

Prediction model of dwell time for final arrival vehicle in railway freight yard
-
摘要:
为应对显著增加的铁路货运作业需求,提高铁路货运站场作业效率,在收集相关影响因素的基础上,设计了铁路货运站场车辆终到停留时间预测模型(简称:预测模型)。该模型通过统计数据,预测车辆出发空重状态,再根据出发状态预测终到停留时长。采用同时训练随机森林和BP(Back Propagation)神经网络、选取较优结果的方式构建3个子模型。通过数据验证,该预测模型的预测结果均方误差与平均绝对误差均优于仅使用随机森林算法或BP神经网络算法的模型,能够有效预测车辆终到停留时间,为货运站场作业计划安排和作业效率分析提供技术支撑。
Abstract:To cope with the significantly increased demand for railway freight operations and improve the efficiency of railway freight yard operations, this paper designed a prediction model of dwell time for final arrival vehicles in railway freight yard based on the collection of relevant influencing factors. This model predicted the empty and heavy status of the vehicle's departure based on statistical data, and then predicted the duration of stay. The paper constructed three sub models by simultaneously training a random forest and a BP (Back Propagation) neural network, and selecting the optimal results. Through data verification, the mean square error and mean absolute error of the prediction model are superior to models that only use random forest algorithm or BP neural