

Research on railway large vision model
-
摘要:
研究铁路计算机视觉大模型关键技术及其应用,对统筹和促进铁路人工智能发展具有深远意义。文章依托铁路人工智能平台的算力与大模型支撑组件,提出从基础大模型到铁路计算机视觉大模型,再到铁路计算机视觉场景大模型的架构设计思路。基于基础大模型,设计模型训练框架,运用模型剪枝和多尺度推理技术保障推理速度与精度,完成铁路计算机视觉大模型的构建;提出铁路计算机视觉大模型的应用场景,并选取线路环境安全管控智能识别场景对该大模型能力进行验证。实验结果表明,铁路计算机视觉大模型在复杂背景下的微小目标检测方面表现卓越,具有较好的应用前景,将在铁路运输安全、移动装备检测、铁路客货运服务等业务领域发挥更加重要的作用。
Abstract:Studying the key technologies and applications of railway large vision model has profound significance for coordinating and promoting the development of railway artificial intelligence. This paper relied on the computing power and large model support components of the railway artificial intelligence platform to propose an architecture design concept from the basic large model to the railway large vision model and then to the railway scenario large vision model. Based on a basic large model, the paper designed a model training framework, and used model pruning and multi-scale reasoning techniques to ensure inference speed and accuracy, implemented the construction of a railway large vision model. The paper also proposed the application scenarios of railway large vision model, and selected the intelligent recognition scenario of line environment safety management and control to verify the capabilities of this large vision model. The experimental results show that the railway large vision model performs excellently in detecting small targets in complex backgrounds and has good application prospects. It will play a more important role in railway transportation safety, mobile equipment detection, railway passenger and freight transport services, and other business domain.
-
