}\end{array}\right]={\boldsymbol{s}}{{\boldsymbol{A}}}^{-1}\left[\begin{array}{c}u\\ v\\ 1\end{array}\right] (2) 2.4.2 坐标转换
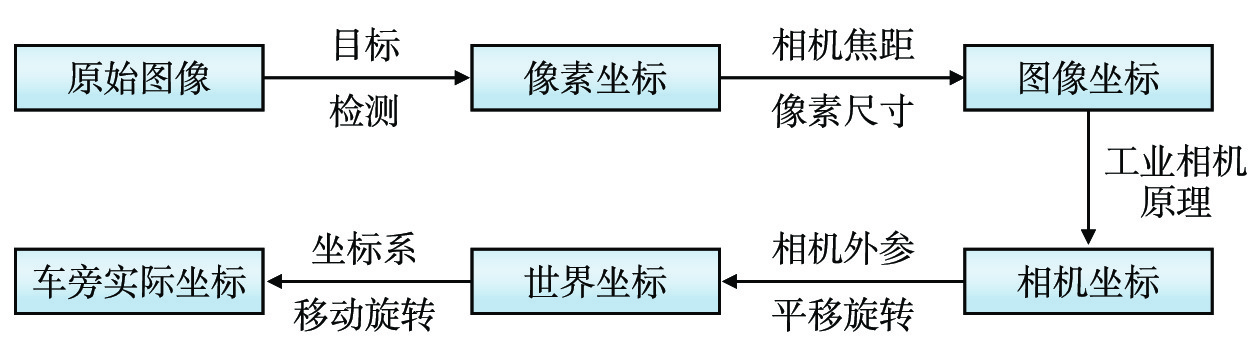
工业相机成像模型包含4个坐标系:像素坐标系、图像坐标系、相机坐标系、世界坐标系,不同坐标系间可相互转换[17],结合相机内外参数矩阵,将目标检测得到的人员像素坐标还原至车旁实际坐标,还原过程如图7所示。
基于改进后的YOLOv8人员检测模型,可得目标的像素坐标;运维场景下使用张正友的棋盘格标定法获取相机的内外参数和畸变系数,通过相机焦距和像素尺寸得到目标的图像坐标;图像坐标经相机成像原理得到目标的相机坐标;通过相机外参和平移旋转等操作,将目标的相机坐标转换为以边缘角点为原点的世界坐标
({X}_{W},{Y}_{W},0) ,结合安全距离{X}_{n} ,确定人员实际坐标\left({X}_{r},{Y}_{r}\right) ,数学关系如式(3)所示。\left\{\begin{array}{l}{X}_{r}={X}_{W}\\ {Y}_{r}={Y}_{W}+{X}_{n}\end{array}\right. (3) 2.5 安全预警
运维车组安全预警的技术路径是按人车距离确定危险等级。根据人员车旁实际坐标
\left({X}_{r},{Y}_{r}\right) ,确定人车实际距离Lr,两者数学关系如式(4)所示。当人车实际距离Lr\ge 安全距离Xn时,视为安全,否则危险,如图8所示。{L}_{r}={|Y}_{r}| (4) 3 试验结果与分析
3.1 模型训练与检测结果
试验环境采用Pytorch框架,Windows 11操作系统,32 GB显存的NVIDIA RTX-
3080 GPU显卡,处理器为AMD Ryzen9 5900HX with Radeon Graphics 3.30 GHz。训练参数设置为:输入图片像素尺寸为640×640,批次大小设置为24,训练轮次为500,不加载预训练权重,优化器为SGD(Stochastic Gradient Descent),关闭马赛克增强参数为10。评价指标包括平均精度均值mAP(mean Average Precision)、平均推理速度FPS(Frames Per Second),用于评价模型的精准程度和推理时间。其中,FPS指在模型测试时,将epoch设置为1得到总的推理时间,表达为
1000 ms/总的推理时间。为验证FasterNet Block更新C2f模块、EMA机制这2种改进策略对目标检测模型和实例分割模型的提升效果,分别在相同的数据集上进行消融试验,头部目标检测模型的消融试验结果如表2所示,身体实例分割模型的消融试验结果如表3所示。
表 2 目标检测消融试验结果对比模型 mAP_0.5 mAP_0.5:0.95 FPS/(帧·s-1) YOLOv8 88.2% 56.9% 43.85 YOLOv8+EMA 89.3% 59.2% 41.6 YOLOv8+C2f-Faster 89.0% 58.9% 39.84 YOLOv8+EMA
+C2f-Faster
(本文模型)
89.8%
60.4%
42.5表 3 实例分割消融试验结果对比模型 mAP_0.5 mAP_0.5:0.95 FPS/(帧·s-1) YOLOv8 91.1% 70.0% 49.51 YOLOv8+EMA 90.9% 69.3% 49.45 YOLOv8+C2f-Faster 91.8% 71.0% 48.27 YOLOv8+EMA
+C2f-Faster
(本文模型)
92.1%
73.3%
47.39根据表2可知,相较于单独策略改进,本文改进模型的人员识别效果最佳,对比改进前的YOLOv8模型,mAP_0.5提高了1.6%、mAP_0.5∶0.95提高了3.5%,虽然推理速度FPS减少了1.35 帧/s,但mAP_0.5∶0.95的涨点明显。
根据表3可知,对比其他策略,本文模型改进策略表现最佳,mAP_0.5提高了1%、mAP_0.5:0.95提高了3.3%、推理速度FPS降低了2.12 帧/s,mAP_0.5:0.95的涨点明显。
3.2 定位精度实验
定位精度通过以下步骤进行试验:(1)利用相机标定获取相机内、外参数矩阵和畸变系数;(2)使用坐标转换法进行固定点的像素坐标转换至运维车组两侧的实际坐标;(3)结合实地固定点实际坐标的测量数据,进行坐标转换的误差验证实验。
本实验选取了10个固定点进行坐标融合验证实验,对坐标转换算法准确性进行客观判断。如表4所示,坐标融合验证结果表明坐标转换误差≤5 cm。经过分析,造成误差的原因主要是包括以下3个方面:(1)在进行相机标定时,由于图像发生畸变,因此距离棋盘格标定板越远产生的误差越大;(2)在标定过程中产生的误差;(3)在数据实地采集时,进行摄像头位置的手工测量时产生的误差。