network algorithm. It can effectively predict the dwell time for final arrival vehicle and provide technical support for the planning and efficiency analysis of freight station operations.
-
近年来,铁路货运数字化建设迅猛发展,货运站场作为铁路货物运输的关键节点,其管理能力和服务能力得到了较大提升。山东京博物流股份有限公司铁路专用线、长沙北物流园、改貌物流基地等均对货运站场智能化进行了新的探索。与此同时,针对铁路物流服务需求和铁路货运管理需求的研究也吸引了大批学者。途中站车辆停留时间预测[1]、调车作业时间预测[2]、货物装卸时间预测[3]等众多场景的作业时间预测对帮助作业计划制定、满足客户需求、分析货运站场作业效率、挖掘作业潜力等具有重要作用 [4]。
车辆终到停留时间(简称:终停时)是从车辆到达货运站场开始,经历货物装卸、等待、站内调度等作业后离开货运站场的总时长,车辆在货运站场经历了一系列的作业,其总时长从整体上反映了货运站场的作业效率。当前多采用统计的方式对终停时进行研究[5-6],权诗琦等人[7]针对邯郸站货运车辆停留时间进行分析,给出货运车辆在该货运站场压缩停留时间的优化措施;杨廷宇等人[8]设计了列车在站技术作业时间写实管理信息系统,对列车在站技术作业时间进行管理,从而解决部分列车习惯性晚点的问题。当前,我国各铁路货运站场的设施设备情况、装车和卸车需求、人员组织情况等均有不同,其作业效率瓶颈也有不相同,因此,简单的统计分析方式已无法满足货运作业效率分析和货主对铁路运输服务的需求。
综上,本文基于随机森林和BP(Back Propagation)神经网络算法,构建了铁路货运站场车辆终到停留时间预测模型(简称:预测模型),对终停时进行较为准确的预测,从而为铁路相关部门进行货运计划安排和货运作业效率分析提供了技术支撑。
1 相关算法
1.1 随机森林算法
随机森林是一种高度灵活的机器学习算法,可用于解决分类和回归问题[9],该算法通过有放回抽样的方式将数据集划分为多个子数据集,再用每个子数据集训练1个决策树[10]。在进行分类或回归预测时,将每个决策树的预测结果求平均或投票,形成最终的预测结果[11]。本文选用随机森林算法作为构建预测模型的基本算法之一,主要考虑到其具有较强的泛化能力和较快的训练速度,并能保证较好的预测效果。
1.2 BP神经网络算法