目前,人工智能大模型的迅速发展引发了全球范围内的高度关注,视觉大模型的出现极大提升了图像理解和处理的能力。2020年10月, Alexey Dosovitskiy等人[1]提出了一种基于Transformer架构的视觉模型ViT(Vision Transformer),与传统的卷积神经网络(CNN,Convolutional Network)相比,ViT采用了全局自注意力机制对图像的语义信息进行建模,而不依赖于局部感受野,能够高效并行处理和捕捉图像的全局信息,提高了模型的灵活性和可扩展性;2021年3月,微软亚洲研究院研究团队[2]提出了用于计算机视觉任务的深度学习模型Swin Transformer,其核心思想是将输入的大尺寸图像分解为一系列较小的图像块,并通过自注意力机制对图像块之间的关系进行建模,可以有效处理大尺寸图像;华为技术有限公司研究团队[3] 于2021年4月提出的盘古视觉大模型,实现了模型的按需抽取,可以在不同部署场景下抽取出不同大小的模型,具有超强小样本学习能力;2022年5月,百度公司研究团队[4]提出的VIMER-UFO 2.0视觉大模型,在不进行下游微调的情况下,在28个主流的CV(Computer Vision)公开数据集上取得了优异的结果;2023年3月,商汤科技开发有限公司[5]提出了书生2.5大模型,在图像分类标杆数据集ImageNet上,仅基于公开数据,该模型便达到了90.1%的Top-1准确率;2023年4月,Meta[6]发布的图像分割模型SAM(Segment Anything Model),可以对不熟悉的场景及模糊情况下的未知物体进行分割,展示了视觉大模型的巨大潜力。计算机视觉大模型的快速发展在图像分析的精度和效率上取得了突破,然而在行业的垂直领域应用方面,由于特定行业数据的稀缺性和较高要求的专业性,目前的应用尚未形成规模化和标准化的解决方案,仅在个别领域成功应用[7-9]。
我国铁路行业积极推进人工智能、大数据、物联网等技术的研发与应用,开展铁路计算机视觉大模型研究,为铁路系统的智能化发展提供坚实基础,促进铁路人工智能技术与其他赋能技术的融合创新,有力支持我国智能高速铁路的建设[10-11]。
本文基于上述研究,结合计算机视觉大模型的通用能力及铁路行业的实际需求,研究铁路计算机视觉大模型。基于铁路智能平台,设计了铁路计算机视觉大模型架构;研究其关键技术及应用场景,完成铁路行业样本库的构建;开展相关研发实验,初步形成了具备智能检测与自动分析能力的铁路计算机视觉大模型,并在线路环境安全管控智能识别的场景中验证。实验结果表明,本研究提出的铁路计算机视觉大模型具有精度高、泛化能力强等优点,具备较好的应用前景。未来,铁路计算机视觉大模型将在铁路安全监控、设备维护、故障检测等多个领域发挥更加重要的作用。
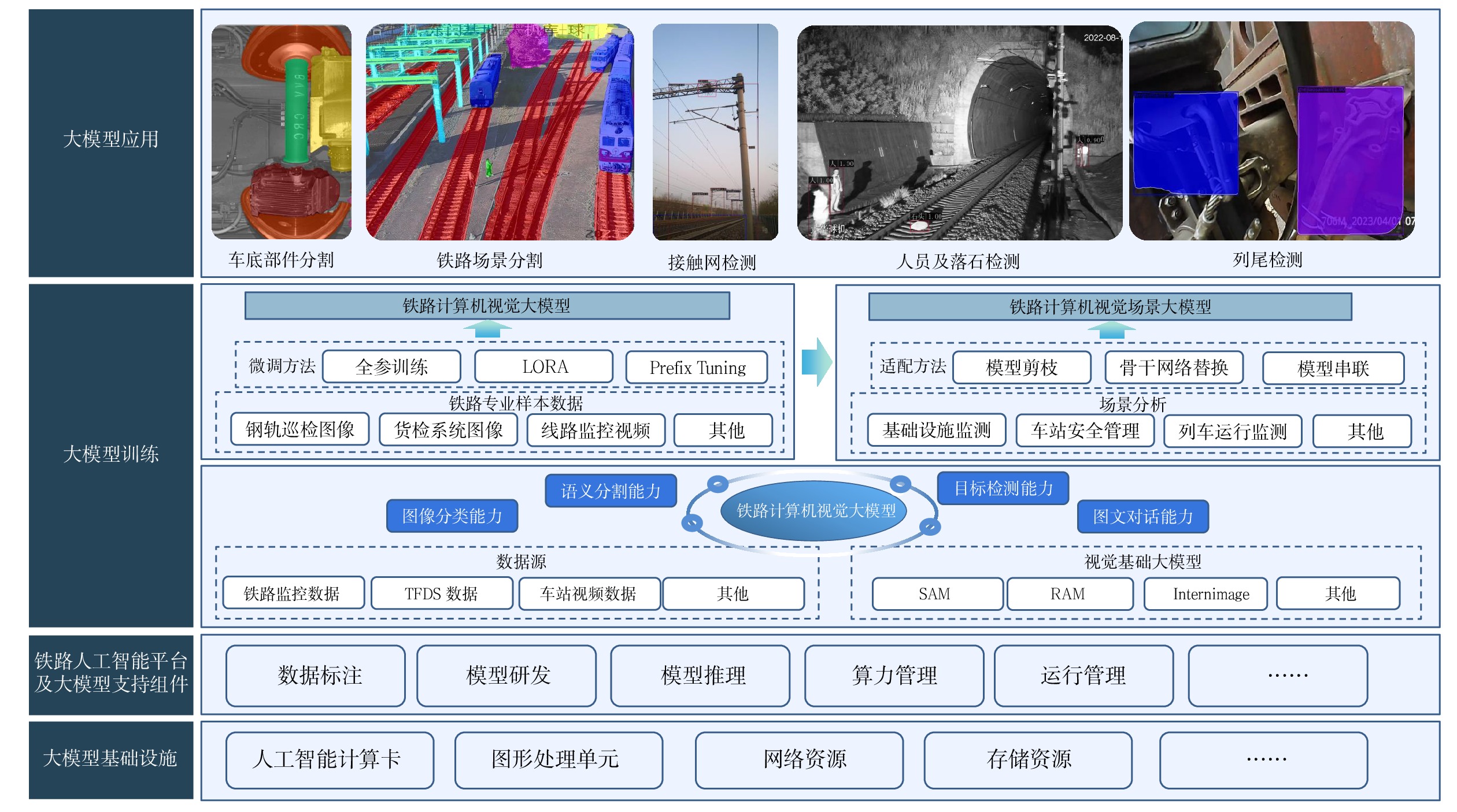
1 铁路计算机视觉大模型架构设计
基于铁路人工智能平台,铁路计算机视觉大模型架构如图1所示。
1.1 大模型基础设施
大模型基础设施是基于图形处理单元(GPU,Graphics Processing Unit)和人工智能加速卡构建的智能计算服务器集群。该基础设施涵盖人工智能算力、数据存储和网络通信等关键硬件设备。鉴于大模型训练过程中涉及大规模数据并行计算,因此,要求人工智能算力卡、通信网络和数据存储设备均应具备高算力和高能效的特性。
1.2 铁路人工智能平台及大模型支持组件
铁路人工智能平台及大模型支持组件(简称:平台及组件)专注于提供涵盖全生命周期的管理与服务,涉及数据标注、模型研发、模型评估、模型推理及服务维护等关键环节,旨在支撑大模型的构建与发展。其设计目标是应对计算机视觉领域内大模型对于大规模计算资源调度、个性化研发流程及海量数据处理需求的挑战,并提供相应的基础设施支持。在大模型训练过程中,平台及组件预先集成了优化算法,支持分布式训练环境下的并行运算与数据加速机制,同时,兼容多源异构大模型的集成框架[12];在模型推理服务过程中,平台及组件不仅提供推理加速机制、分布式部署方案,还具备模型压缩与剪枝功能,以确保大模型能够在分布式环境中高效稳定地执行推理任务;在大模型的实际应用层面,平台及组件提供了应用开发流程支持及用户界面设计,便于在线微调模型参数,并迅速生成适用于铁路行业的推理服务,从而为铁路系统的智能化升级提供坚实的技术保障。
1.3 大模型训练
1.3.1 数据源
用于训练铁路计算机视觉大模型的数据,主要包括铁路监控数据、货车故障轨边图像检测系统数据、车站视频数据、安检图像等,这些多样化的数据可为模型训练提供丰富的学习材料,有助于提高其在实际应用中的准确性和可靠性。
1.3.2 视觉基础大模型
通用视觉基础大模型包括开源基础大模型和商业基础大模型。开源大模型包括SAM、V-MoE、RAM(Recognize Anything Model)、Internimage等,可提供不同参数级别的模型。商业大模型包括CV大模型、VIMER-UFO 2.0、Miracle Vision大模型等。通常,模型规模越大,其泛化能力越强。通用视觉基础大模型具备强大的泛化能力,但缺乏行业深度,在铁路领域细分应用场景中难以提供高价值服务。
