

Intelligent identification and classification and grading method of railway sensitive data based on hierarchical topic analysis
-
摘要:
为了对铁路不同敏感等级数据实施差异化保护,文章提出了一种基于层次化主题分析的铁路敏感数据智能识别与分类分级方法,旨在为铁路网络数据分级保护提供依据。该方法利用数据语义和分类分级规则建立主题词库,通过主题分析初步判断数据敏感级别。考虑到铁路网络数据的敏感级别分布不平衡,设计分级概率向量加权聚合机制,利用凝聚层次聚类算法实现准确定级。经实验验证,与基于语义和K-means聚类的传统主题分析方法相比,该方法可有效缓解分布不平衡问题,实现细粒度、动态可调整的铁路敏感数据智能识别与准确定级,从而为落实铁路网络数据分级管理要求、确保铁路网络数据安全可控提供技术支撑。
Abstract:In order to implement differentiated protection for railway data with different sensitivity levels, this paper proposed an intelligent recognition and classification and grading method for railway sensitive data based on hierarchical topic analysis, aimed to provide a basis for the grading protection of railway network data. This method utilized data semantics and classification and grading rules to establish a topic lexicon, and preliminarily determined the sensitivity level of data through topic analysis. Considering the uneven distribution of sensitivity levels in railway network data, the paper designed a graded probability vector weighted aggregation mechanism and used the cohesive hierarchical clustering algorithm to implement accurate grading. Through experimental verification, compared with traditional topic analysis methods based on semantics and K-means clustering, this method can effectively alleviate the problem of imbalanced distribution, implement fine-grained, dynamically adjustable intelligent recognition and accurate grading of railway sensitive data, and provide technical support for implementing the requirements of railway network data grading management and ensuring the security and controllability of railway network data.