人工神经网络是一种可用于解决回归问题的仿照神经元网络运行方式构建的数学模型[12]。BP神经网络是一种采用了基于误差逆向传播算法的浅层前馈神经网络[13],网络结构主要包括输入层、隐含层和输出层,通过训练调整各个神经元间的权重,使得输出结果尽可能接近目标值。考虑到BP神经网络算法具有的自学习、自适应和容错性高等优点[14],本文也将其选为构建预测模型的基本算法,便于进行模型训练。
2 预测模型设计
2.1 影响因素收集
终到车辆在货运站场的货运作业主要是货物的装卸、站内调度、车次安排等。与货物装卸相关的信息有货物运单信息和装载清单信息,主要包括货物重量、货物品名、发货人、收货人、车号、箱号、始发站、终到站、始发站隶属局、终到站隶属局、运输方式等影响因素。由于车辆在终到的货运站场可能会再次装车后才出发,因此,再次出发时的货物信息等也是终停时的影响因素,为了与车辆到达时货物信息有所区别,本文采用再次出发到站、再次出发货物品名等名称来表示。此外,车辆再次出发时,出发状态是否为重车也是终停时的影响因素之一。与站内调度、车次安排等相关的信息是终到运统一信息和始发运统一信息,主要包括到达时间、出发时间、车号、车种、车辆自重、车辆载重等影响因素。
2.2 出发状态分析
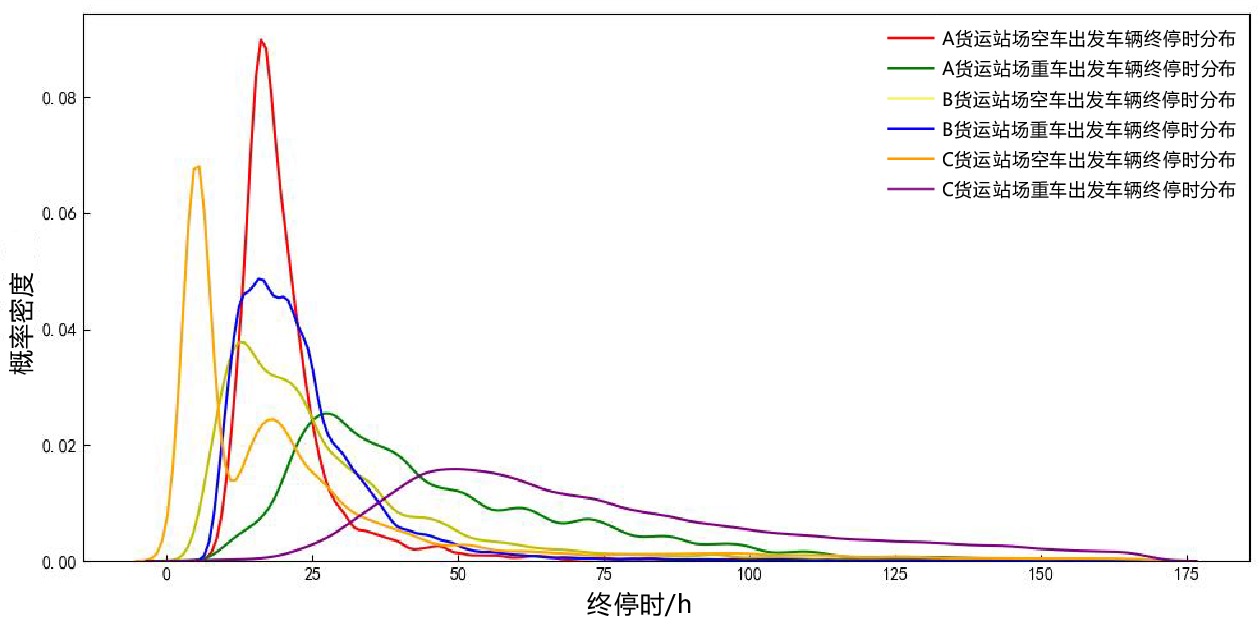
与重车相比,出发状态为空车的车辆作业流程中缺少装车环节,调度等待等作业流程情况也稍有不同。本文随机选取3个货运站场,统计了不同出发状态下车辆的终停时分布情况,如图1所示。从图1中可以看出,部分货运站场空车和重车2种出发状态下车辆的终停时分布区别较大,部分货运站场不同出发状态下车辆的终停时分布区别较小,但仍存在区别。因此,可分别设计重车出发终停时和空车出发终停时的预测模型,然后组合构建本文的预测模型。
2.3 模型设计
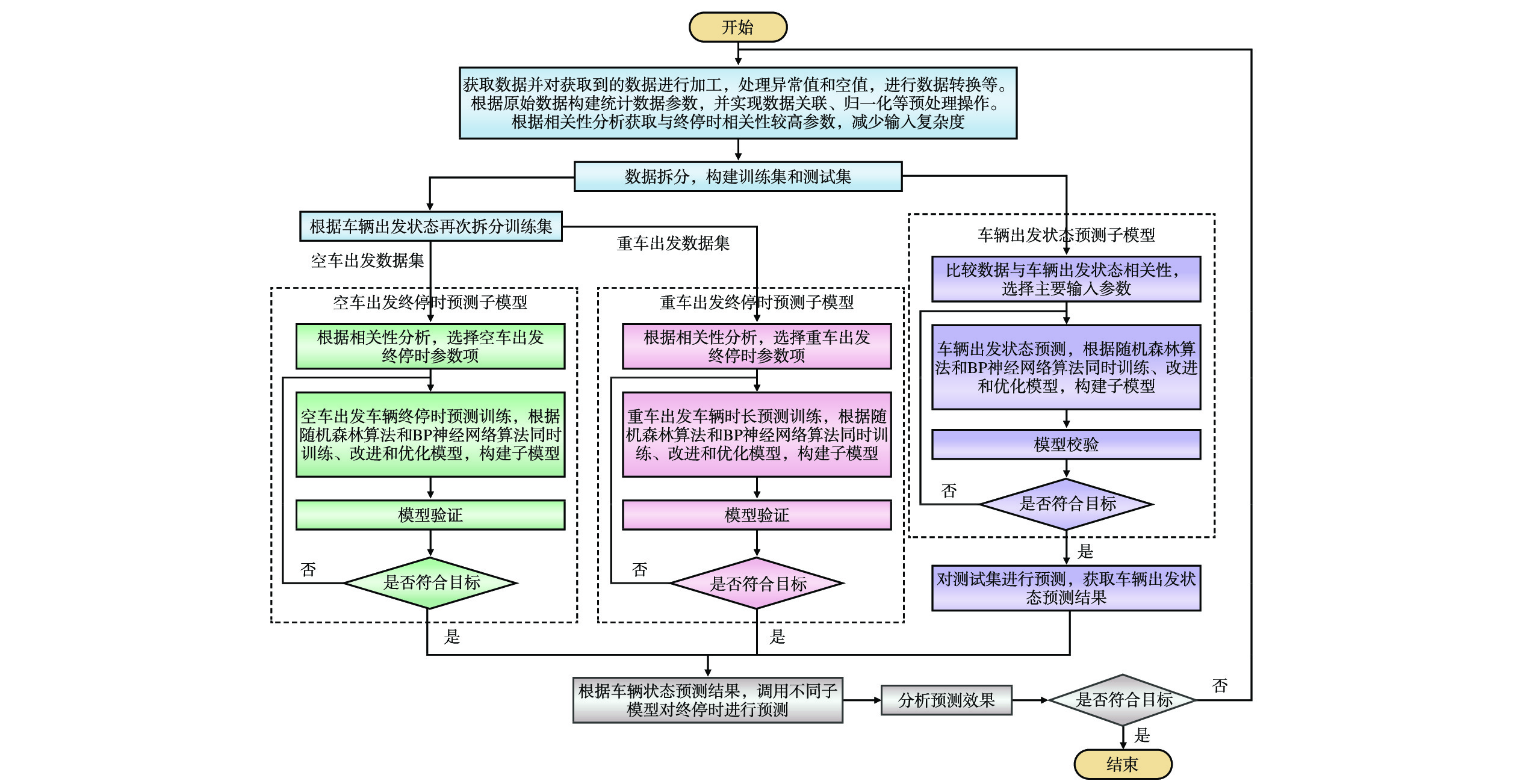
由于车辆出发状态的不同会较大程度地影响车辆终停时,本文设计了空车出发终停时预测、重车出发终停时预测和车辆出发状态预测等3个子模型。针对每个子模型,将整体数据拆分为子模型的训练数据和验证数据。每个子模型均采用随机森林算法和BP神经网络算法,使用相同数据进行训练,在2个算法训练完成后,通过比较预测准确度,选择预测效果较好的子模型作为训练结果。在每个子模型训练完成后,通过测试集验证预测效果,并再次调整子模型超参数,以获得模型的最优解。
2.4 模型构建与训练流程设计
本文研究的终停时预测场景为一般车辆在重车状态到达货运站场,经历一系列作业后,以重车或空车状态出发所经历的时长。对车辆故障维修、车辆出境未归、车辆长期放置不用、运统一数据遗漏等情况导致的不完整数据都进行遗弃处理。预测模型构建与训练流程如图2所示,具体步骤如下。