1.3.3 铁路计算机视觉大模型
针对铁路行业的多元化需求,深入剖析计算机视觉大模型在不同业务场景中的应用及其特定任务需求;依据实际需求构建铁路行业专属大规模数据集,为铁路计算机视觉大模型的训练提供丰富且高质量的数据资源;利用专业化数据集,实施相应微调策略,构建具备语义分割、图像分类、目标检测及图文对话等基本能力的铁路计算机视觉大模型。
1.3.4 铁路计算机视觉场景大模型
针对不同应用场景的特定任务需求,采用模型剪枝、骨干网络替换及大小模型串联等策略,以优化模型性能与资源利用率。如针对铁路基础设施监测,利用大模型进行轨道、桥梁、隧道等基础设施的健康状态监测,自动识别裂缝、腐蚀、变形等问题;针对列车运行状态监控,分析列车外观、关键部件(如车轮、制动系统)的状态,预测故障,提高列车维护效率;针对车站安全管理,通过人脸识别、行为分析等技术,加强车站区域的安全监控,有效预防和应对突发事件等。
通过模型剪枝,去除网络中不必要的权重或神经元,实现了在保证精度的同时降低计算成本;骨干网络替换,是根据任务特性选择最适配的网络架构,提升模型处理特定问题的效率与准确性;而大小模型串联的方式则充分利用了不同规模模型的优势,实现了从粗粒度检测到细粒度识别的无缝衔接,为铁路行业的智能化管理提供了更为灵活、高效的解决方案。
1.4 大模型应用
基于铁路人工智能平台的铁路计算机视觉大模型,可实现车底部件分割、铁路场景分割、接触网检测、列车尾部装置检测、人员及落石检测等铁路场景通用基础功能,提升整体铁路系统的智能化水平与安全保障能力。
2 关键技术
2.1 样本库构建
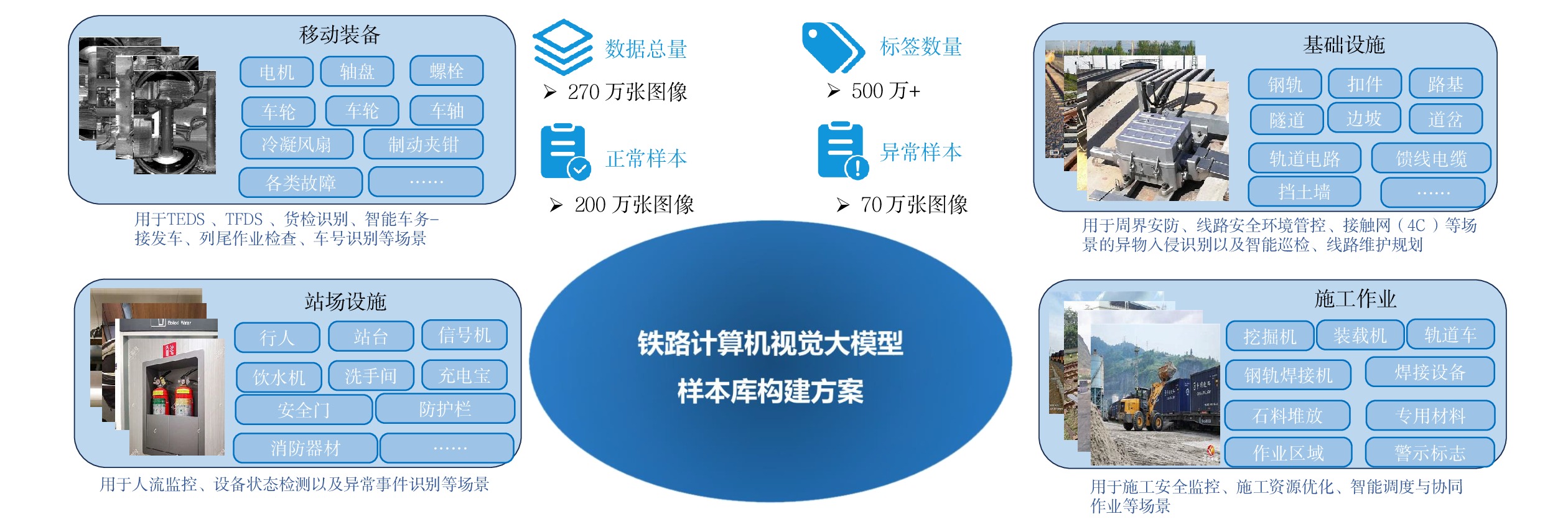
铁路计算机视觉大模型样本库的建设,旨在精准对接铁路领域大模型的样本需求,系统性地开展铁路行业数据的全面收集、精细整理、深度加工与严格标注工作。截至目前,样本库已汇聚的铁路专业数据图像覆盖了广泛的铁路应用场景,确保数据的质量与多样性,为铁路计算机视觉大模型的研发、训练与应用奠定了坚实的数据基础,有力推动了铁路行业智能化发展的进程。
2.1.1 数据收集
铁路计算机视觉大模型数据来源包括铁路内部运营数据、科研成果、专业教材、网络资源等,确保了数据的多样性和实用性。在数据分类上,样本库覆盖了铁路行业的4个关键领域:移动装备、基础设施、站场设施、作业施工,形成了一个全面的数据支持系统。铁路计算机视觉大模型样本库构建方案如图2所示。
2.1.2 标注类型
铁路计算机视觉大模型须实现铁路场景下的万物分割及目标检测,因此,采用多边形的标注方法对图像进行标注,能够对图像中的每一个像素进行分类,将其分配到对应的类别标签下。这种像素级的标注方式,使得铁路计算机视觉大模型能够细致理解图像内容,从而在铁路场景下实现全面的场景解析。在本文的研究中,标签涵盖了铁路轨道、车辆、基础设施等多个关键要素,确保了铁路计算机视觉大模型在复杂多变的铁路环境中仍保持精准的识别能力与分割能力。
2.1.3 标注方法
采用半自动化标注方法标注铁路计算机视觉大模型数据。选取图像清晰且类别较为明显的数据,利用labelme标注软件[13],采用人工标注方式;利用自动化标注工具X-AnyLabeling,对剩余图片进行自动标注,再进行人工复核,确保数据质量。
2.2 模型训练
微调方法在铁路计算机视觉大模型的优化过程中起着至关重要的作用。其中,数据增强作为提高其泛化能力和鲁棒性的关键技术,通过生成输入数据的多样化变体,扩展了训练集的多样性,使其能够学习更加通用和稳健的特征表示;全参训练技术,调整铁路计算机视觉大模型的所有参数,而非仅仅微调预训练模型的顶层,从而使其能够更好地适应新任务,尤其是在处理具有细微差异的铁路场景时,全参训练有助于捕捉这些细微变化,进一步提升其表现力;优化器选择,也是微调过程中不可忽视的重要环节,不同的优化器具有不同的优化策略和更新规则,适用于不同的训练场景和目标。在铁路计算机视觉大模型的微调阶段,选择合适的优化器能够显著加快训练速度,提高收敛精度,并减少过拟合的风险。
2.2.1 数据增强
(1)采用随机调整大小和裁剪技术,将图像的缩放范围设定在 0.5 ~2.0 倍,并随机裁剪图像尺度至 896×896(像素)。这一方法有效增强了铁路计算机视觉大模型对不同尺度物体的识别能力。