-
随着智能铁路建设的不断推进,铁路网络数据规模高速增长,数据来源日趋多样[1]。海量数据的流通共享促进了数据价值的释放,但同时也对数据安全保护提出了更高要求[2]。铁路敏感数据识别和分类分级研究对落实铁路数字化转型、确保铁路网络数据安全可控具有重要意义。
目前,众多科研人员对数据敏感识别与分类分级工作开展了广泛研究。饶伟等人[3] 及宋树宝等人[4]探索了铁路数据分类分级规则制定和具体实施流程,然而人工依据规则定级存在主观性;李清欣[5]利用K-means聚类识别敏感字段,再用关联规则分析定级,但关联规则算法计算效率较低。因此,利用自然语言处理(NLP,Natural Language Processing)技术分析字段语义,并结合聚类算法确定敏感程度成为新的研究方向。彭剑峰等人[2]利用向量空间模型实现自动分类,但需要对大量字段进行人工标注;YANG等人[6]综合考虑了语义、句法和词汇信息来识别敏感数据;Gitanjali [7]提出了基于卷积的方法,利用数据中的非线性特征优化敏感数据的识别性能。然而,上述方法均难以应对真实业务场景中普遍存在的字段长度短、语义信息弱等问题。LI等人[8]提出的基于主题分析的方法突破上述限制,但由于其忽视了字段中不同敏感等级词单元的贡献差距问题,导致了对语义信息的利用产生偏差。
综上,虽然基于NLP技术的分类分级方法能凭借文本语义实现精准识别,但通常采用聚类分类结果直接作为敏感级别,定级准确性较差,且需要语料语义信息完整及大规模信息标注,缺乏实用性。因此,本文提出一种基于层次化主题分析的铁路敏感数据智能识别与分类分级方法(简称:本文方法),在语义信息和标注样本有限的情况下,实现对铁路敏感数据的准确识别与定级。
1 相关技术
本文方法利用NLP技术将字段拆分为词单元,结合分类分级知识构建主题词库;通过主题分析方法获取组成字段所有词单元的敏感级别,以计算字段分级概率向量;引入加权聚合机制缓解词单元等级分布不平衡问题,并利用层次聚类算法进行精确定级。其中,NLP技术和层次聚类算法是本文核心相关技术,距离度量方法可用于衡量数据与主题词的相似性。
1.1 NLP技术
NLP是一种通过计算机技术理解、分析和生成人类语言的技术。本文主要用到了其中的3个技术。
(1)Jieba分词:通过前缀词典将文本切分为具有意义的词汇,为文本处理提供基础。
(2)词频统计:通过构建词频表提取常见词汇,同时去除低频词,以降低模型复杂度,避免过拟合。
(3)Skip-gram模型:通过最大化中心词与上下文的条件概率来训练词向量,适用于大型语料库,可有效提升词向量质量。
1.2 聚类算法
1.2.1 K-means聚类
K-mean聚类算法基本思想是根据样本间距离将样本划分为
$ k $ 个簇,簇内样本间距离小,不同簇间样本距离大。K-means聚类算法核心步骤如下:(1) 确定
$ k $ 和最大迭代轮数,初始化簇质心;(2) 计算样本到各簇质心的距离,将样本划分到距离最小的簇中;
(3) 计算各簇内样本均值向量,并将该均值向量设为新的质心;
(4) 重复步骤(2)和(3),直至达到最大迭代轮数或质心偏移很小,输出聚类结果。
1.2.2 层次聚类算法
层次聚类[9-10],是一种基于树状结构进行数据聚类的算法,其基本思想是通过迭代地合并或拆分簇,来创建一棵反映样本间关系的树状图。本文采用凝聚层次聚类算法,其核心步骤如下:
(1) 每个样本点作为一个单独的簇,初始化时有
$n$ 个簇;(2) 计算所有簇之间的距离矩阵;
(3) 找到距离最近的2个簇,合并为1个新的簇;
(4) 在每次合并后,更新簇之间的距离矩阵;
(5) 重复步骤(3)和(4),直至只剩下目标数量的簇为止,输出聚类结果和树状图。