(1)选择目标车站,收集作业数据,并对数据进行处理加工,包括异常值和空值处理、始发空重状态构建、时间参数处理、分类数据编码等操作。根据原始数据构建统计数据参数,包括车站日终到车数、日始发车数等信息。对数据集进行关联和归一化处理后,进行数据相关性分析,获取与终停时相关性较高的参数构建基础数据集。
(2)拆分基础数据集,形成训练集和测试集。
(3)用处理后的训练集训练并优化车辆出发状态预测子模型。主要步骤是:比较数据与车辆出发状态相关性,选择主要输入参数;再次拆分其训练集和测试集。基于训练集,采用随机森林算法和BP神经网络算法同时训练、改进和优化该子模型。通过测试集对其进行校验,如果不符合目标,则重新使用训练集进行训练;若符合目标,则完成训练。
(4)在进行车辆出发状态预测子模型训练的同时,将训练集根据出发车辆的空重状态拆分为2个训练集。
(5)利用空车出发训练集,以终停时作为输出,通过相关性分析对输入参数进行降维操作后,采用随机森林算法和BP神经网络算法进行训练、改进和优化,构建空车出发终停时预测子模型。
(6)利用重车出发训练集,以终停时作为输出,通过相关性分析对输入参数进行降维操作后,采用随机森林算法和BP神经网络算法进行训练、改进和优化模型,构建重车出发终停时预测子模型。
(7)通过出发车辆状态预测子模型对测试集进行预测,获取车辆出发状态预测结果。
(8)根据步骤(7)的预测结果,调用对应出发状态的子模型对终停时进行预测,形成终停时预测结果。
(9)对终停时预测的结果进行分析。如果预测结果不符合目标,则需要返回步骤(1)重新调整输入参数,再次对模型进行训练。如果预测结果符合目标,则流程结束。
2.5 超参数调优
超参数调优主要是指通过模型训练获取可接受的基础算法的超参数。主要包括设置算法超参数、设置网格搜索参数、算法训练、比较最优解等步骤。比较最优解主要是用测试集在训练好的模型上测试,用测试获得的预测值与实际值作比较。当预测效果可以接受时,流程结束;若无法接受预测效果,就重新调整超参数后再次训练。其中,随机森林算法的超参数为决策树个数(n_estimators)和最大分离特征数(max_features);BP神经网络算法的超参数为隐藏层节点数和隐藏层数量(hidden_layer_sizes)、激活函数(activation)、模型复杂度控制因子(alpha)。
3 模型构建与训练实例
本文采用Python语言和PyCharm工具进行模型构建与训练。
3.1 数据集获取与处理
采用某货运站场2019年7月至2022年12月的作业数据作为数据集。并对数据集进行包括异常数据处理、空值参数加工、统计数据构建、时间等特殊字段拆分、分类变量处理、数据归一化处理等加工处理。为分析到达时间与终停时的关系,将到达时间拆分为到达年、到达月、到达日和到达小时等影响因素。