(2)图像以50%的概率进行水平翻转,提升铁路计算机视觉大模型对物体方向变化的适应性。
(3)通过光度失真技术,改变图像的颜色属性,增强铁路计算机视觉大模型在各种光照条件和色彩平衡变化下的鲁棒性。这些数据增强技术的综合应用,极大地提升铁路计算机视觉大模型在处理多样化真实世界视觉场景时的表现。
2.2.2 全参训练
全参数训练方法允许对铁路计算机视觉大模型的所有参数进行精细调整,使网络能够更好地适应特定的视觉任务。
(1) 采用预训练的基础大模型骨干网络,并对其进行定制化修改。通过集成可变形卷积网络v3,增强铁路计算机视觉大模型的特征提取能力。
(2) 通过允许所有参数在训练过程中更新,确保铁路计算机视觉大模型能够充分利用预训练知识,并适应新任务的特定需求。
2.2.3 优化器选择
优化器的选择对模型的训练效果至关重要。在针对铁路计算机视觉大模型的训练过程中,采用AdamW 优化器,其主要优势在于为每个参数提供自适应学习率,显著提高了训练效率。此外,AdamW 融合了权重衰减正则化,有效防止了过拟合问题。
针对铁路计算机视觉大模型,定制了一个专门的训练框架,允许对网络的不同层应用不同的学习率,具体而言,设置了50个层,层衰减率为 0.95。这种方法在深层架构中尤其有效,确保了更稳定的训练过程和更优的性能表现。学习率策略采用了多项式衰减并辅以线性预热,初始学习率设为2×10−5,预热迭代次数为1 500次。多项式衰减的公式为
$$ {\eta _t} = {\eta _{initial}}{(1 - \frac{t}{T})^\gamma }, $$ (1) 式(1)中,
${\eta _t}$ 是第 t次迭代的学习率,${\eta _{initial}}$ 是初始学习率,T是总迭代次数,$ \gamma $ 是多项式衰减的指数。线性预热则在训练初期逐步增加学习率,公式为$$ {\eta _t} = {\eta _{initial}} \cdot \frac{t}{{{T_{warmup}}}} $$ (2) 式(2)中,
${T_{warmup}}$ 是预热的总迭代次数。2.3 推理技术
2.3.1 模型剪枝
模型剪枝作为一种优化技术,通过移除神经网络中的冗余连接或神经元,降低模型复杂度,进而减少模型大小和计算量,提升推理速度。模型剪枝不仅在降低计算资源需求方面表现出色,还能在一定程度上提高模型的泛化能力和鲁棒性。模型剪枝通常分为非结构化剪枝和结构化剪枝。
非结构化剪枝关注单个权重或神经元的剪枝,不考虑网络的整体结构,这可能导致模型稀疏化,但不利于硬件加速;结构化剪枝是按照网络结构(如卷积核、通道、层)进行剪枝,保持模型的稠密性,便于硬件加速。
在针对铁路计算机视觉大模型的研究中,采用了一种迭代的结构化剪枝策略,具体步骤如下。
(1)权重重要性评估:使用L1范数评估每个通道的权重重要性,计算每个通道的L1范数,公式为
$$ {\left\| {{{\boldsymbol{W}}_{\boldsymbol{c}}}} \right\|_1} = {\sum _{i,j}}\left| {{{W}_{c,i,j}}} \right|, $$ (3) 式(3)中,
$ {\left\| {{{\boldsymbol{W}}_{\boldsymbol{c}}}} \right\|_1} $ 为第c个通道权重的L1范数,Wc为第c个通道上的权重矩阵,Wc,i,j是Wc的矩阵元素,i和j是空间维度索引。(2)通道筛选与移除:根据 L1 范数排序,识别出对模型输出影响较小的通道,逐步移除这些通道,公式为
$$ M = \left\{ {c|{{\left\| {{{\boldsymbol{W}}_{\boldsymbol{c}}}} \right\|}_1} < \theta } \right\}, $$ (4) 式(4)中,M是被移除的通道,
$\theta $ 是剪枝阈值。每次移除一定比例的通道后,进行微调(fine-tuning),以恢复模型的性能。损失函数仍采用交叉熵损失,公式为
$$ {L_{CE}} = - \sum_{k = 1}^C {{y_k}\log ({p_k})} , $$ (5) 式(5)中,
${L_{CE}}$ 是交叉熵损失,${y_k}$ 是真实标签,${p_k}$ 是模型预测概率。通过多轮迭代剪枝与微调,将模型参数减少了约42%,同时仅引起了2%左右的性能下降。2.3.2 多尺度推理