表 4 坐标验证结果编号 转换坐标/m 实际坐标/m 误差/cm 1 (1.83,1.72) (1.85,1.70) (2,-2) 2 (1.51,1.68) (1.55,1.70) (4,2) 3 (2.63,1.69) (2.60,1.70) (-3,1) 4 (2.32,1.68) (2.30,1.70) (-2,2) 5 (2.57,1.02) (2.60,1.00) (3,-2) 6 (2.08,1.03) (2.10,1.00) (2,-3) 7 (2.84,1.03) (2.80,1.00) (-4,-3) 8 (2.58,1.39) (2.60,1.40) (2,1) 9 (2.28,1.36) (2.30,1.40) (2,4) 10 (2.78,1.37) (2.80,1.40) (2,3) 综上所述,坐标转换误差验证,实验误差结果≤5 cm,说明坐标转换算法可实现人员像素坐标转换至运维车组两侧的实际坐标,人员定位精度满足运维车组安全检测要求。
4 结束语
针对影响铁路接触网运维车组作业安全的人员侵入问题,结合目标检测、实例分割、相机标定、坐标转换等算法,提出了一种基于改进YOLOv8人员检测模型的视觉安全检测方法。使用EMA和FasterNet Block,改进了YOLOv8模型,实验结果表明,改进后的目标检测模型和实例分割模型平均精度分别提高3.5%、3.3%;引入人头部目标检测模型结果和身体实例分割模型结果的极大值融合技术,实现了人员目标的准确识别;结合运维车组运维场景,利用坐标转换法实现了人员的精确定位,坐标融合实验结果表明,坐标转换误差≤5 cm内;根据人员实际坐标信息实现人车距离确定与危险预警,可满足现场实际工作需要,在一定程度上提高了铁路接触网运维安全保障水平。
-
表 1 人员图像数据集样本信息
单位:张 种类 初始数据集 增强数据集 训练集 验证集 测试集 总计 矩形框头部集 1982 2676 298 330 3304 多边形身体集 2609 290 322 3221  下载: 导出CSV
下载: 导出CSV
表 2 目标检测消融试验结果对比
模型 mAP_0.5 mAP_0.5:0.95 FPS/(帧·s-1) YOLOv8 88.2% 56.9% 43.85 YOLOv8+EMA 89.3% 59.2% 41.6 YOLOv8+C2f-Faster 89.0% 58.9% 39.84 YOLOv8+EMA
+C2f-Faster
(本文模型)
89.8%
60.4%
42.5
下载: 导出CSV
表 3 实例分割消融试验结果对比
模型 mAP_0.5 mAP_0.5:0.95 FPS/(帧·s-1) YOLOv8 91.1% 70.0% 49.51 YOLOv8+EMA 90.9% 69.3% 49.45 YOLOv8+C2f-Faster 91.8% 71.0% 48.27 YOLOv8+EMA
+C2f-Faster
(本文模型)
92.1%
73.3%
47.39
下载: 导出CSV
表 4 坐标验证结果
编号 转换坐标/m 实际坐标/m 误差/cm 1 (1.83,1.72) (1.85,1.70) (2,-2) 2 (1.51,1.68) (1.55,1.70) (4,2) 3 (2.63,1.69) (2.60,1.70) (-3,1) 4 (2.32,1.68) (2.30,1.70) (-2,2) 5 (2.57,1.02) (2.60,1.00) (3,-2) 6 (2.08,1.03) (2.10,1.00) (2,-3) 7 (2.84,1.03) (2.80,1.00) (-4,-3) 8 (2.58,1.39) (2.60,1.40) (2,1) 9 (2.28,1.36) (2.30,1.40) (2,4) 10 (2.78,1.37) (2.80,1.40) (2,3)
下载: 导出CSV
-
[1] Faugeras O D, Luong Q T, Maybank S J. Camera self-calibration: theory and experiments[C]//Proceedings of the Second European Conference on Computer Vision, 19–22 May, 1992, Santa Margherita Ligure, Italy. Berlin, Heidelberg: Springer, 1992. 321-334.
[2] 邱晓荣,刘全胜,赵 吉. 基于主动视觉的手眼系统自标定方法[J]. 中国测试,2018,44(7):1-6. DOI: 10.11857/j.issn.1674-5124.2018.07.001 [3] 刘伦宇. 高精度单目视觉定位技术及其在PCBA中的应用研究[D]. 重庆:重庆理工大学,2022. [4] 马 建. 基于机器视觉的工件识别与定位系统的设计与实现[D]. 沈阳:中国科学院大学(中国科学院沈阳计算技术研究所),2020. [5] Zhang Z. A flexible new technique for camera calibration[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22(11): 1330-1334. DOI: 10.1109/34.888718
[6] 杨鹿情. 基于单目视觉的室内移动机器人定位技术研究[D]. 上海:上海师范大学,2020. [7] Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 27-30 June, 2016, Las Vegas, NV, USA. New York, USA: IEEE, 2016. 779-788.