选取2019年7月至2022年9月的作业数据作为训练集,2022年10月至2022年12月的作业数据为测试集。训练集与测试集中,出发状态为重车的车辆数分别为15万辆与
1089辆 ,出发状态为空车的车辆个数分别为15万辆与203辆。3.2 数据集相关性分析
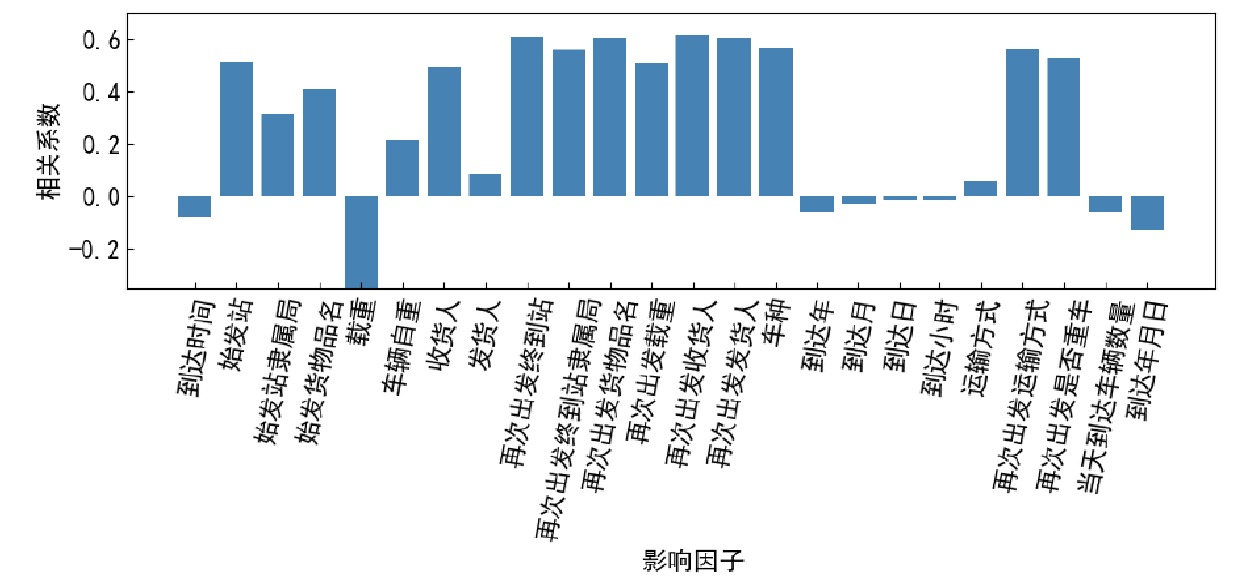
为减少模型复杂度和输入参数个数,需要分析各参数与终停时之间的关系。各影响因素与终停时的相关系数如图3所示。由图3可知,终停时与始发站、始发站隶属局、货物品名、载重、收货人、发货人、车种、运输方式、再次出发是否重车、当天到达车辆数量等相关性较高。
4 模型预测效果分析
4.1 评价指标
为验证模型的预测效果,本文选取均方误差(MSE,Mean Square Error)、平均绝对误差(MAE,Mean Absolute Error)、预测误差在5 h内的统计概率P(5)和10 h内的统计概率P(10)作为评价指标,相应计算公式为
$$ {{E_{\mathrm{MSE}} = }}\frac{{\text{1}}}{{{n}}}\sum\limits_{i = 1}^n {{{\left[ {f\left( {{x_i}} \right) - {y_i}} \right]}^2}} $$ (1) $$ {{E_{\mathrm{MAE}} = }}\frac{{\text{1}}}{{{n}}}\sum\limits_{i = 1}^n {\left( {\left| {f\left( {{x_i}} \right) - {y_i}} \right|} \right)} $$ (2) $$ {{P}}\left( {\text{5}} \right){\text{ = }}\frac{{N(|f\left( {{x_i}} \right)| \leqslant\ 5)}}{n} $$ (3) $$ {{P}}\left( {{\text{10}}} \right){\text{ = }}\frac{{N(|f\left( {{x_i}} \right)| \leqslant\ {\text{10}})}}{n} $$ (4) 式(1)~(4)中,
$ {y_i} $ 为样本实际值;$ f\left( {{x_i}} \right) $ 为样本预测值;n 为预测样本的数量; N(g)为符合条件g的预测样本的数量。4.2 模型验证
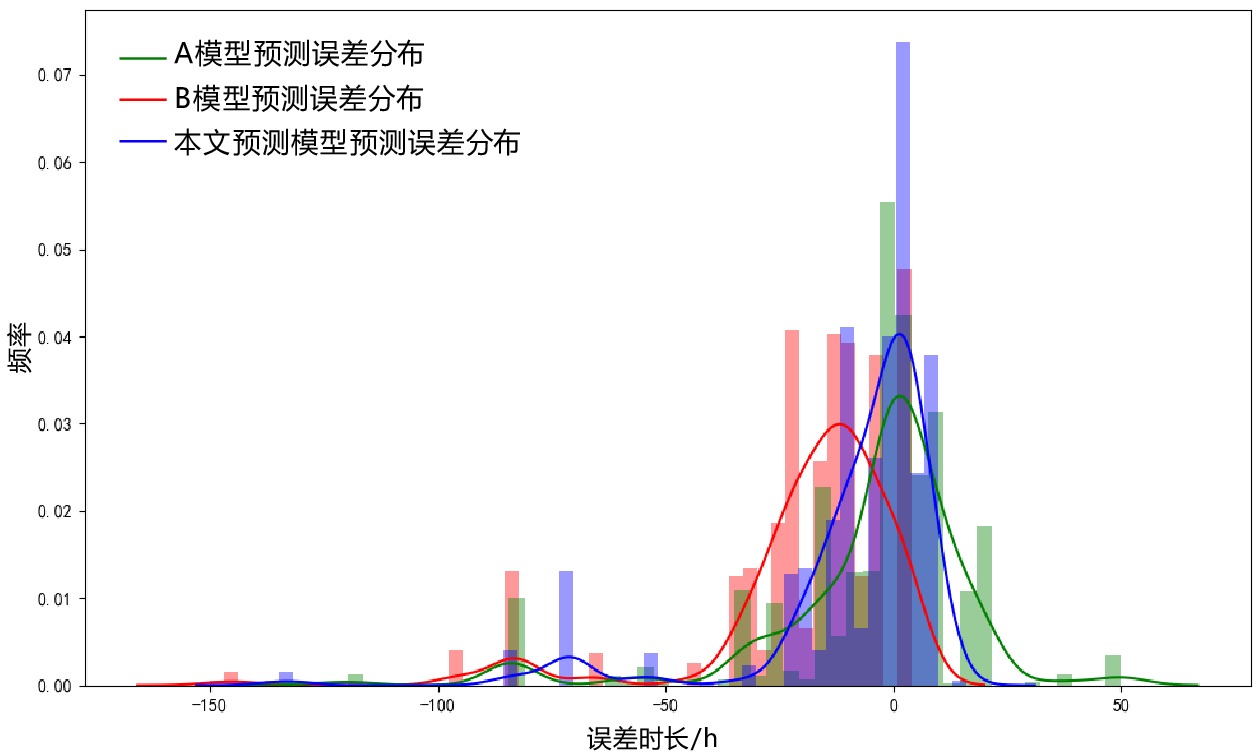