多尺度推理技术核心理念是利用图像在不同尺度下的特征进行预测,以提升模型的性能和准确性。在图像处理任务中,不同尺度的图像能够捕捉到不同的特征。例如,高分辨率图像能够捕捉到更多的细节信息,适合于识别图像中的小物体或者进行边缘检测;而低分辨率图像则包含更多的全局信息,适合于识别图像中的大物体。
为了保证铁路计算机视觉大模型的高泛化性,在测试流程中,将输入图像调整为多个尺度,并对每个尺度进行推理。
(1)多尺度缩放:生成若干不同分辨率的图像版本,假设有 S个尺度,每个尺度对应一个缩放因子i。
(2)水平翻转增强:对每个缩放后的图像应用水平翻转,生成两种变体。
(3)预测结果融合:将不同尺度和翻转方式下的预测结果进行融合,采用加权平均和非极大值抑制(NMS,Non-Maximum Suppression)技术,预测公式为
$$ \widehat p(x) = \frac{1}{{2S}}\sum_{i = 1}^S {\left[ {p(x;{s_i}) + p(x;{s_i},flip)} \right]} $$ (6) 式(6)中,
$p(x;{s_i})$ 是在尺度i下的预测,$ p(x;s_i,flip) $ 是在尺度${s_i}$ 及水平翻转下的预测,$\widehat p(x)$ 是最终融合后的预测。3 铁路计算机视觉大模型应用场景
3.1 铁路移动装备及部件识别
在涉及机车车辆及其关键部件维护的铁路场景下,涵盖从列车车体、电气设备等多维度的检测与评估工作,确保移动装备的安全稳定运行是保障铁路运输效率与安全的基础。应用铁路计算机视觉大模型,能够实现对装备部件的高精度识别和状态评估,如对列车底部是否存在风扇底板脱落、牵引拉杆挂异物、闸片丢失、齿轮箱漏油的检测等。铁路计算机视觉大模型优势在于其强大的数据处理能力和高度的自动化水平,能够处理大规模的视频流和图像数据,提供快速准确的分析结果,为铁路行业带来更高效、经济、自动化的监测和检查手段。
3.2 基础设施设备识别
铁路基础设施设备场景涉及轨道、电力及通信信号等设施设备的维护与监测,这些设施设备对于确保铁路运输的安全与效率至关重要。在此场景中,计算机视觉的需求主要体现在对铁路沿线安全环境的管控、接触网状态的识别、钢轨健康状况的精准识别与实时监测等方面。应用铁路计算机视觉大模型,能够高效处理和分析海量的视频图像数据,对沿线的关键基础设施如钢轨、轨枕、隧道、桥梁等进行精准识别、故障检测与异常预警,提升运营维护效率。
3.3 站场设施设备识别
在铁路站场设施设备管理场景下,涵盖从旅客服务到货物装卸及列车调度等多个环节,确保站内各类设备高效运行与安全管理至关重要,此环境中的计算机视觉需求聚焦于人流监控、设备状态检测及异常事件识别等方面。应用铁路计算机视觉大模型不仅能够在复杂背景中准确识别并分类站场内的各种设备状态,还能实现对人群行为模式的动态分析,及时预警可能存在的安全隐患或拥堵情况。此外,借助铁路计算机视觉大模型强大的自我学习能力,可进一步优化站场资源配置,提高应急响应速度与服务质量。
3.4 作业施工场景识别
在铁路建设与维修作业施工场景中,涵盖从线路铺设到桥梁检修及隧道维护等多项复杂任务,确保施工过程中的质量控制与安全保障成为核心挑战之一,此场景下的计算机视觉需求主要集中在施工安全监控、施工质量控制及施工进度管理等方面。应用铁路计算机视觉大模型,能够实现对施工现场的实时监控,自动识别施工人员的安全装备佩戴情况、施工设备的操作规范性、施工材料的质量状态,提供精准的分析结果,从而提高施工安全性和施工质量,优化施工流程,减少人为错误和事故风险。
4 应用实例
本文以铁路计算机视觉大模型在线路环境安全管控智能识别场景中的应用为例,验证其有效性。
采用铁路专业数据,在铁路计算机视觉大模型的基础上进行二次训练、模型剪枝等操作,形成铁路计算机视觉场景大模型,能够高效检测落石、擅自穿越的行人等,在技术层面实现了对铁路线路环境的智能化、精细化监控与管理。铁路计算机视觉场景大模型的构建过程主要包括样本标注、数据增强、模型训练、模型剪枝等。
4.1 样本标注
铁路计算机视觉大模型具备识别落石及行人的基础能力。收集线路环境安全管控数据共2 037张,先采用铁路计算机视觉大模型权重,利用X-AnyLabeling软件进行自动标注;针对黑夜、光晕干扰、小目标检测及极端天气条件等自动化标注的精准度受限的情况,再引入人工复核与精细标注机制。