实践中,存在因不同等级的敏感数据分布差异而导致类不平衡问题,此时K-means聚类等算法倾向于将数据样本判别多数类以满足其最小化目标函数的需求,从而使得最终的簇分布趋向于平衡。层次聚类算法无需预先指定簇的数量或选择质心,仅基于簇样本间的距离或相似性来构建簇,使其在处理类不平衡数据时,不会像K-means算法那样受到质心位置和簇大小的影响。因此,层次聚类算法在初始化和聚类过程中具有更好的灵活性和鲁棒性,可在一定程度上缓解数据样本类不平衡问题,从而实现对敏感数据的可靠划分。
1.3 距离度量
1.3.1 欧式距离
欧式距离计算的是2个点在多维空间中的直线距离,直观反映出数据间距,数据点
$a$ 与$b$ 间的欧式距离为$$ {S_{Euclidean}}(a,b) = \sqrt {\sum\limits_{i = 1}^n {{{({x_i} - {y_i})}^2}} } $$ (1) 式(1)中,
$ {x}_{i} $ 、$ {y}_{i} $ 分别为数据点a、b的第i维特征;n为数据点维度。1.3.2 余弦相似度
余弦距离计算的是2个向量间的夹角余弦值,反映它们在向量空间中的相似度,数据点
$a$ 与$b$ 间的余弦距离为$$ {S_{cosine}}(a,b) = 1 - \frac{{\displaystyle\sum\limits_{i = 1}^n {{x_i}} {y_i}}}{{\sqrt {\displaystyle\sum\limits_{i = 1}^n {{x_i}^2} } \sqrt {\displaystyle\sum\limits_{i = 1}^n {{y_i}^2} } }} $$ (2) 2 铁路敏感数据识别与分类分级算法
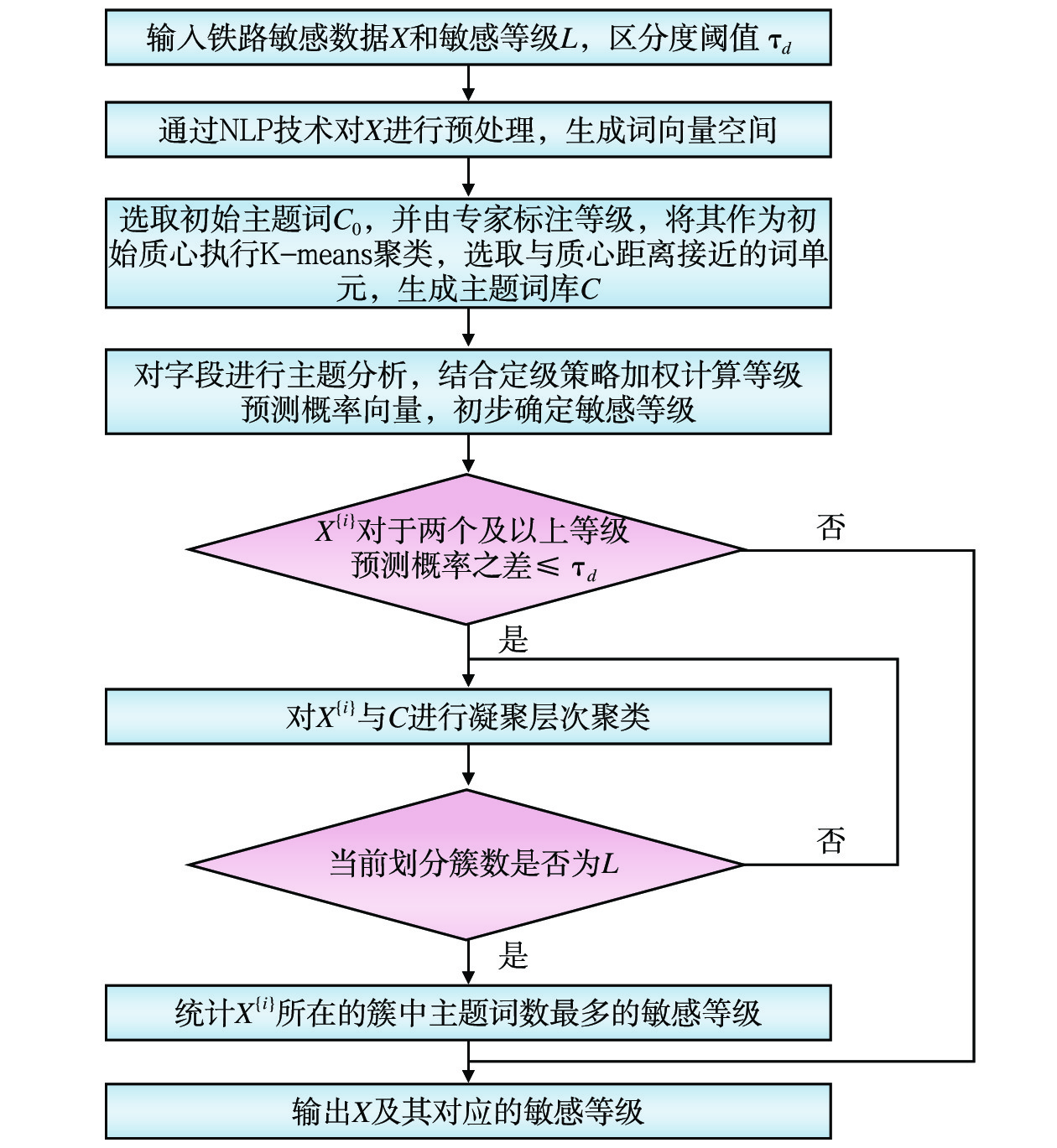
铁路敏感数据识别与分类分级算法步骤如图1所示,其中,
$ {X}^{\left\{i\right\}} $ 为铁路敏感数据X中的第i个数据点。(1)数据预处理,利用NLP技术提取数据字段语义信息,生成词空间向量;
(2)选取代表性词单元作为聚类质心,执行K-means聚类,构建主题词库;
(3)基于主题词库对字段进行主题分析,生成敏感等级初步预测结果;
(4)执行凝聚层次聚类算法实现准确定级。
2.1 数据预处理
提取每个铁路数据表的表头,将表头拆解为多个字段。采用NLP技术对铁路数据字段进行预处理,提取语义信息,构造词向量。例如,使用Jieba分词对铁路数据字段“拟接轨铁路线路名称”进行分词处理,选择合适的分词模式将字段切分成独立词单元(“拟”“接轨”“铁路”“线路”“名称”),并对分词后的结果进行词频统计,计算每个词单元在所有词单元集合中出现的频率(“拟”−47、“接轨”−
1134 、“铁路”−1245 、“线路”−1563 、“名称”−2459 )。根据设定的过滤阈值$ {\tau _f} $ ,去除词频小于该阈值的词单元以减少噪音数据的影响,提升分类分级性能。使用Word2Vec工具训练Skip-gram模型,通过预测给定词的上下文词来学习词的向量表示,生成捕捉词之间的语义关系的词向量空间。2.2 构建主题词库
对数据进行预处理后,根据专家的经验和行业规则,为每个等级选取少量有代表性的词单元作为初始主题词
${C_0}$ ,并通过层次分析法等方法标注主题词敏感等级。其中,初始主题词总量占词典总量比例不应超过2%,且各等级主题词的比例符合字段在各等级的分布。使用${C_0}$ 作为K-means聚类的初始质心,对全部字段语料向量直接进行聚类,聚类完成后,选取每一个簇中与质心最为相近的5个字段作为强代表性语料,将其具有的与本簇质心最相近的词单元补充进主题词,最终构建主题词库$C$ 。2.3 计算数据敏感等级预测概率向量