通过测试集对本文预测模型进行测试,并与仅采用随机森林算法的模型(A模型)和仅采用BP神经网络算法的模型(B模型)进行对比。 3个模型的预测值与实际值的差值计算的预测误差分布情况如图4所示。由图4可看出,本文预测模型平均误差小于A模型和B模型。
本文根据4.1中的评价指标对各模型的预测结果进行计算分析,结果如表1所示。
表 1 各模型的评价指标计算结果模型 MSE MAE P(5) P(10) A模型 573 14 0.39 0.63 B模型 837 19 0.26 0.38 本文预测模型 509 11 0.51 0.75 由表1可看出,本文预测模型的MSE和MAE均小于A模型和B模型。本文预测模型的P(5)为0.51,比A模型高0.12,比B模型高0.25。本文预测模型的P(10)为0.75,比A模型高0.12,比B模型高0.37。与A模型、B模型相比,本文预测模型的各评价指标均最优,能够为铁路货运站场提供较为精确的终停时预测结果。
5 结束语
货运站场作业是铁路货物作业的重要组成部分。终停时从车辆的角度度量了货运站场的整体作业效率。本文设计的铁路货运站场车辆终到停留时间预测模型在实例数据验证中与仅使用随机森林算法的模型和仅使用BP神经网络算法的模型进行对比,预测误差更小,验证了本文预测模型的有效性。下一步,尝试将本文预测模型应用到实际货运作业系统中,在为货主提供预测服务的同时,根据其反馈改进预测模型,并进一步分析和提炼终停时的影响因素,持续优化模型,以提升其预测效果。
-
表 1 各模型的评价指标计算结果
模型 MSE MAE P(5) P(10) A模型 573 14 0.39 0.63 B模型 837 19 0.26 0.38 本文预测模型 509 11 0.51 0.75  下载: 导出CSV
下载: 导出CSV
-
[1] Shi A Q, Dong B T, Zhao F C, et al. Prediction of dwell time of railway freight cars at the terminal based on Gradient Boosting Regression Tree[C]//Proceedings of 2019 3rd International Conference on Mechanical and Electronics Engineering, 29 November, 2019-30 November, 2019, Chongqing City, China. Clausius Scientific Press, 2019: 220-227.