根据实际应用情况,在夜间雨天天气中,雨滴的形状与远处落石的形态极为相似,样本实例如图3所示。
针对本场景,将雨滴标注为负样本纳入训练集,确保形成的铁路场景视觉大模型在实际部署时能有效区分并忽略雨滴误检,从而降低误报率,为铁路安全监控体系提供更为可靠的技术支撑。
4.2 模型训练
在铁路计算机视觉大模型的基础上,利用构建好的线路环境安全管控数据集进行模型训练,实验环境配置如表1所示。
表 1 实验环境配置硬件配置 型号/规格 CPU Intel(R) Xeon(R) Gold 5218 CPU @ 2.30 GHzGPU NVIDIA GeForce RTX 6000Ada 显卡显存 48 G 操作系统版本 Ubuntu 18.04.6 LTS CUDA 11.7 在模型训练的过程中,关键参数设置及其具体值如表2所示,综合考虑计算资源、数据集大小及模型大小,确定最大迭代次数为100,Batchsize为8。经过持续训练,最终在第85个Epoch时成功达到了最优模型的表现。
表 2 模型训练核心参数参数项 参数值 优化器 AdamW 优化器学习率 2e-05 优化器权重衰减 0.05 层衰减率 0.9 最大迭代次数 120 4.3 实验结果分析
为验证算法有效性,使用铁路计算机视觉大模型的基础能力对验证集效果进行验证;再利用相同的数据集,使用YOLOv8[14]、ViT-Adapter-L[15]、Faster R-CNN[16]模型进行训练并进行对比实验,以mAP50和mAP50:95指标进行评价,实验结果对比如表3所示。
表 3 实验结果对比模型类别 mAP50 mAP50:95 推理速度/(ms·张−1) 铁路计算机视觉大模型 87.42 70.91 357.5 铁路计算机视觉大模型(模型剪枝后) 85.35 65.81 201.7 YOLOv8 81.35 61.49 30.2 Faster R-CNN 66.31 39.94 68.2 ViT-Adapter-L 86.25 63.72 302.3 铁路计算机视觉场景大模型 94.64 77.48 341.5 铁路计算机视觉场景大模型
(模型剪枝后)92.85 75.61 198.7 由表3可知,尽管现有的铁路计算机视觉大模型已能够有效识别常规条件下的铁路场景物体,但在面对极端天气条件或需要识别微小物体时,其表现仍存在一定局限性,因此,对铁路计算机视觉大模型进行剪枝处理,优化资源使用效率。经过对比实验发现,优化后的铁路计算机视觉大模型尽管有部分性能下降,在检测精度上仍优于其他现有模型,并且推理速度显著提升。利用针对铁路线路环境安全管控的数据集对模型进行微调,形成铁路计算机视觉场景大模型。实验结果显示,铁路计算机视觉场景大模型在识别精度上有了显著改善,特别是在处理复杂背景下的微小目标检测方面表现优异。这一成果不仅验证了铁路计算机视觉大模型在实际应用中的有效性,同时也为其在恶劣天气条件下的鲁棒性提供了有力支持。
5 铁路计算机视觉大模型应用展望
铁路计算机视觉大模型作为铁路智能化转型的关键驱动力,代表着当前人工智能技术在铁路领域的又一重大突破,对深化铁路行业技术创新与智能化升级具有不可估量的价值。构建铁路计算机视觉大模型,不仅为铁路人工智能体系构筑了坚实的视觉感知基石,还极大地推动了铁路智能化发展的步伐及多领域技术的融合创新,通过深度学习与图像识别技术的融合应用,铁路计算机视觉大模型将助力铁路行业迈向更加智能、安全、绿色的未来。
5.1 大模型助力保障铁路运输安全
基于铁路计算机视觉大模型的强大泛化能力和在目标任务上的高精准性,可以实现在铁路运输系统中对可能威胁安全的目标进行实时检测与预警。铁路计算机视觉大模型不仅能够准确识别出轨道上的异物、违规侵入人员及其他潜在风险因素,还能够在复杂的环境中保持稳定的性能,确保及时发现并处理各类安全隐患。
5.2 大模型助力提升移动装备检测效率
铁路移动装备故障图像分析当前基本上仍依赖人工进行,工作强度大、分析效率低、运用成本高且容易出现对于关键故障的漏报,也给车辆运行安全带来隐患,借助铁路计算机视觉大模型,可以实现对铁路移动装备故障图像的自动化分析,能够快速、准确地识别出图像中的故障特征,并对其进行分类与定位。相较于传统的人工检测方式,自动化分析方法能够大幅度提高故障诊断的速度与准确性,减少由于人工疲劳或经验不足造成的误判风险。