[8] Redmon J, Farhadi A. YOLOv3: an incremental improvement[DB/OL]. (2018-04-08)[2024-06-20]. http://arxiv.org/abs/1804.02767.
[9] Redmon J, Farhadi A. YOLO9000: better, faster, stronger[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 21-26 July, 2017, Honolulu, HI, USA. New York, USA: IEEE, 2017. 7263-7271.
[10] Bochkovskiy A, Wang C Y, Liao H Y M. Yolov4: Optimal speed and accuracy of object detection[C]// Proceedings of European Conference on Computer Vision (ECCV). Glasgow, UK, 2020, 10934.
[11] Zhu X K, Lyu S C, Wang X, et al. TPH-YOLOv5: improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision Workshops, 11-17 October, 2021, Montreal, BC, Canada. New York, USA: IEEE, 2021. 2778-2788.
[12] ZHENG GE, SONGTAO LIU, FENG WANG, et al. YOLOX: Exceeding YOLO Series in 2021[EB/OL]. (2022-12-23)[2024-06-20]. https://arxiv.org/pdf/2107.08430.pdf.
[13] Wang C Y, Bochkovskiy A, Liao H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 17-24 June, 2023, Vancouver, BC, Canada. New York, USA: IEEE, 2023. 7464-7475.
[14] Reis D, Kupec J, Hong J, et al. Real-Time Flying Object Detection with YOLOv8[EB/OL]. (2023-05-17)[2024-06-20]. https://arxiv.org/pdf/2305.09972.pdf.
[15] Chen J R, Kao S H, He H, et al. Run, don't walk: chasing higher FLOPS for faster neural networks[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 17-24 June, 2023, Vancouver, BC, Canada. New York, USA: IEEE, 2023. 12021-12031.
[16] Ouyang D L, He S, Zhang G Z, et al. Efficient multi-scale attention module with cross-spatial learning[C]//Proceedings of ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 04-10 June, 2023, Rhodes Island, Greece. New York, USA: IEEE, 2023. 1-5.
[17] 边 原,赵俊清. 智能识别与空间定位技术在高速铁路车站的应用研究[J]. 铁道运输与经济,2024,46(2):97-104. DOI: 10.16668/j.cnki.issn.1003-1421.2024.02.12.
















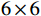


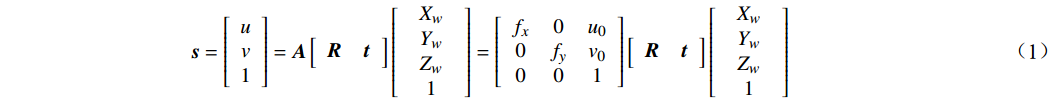
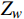
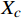
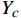
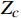

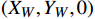
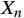
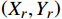

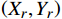
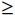

计量
- 文章访问数: 66
- HTML全文浏览量: 51
- PDF下载量: 37