在词单元层面进行主题分析,再结合定级策略计算数据字段敏感等级预测概率向量。具体来说,先计算与每个词单元相似度最高的主题,按照不同等级主题出现的频率,生成该字段的初步敏感等级预测概率向量。例如,字段由5个词单元构成,其中有2个1级词、2个2级词、1个3级词,则初步预测概率为(0.4,0.4,0.2)。考虑到铁路数据敏感级别分布不平衡,结合定级策略对分级概率向量进行加权聚合并归一化处理,初步确定字段敏感等级。例如,制定加权策略,3级加权10倍、2级加权2倍、1级不加权,修正后的预测概率向量为(0.125, 0.25,0.625),则该字段初步定级为3级词。
2.4 通过层次聚类判定数据敏感等级
若字段对2个及以上等级预测概率之差≤
${\tau _d}$ ,即当预测概率向量无法以高置信度确定字段敏感等级时,利用层次聚类算法进一步判定数据敏感等级,否则将字段初步定级结果作为最终输出。具体方法为,对该字段语料向量和$C$ 进行凝聚层次聚类,使用合适的距离度量方式衡量字段向量与主题词的相似性,逐步合并最相似的簇,直到当前划分簇的数量等于敏感等级数量L。对于字段所在簇,统计簇中含有的2个或多个等级的主题词占比(只考虑概率接近的等级),输出占比高对应的等级作为字段的最终敏感等级。2.5 本文方法特点
本文方法和常规方案区别主要有以下方面。
(1)在语义信息利用方面,常规方案通常使用组成字段词单元向量的均值作为字段向量,但字段中不同词单元对字段敏感等级的贡献不同,仅使用均值向量会导致词单元信息难以被利用。本文基于主题分析判定词单元级别敏感程度,再计算字段敏感级别,实现语义信息的充分利用。
(2)在定级算法设计方面,常规方案直接对主题词进行K-means聚类,将字段向量距离最近的簇质心敏感级别作为字段敏感级别,因此字段定级主要依赖于最终轮得到的
$L$ 个质心(主题词),定级方式较为主观。本文采用主题分析初步确定字段敏感等级预测向量,对于区分度较低的字段再使用层次聚类算法判定最终敏感等级,具有较强的可解释性。(3)在处理字段敏感等级不平衡的问题方面,本文在构建主题词库阶段,根据字段敏感等级比例选取主题词,以避免分级方法对特定敏感等级主题的过度偏好或忽视;结合定级策略修正分级概率向量,旨在提升少数敏感等级字段定级的准确性;采用凝聚层次聚类算法进一步确定敏感等级,不会像K-means算法那样受到质心位置和簇大小的影响,具有更好的灵活性和鲁棒性。
3 实验与分析
为评估基于层次化主题分析的敏感数据识别与分类分级方法的效果,本文收集铁路敏感字段数据作为实验数据集,通过比较本文方法在不同权重、不同词频阈值下的总体准确率、各敏感等级准确率等指标上的表现,选定最优超参数。最终,将本文方法与基于语义分析和K-means聚类的传统主题分析法(简称:基线方法)进行对比与分析。
3.1 数据集构建
本文收集铁路敏感数据并采用NLP技术对其进行预处理,根据铁路数据分类分级要求,按照数据的重要程度将数据划分为一般数据、重要数据和核心数据,数据等级由低到高表示为1~3级,其中一般数据细化分级为S1~S4。由于细化一般数据分类分级流程与前述算法一致,因此在实验环节,以划分1~3级为例,构造铁路敏感数据集并标注各等级对应的数据量,如表1所示。
表 1 铁路敏感数据集各等级数据量数据名称 核心数据 重要数据 一般数据 数据等级 3 2 1 数据量/条 83 4848 40313 3.2 评估指标
3.2.1 敏感等级识别准确率
敏感等级识别准确率的公式为
$$ Accuracy = \frac{{{N_c}}}{{{N_{all}}}} $$ (3) 式(3)中,
$ {N_{all}} $ 为待分级数据的总数量;$ {N_c} $ 为正确分级的数据数量。3.2.2 混淆矩阵
混淆矩阵中的任意值
$C{M_{i,j}}$ 的定义为,真实标签属于第$i$ 类,且预测标签属于第$j$ 类的文本数量。混淆矩阵展示了模型预测结果与实际标签之间的关系,可帮助理解模型在哪些类别上表现良好,以及在哪些类别上可能存在问题。3.2.3 类召回率
对于某一个敏感等级