5.3 大模型助力提升铁路旅客服务水平
铁路计算机视觉大模型在铁路旅客服务领域的应用,不仅是对基础物体的识别,更在于其能够基于这些识别能力,实现一系列高级的安全管理功能。铁路计算机视觉大模型已经能够识别铁路场景下的一般物体,基于此能力,可以实现对人员聚集区域的实时监测与预警,有效避免因过度拥挤而可能导致的安全风险。同时,对于携带危险物品的行为,本模型能够迅速捕捉并标记出潜在威胁,为安保人员提供及时、准确的干预信息。此外,在站台区域,本模型还展现出了对旅客行为模式的深度理解能力,能够精准识别可能引发安全事故的危险行为,如越界行走、靠近轨道边缘等,从而在第一时间发出警报,提醒相关人员采取必要的安全措施,提升铁路客运安全管理的主动性。
6 结束语
本文研究铁路计算机视觉大模型架构及其关键技术,并选取线路安全环境管控场景构建铁路计算机视觉场景大模型,证明了铁路计算机视觉大模型的有效性。铁路计算机视觉大模型依赖于持续不断的数据积累与模型迭代,只有收集更多样化、更高质量的铁路场景数据,并对其进行精细化标注,才能进一步优化和调整模型参数,使其具备更高精度的识别能力和更广泛的应用范围。未来的研究工作将致力于开发更加高效的数据采集方法与模型训练策略,以加速视觉大模型的学习过程,并确保其在不同铁路运营环境下的鲁棒性和泛化能力。
-
表 1 实验环境配置
硬件配置 型号/规格 CPU Intel(R) Xeon(R) Gold 5218 CPU @ 2.30 GHzGPU NVIDIA GeForce RTX 6000Ada 显卡显存 48 G 操作系统版本 Ubuntu 18.04.6 LTS CUDA 11.7  下载: 导出CSV
下载: 导出CSV
表 3 实验结果对比
模型类别 mAP50 mAP50:95 推理速度/(ms·张−1) 铁路计算机视觉大模型 87.42 70.91 357.5 铁路计算机视觉大模型(模型剪枝后) 85.35 65.81 201.7 YOLOv8 81.35 61.49 30.2 Faster R-CNN 66.31 39.94 68.2 ViT-Adapter-L 86.25 63.72 302.3 铁路计算机视觉场景大模型 94.64 77.48 341.5 铁路计算机视觉场景大模型
(模型剪枝后)92.85 75.61 198.7
下载: 导出CSV
-
[1] 孙露露,刘建平,王 健,等. 细粒度图像分类上Vision Transformer的发展综述[J]. 计算机工程与应用,2024,60(10):30-46. [2] Liu Z, Lin Y T, Cao Y, et al. Swin transformer: hierarchical vision transformer using shifted windows[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision, 10-17 October, 2021, Montreal, Canada. New York, USA: IEEE, 2021: 10012-10022.
[3] 吴锦浩,朱权洁,廖忠友,等. 基于盘古大模型的矿用钢丝绳表面损伤检测研究[J]. 工业控制计算机,2024,37(1):1-3,6. DOI: 10.3969/j.issn.1001-182X.2024.01.001 [4] Zhang C W, Yu X. Domestic large model technology and medical applications analysis[J]. Advanced Ultrasound in Diagnosis and Therapy, 2023, 7(2): 172-187. DOI: 10.37015/AUDT.2023.230027
[5] Wang W H, Dai J F, Chen Z, et al. InternImage: exploring large-scale vision foundation models with deformable convolutions[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 17-24 June, 2023, Vancouver, BC, Canada. New York, USA: IEEE, 2023: 14408-14419.