$i$ ,其类召回率的公式为$$ Recal{l_i} = \frac{{T{P_i}}}{{T{P_i} + F{N_i}}} $$ (4) 式(4)中,
$T{P_i}$ 表示真实敏感等级$i$ 中正确分级的数据的数量;$F{N_i}$ 表示真实敏感等级$i$ 中错误分级的数据的数量。类召回率主要关注于该类正确样本的检测能力,在不平衡数据集中,召回率(特别是对于少数类)可作为一个更有意义的指标。3.3 参数调试
本文方法需要预先指定词频过滤阈值
${\tau _f}$ 和加权系数,并选定适合的距离度量函数。本文针对不同的参数设置进行实验,分析实验结果并找出最优的参数配置。3.3.1 词频过滤阈值
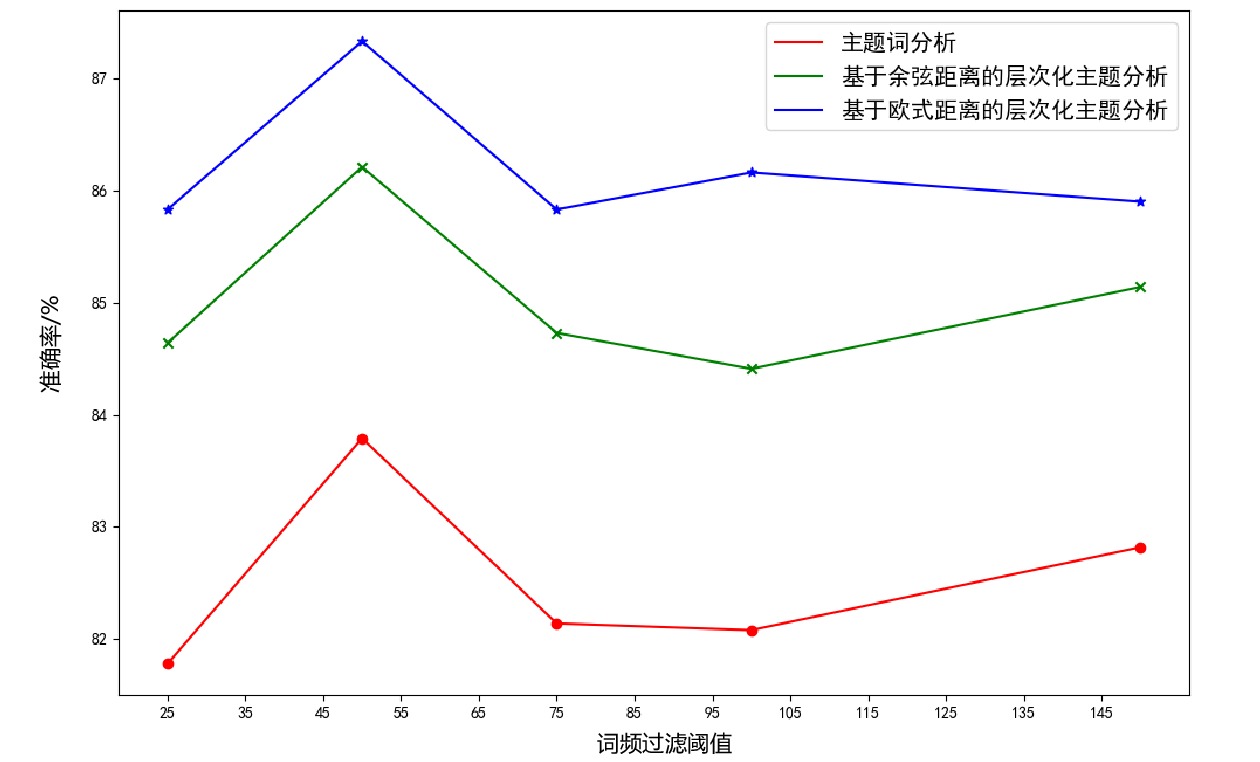
在使用NLP技术对铁路敏感数据进行预处理时,需要指定删去低频词的过滤阈值,不同的阈值设定会对方法的性能产生较大的影响。因此,本小节在词频过滤阈值为25、50、75、100和150时,分别对主题分析[8]、使用余弦距离的层次化主题分析、使用欧式距离的层次化主题分析这3个方法进行了敏感等级识别准确率的评估,实验结果如图2所示。
由实验结果可看出,3个方法的敏感等级识别准确率都在词频过滤阈值等于50时达到最高。因此,将词频过滤阈值设置为50,可达到相对最佳的识别效果。
3.3.2 距离度量函数
在机器学习算法中,距离度量函数的选取至关重要,不同的距离度量函数会对算法的性能产生显著的影响。本文分别使用余弦距离和欧式距离结合本文方法进行实验,实验结果如图2所示。由实验结果可看出,在选取任何词频过滤值的情况下,采用欧式距离方法的性能均优于采用余弦距离方法的性能。因此,选用欧式距离作为本文方法的距离度量函数更为合适。
3.3.3 加权系数
由于在字段中不同敏感等级的词单元对字段的敏感等级贡献不同,并且铁路数据敏感级别分布也较不均衡,因此,需要对归属于不同敏感等级的词单元对概率值的贡献进行加权。加权系数的选择是影响算法性能的关键因素。本文选取5组不同的加权系数(一般数据∶重要数据∶核心数据)进行实验,实验结果如表2所示。
表 2 不同加权系数的准确率与类召回率加权系数 敏感等级识别
准确率一般数据
召回率重要数据
召回率核心数据
召回率1:1:10 86.74% 94.21% 25.27% 77.14% 1:1.5:10 83.64% 89.56% 34.73% 77.14% 1:2:10 83.35% 89.21% 35.12% 77.14% 1:2.5:10 81.67% 86.43% 41.87% 77.14% 1:3:10 80.18% 84.58% 44.13% 77.14% 从表2可以看出,当重要数据的加权比例增大时,本文方法对重要数据的召回率会显著提高,但会牺牲部分一般数据的召回率,且使全部数据的敏感等级识别准确率降低。因此,本文方法可根据不同的定级策略,调整加权系数,权衡模型对不同敏感等级数据的倾向性。
由于在加权系数为1:1:10时,敏感等级识别准确率显著高于其他几组实验,因此,本文后续实验将在此配置下进行。
3.4 实验结果分析
根据3.3中给出的实验配置,测试本文方法和基线方法,实验产生的混淆矩阵如图3所示。
根据实验结果,计算出敏感等级识别准确率和各等级的类召回率,如表3所示。
表 3 本文方法与基线方法的准确率与类召回率敏感等级识别
准确率一般数据
召回率重要数据
召回率核心数据召回率 本文方法 86.74% 94.21% 25.27% 77.14% 基线方法 83.79% 89.21% 39.01% 67.47% 层次化主题分析的敏感等级识别准确率、一般数据召回率、核心数据召回率均优于基线方法,而重要数据召回率上的不足可根据3.3.3小节中对定级策略的倾向性不同,修改加权系数,弥补方法在重要数据识别上的缺陷。
综上,本文方法显著优于基线方法,并且提供了加权系数,引入了针对不同定级策略的算法可调节性,可灵活应用于不平衡的敏感数据。
4 结束语
本文提出一种基于层次化主题分析的敏感数据识别与分类分级方法,通过主题分析实现词单元敏感度定级,计算字段敏感分级概率并利用层次聚类算法进行修正。实验结果表明,本文提出的方法能有效缓解敏感等级分布不平衡对字段定级的影响,且支持定级策略的动态调整。受益于层次化主题分析的灵活性,本文提出的方法能够直接迁移到铁路重要系统数据分类分级现有技术方案内,对现有技术进行补强。此外,分类分级的输出可用于和铁路实际系统中信息表定级结果作对比,帮助分析和检查既有记录的敏感等级定级是否合理。由于层次聚类算法在计算复杂度和内存消耗方面存在局限性,下一步将考虑优化聚类阶段的效率,以提升大规模字段敏感识别和分类分级的处理时间。
-
表 2 不同加权系数的准确率与类召回率
加权系数 敏感等级识别
准确率一般数据
召回率重要数据
召回率核心数据
召回率1:1:10 86.74% 94.21% 25.27% 77.14% 1:1.5:10 83.64% 89.56% 34.73% 77.14% 1:2:10 83.35% 89.21% 35.12% 77.14% 1:2.5:10 81.67% 86.43% 41.87% 77.14% 1:3:10 80.18% 84.58% 44.13% 77.14%  下载: 导出CSV
下载: 导出CSV
表 3 本文方法与基线方法的准确率与类召回率
敏感等级识别
准确率一般数据
召回率重要数据
召回率核心数据召回率 本文方法 86.74% 94.21% 25.27% 77.14% 基线方法 83.79% 89.21% 39.01% 67.47%
下载: 导出CSV
-
[1] 王 喆. 铁路大数据治理体系研究[J]. 网络安全与数据治理,2022,41(11):30-35. [2] 彭剑峰,徐保民,张义祥. 基于等保2.0的铁路敏感数据安全关键技术及研究[J]. 网络安全技术与应用,2021(1):138-142. DOI: 10.3969/j.issn.1009-6833.2021.01.078 [3] 饶 伟,李碧秋,任宸莹,等. 铁路数据分类分级保护路径研究[J]. 铁道通信信号,2023,59(11):49-54. [4] 宋树宝,卢文龙,解亚龙. 铁路工程建设管理信息系统建设期数据分类分级研究[J]. 铁路技术创新,2024(2):13-20. [5] 李清欣. 铁路数据安全治理体系与隐私计算技术研究[D]. 北京:中国铁道科学研究院,2023. [6] Yang Z Q, Liang Z K. Automated identification of sensitive data via flexible user requirements[C]//14th International Conference on Security and Privacy in Communication Networks, 8-10 August, 2018, Singapore, Singapore. Heidelberg: Springer, 2018.
[7] Gitanjali K L. A novel approach of sensitive data classification using convolution neural network and logistic regression[J]. International Journal of Innovative Technology and Exploring Engineering, 2019, 8(8): 2883-2886.