[6] Kirillov A, Mintun E, Ravi N, et al. Segment anything[EB/OL]. [2024-06-20]. https://arxiv.org/abs/2304.02643.
[7] 陈相羽,李 豪,王炳炎,等. 基于SAM预训练大模型智能化组合策略的燃料组件水下快速精确定位优化研究[J]. 核动力工程,2023,44(S2):140-145. [8] 刘金明,朱成波,周长义. 视频人脸识别技术在铁路人员管控中的应用[J]. 中国铁路,2019(4):99-103. [9] 李长泰,韩 旭,蒋若辉,等. 大模型及其在材料科学中的应用与展望[J]. 工程科学学报,2024,46(2):290-305. [10] 衣 帅,戴琳琳,阎志远,等. 基于机器视觉的铁路客运列车移动作业流程智能化提升方案[J]. 铁道运输与经济,2023,45(8):69-74. [11] 张晓栋,马小宁,李 平,等. 人工智能在我国铁路的应用与发展研究[J]. 中国铁路,2019(11):32-38. [12] 史天运,侯 博,李国华,等. 铁路人工智能平台设计及关键技术研究[J]. 铁路计算机应用,2023,32(8):9-16. [13] Russell B C, Torralba A, Murphy K P, et al. LabelMe: a database and web-based tool for image annotation[J]. International Journal of Computer Vision, 2008, 77(1-3): 157-173. DOI: 10.1007/s11263-007-0090-8
[14] Varghese R, Sambath M. YOLOv8: a novel object detection algorithm with enhanced performance and robustness[C]//Proceedings of 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems, 18-19 April, 2024, Chennai, India. New York, USA: IEEE, 2024, doi: 10.1109/ADICS58448.2024.10533619.
[15] Ranftl R, Bochkovskiy A, Koltun V. Vision Transformers for Dense Prediction[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision, 11-17 October, 2021, Montreal, QC, Canada. New York, USA: IEEE, 2021: 12159-12168.
[16] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.


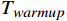

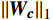

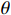
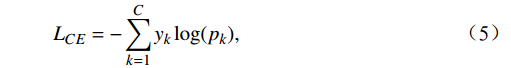
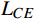
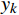
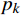
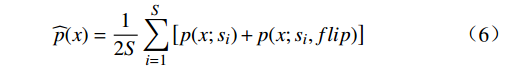
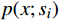
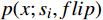
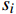
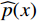

计量
- 文章访问数: 254
- HTML全文浏览量: 54
- PDF下载量: 96