[8] Li M, Liu J Q, Yang Y P. Automated identification of sensitive financial data based on the topic analysis[J]. Future Internet, 2024, 16(2): 55. DOI: 10.3390/fi16020055
[9] Moseley B, Wang J R. Approximation bounds for hierarchical clustering: average linkage, bisecting k-means, and local search[J]. The Journal of Machine Learning Research, 2023, 24(1): 1.
[10] Ghosal A, Nandy A, Das A K, et al. A short review on different clustering techniques and their applications[M]//Mandal J K, Bhattacharya D. Emerging Technology in Modelling and Graphics: Proceedings of IEM Graph 2018. Singapore: Springer, 2020: 69-83.
-
期刊类型引用(1)
1. 张德栋,冯凯亮,杨枭,高紫君,虞志杰. 面向雅万高铁的数据安全防护技术研究. 铁路计算机应用. 2025(03): 12-15 .  本站查看
本站查看
其他类型引用(0)
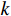

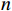
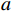
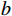
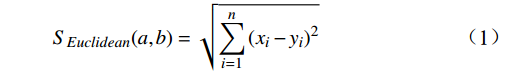
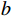
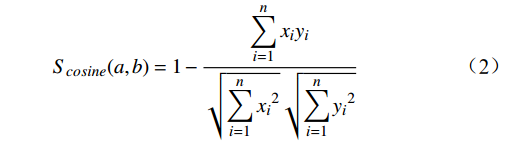
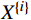
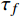
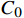
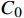

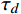

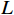

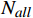
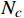
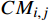
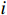
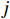
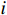

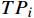
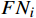
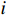
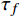

计量
- 文章访问数: 75
- HTML全文浏览量: 13
- PDF下载量: 29
- 被引次数: 1