[2] 韩 浪,王壮锋,张春德. 铁路调度集中系统调车作业时间智能预测方法研究[J]. 铁道标准设计,2022,66(2):143-148. DOI: 10.13238/j.issn.1004-2954.202012210002. [3] 钟立民,付骏峰,李长宇,等. 基于梯度提升决策树模型的铁路货运装卸时间预测技术[J]. 铁路计算机应用,2023,32(3):1-5. DOI: 10.3969/j.issn.1005-8451.2023.03.01 [4] 吴志伟,孔垂云,钟立民,等. 货运车站物流效率多指标优化方法研究[J]. 铁路计算机应用,2023,32(2):18-22. DOI: 10.3969/j.issn.1005-8451.2023.02.04 [5] 李良柱. 关于对进一步优化运输组织方案压缩编组站中停时指标的思考[J]. 黑龙江科技信息,2012(31):137. [6] 何宏伟. 铁路货车在站停留时间延长的原因分析[J]. 铁道运输与经济,2008,30(5):14-16. DOI: 10.3969/j.issn.1003-1421.2008.05.005 [7] 权诗琦,张晓华. 压缩邯郸站货车在站停留时间对策分析[J]. 铁道货运,2021,39(5):8-12. DOI: 10.16669/j.cnki.issn.1004-2024.2021.05.02. [8] 杨廷宇,倪少权,陈钉均,等. 列车在站技术作业时间写实管理信息系统设计[J]. 铁路计算机应用,2019,28(8):31-36. DOI: 10.3969/j.issn.1005-8451.2019.08.008 [9] 张 政,李世强. 基于AdaBoost改进随机森林和SVM的极化SAR地物分类[J]. 中国科学院大学学报,2022,39(6):776-782. [10] 杨长春,聂倩倩. 面向PM2.5预测的时间序列分解与机器学习融合模型[J]. 安全与环境学报,2023,23(12):4600-4608. DOI: 10.13637/j.issn.1009-6094.2022.1616. [11] Zhang W C. Compare Linear regression, Decision Tree Regressor, and Random Forest Regressor based on python, a restaurant company on Kaggle as a case[J]. BCP Business & Management, 2023(36): 322-329. DOI: 10.54691/bcpbm.v36i.3449
[12] 秦建楠,胡文斌,徐 立. 基于随机森林和神经网络的城市轨道交通列车速度预测算法[J]. 控制与信息技术,2022(6):62-68. DOI: 10.13889/j.issn.2096-5427.2022.06.010. [13] Guo K J, Qiao Y X, Gao Z. Based on BP neural network glass cultural relics chemical category and composition prediction model construction[J]. Highlights in Science, Engineering and Technology, 2023(42): 111-117. DOI: 10.54097/hset.v42i.7083
[14] Huang Z L, Wang J J, Gongbo Z D, et al. Prediction of global temperature based on the BP neural networks[J]. Highlights in Science, Engineering and Technology, 2023(42): 251-261. DOI: 10.54097/hset.v42i.7102
-
期刊类型引用(5)
1. 于孔燕. 大型桥梁支座板铸造工艺及低温性能研究. 现代制造技术与装备. 2024(09): 127-129 .  百度学术
百度学术
2. 刘敖然. 城市轨道交通桥梁支座更换施工技术探讨. 科技创新与生产力. 2023(04): 131-133 . 百度学术
3. 王保宪,刘聪,李义强,赵维刚. 基于多桥支座振动信号联合分析的列车荷载类型识别方法. 铁道科学与工程学报. 2023(07): 2582-2593 . 百度学术
4. 李森. 高速公路桥梁支座病害检测及维修处治分析. 工程技术研究. 2023(22): 217-219 . 百度学术
5. 朱峰,毕超. 基于传感器数据的高速公路桥梁支座位移检测方法. 装备制造技术. 2023(11): 202-204 . 百度学术
其他类型引用(4)
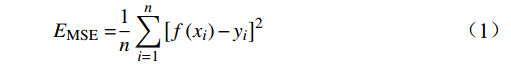
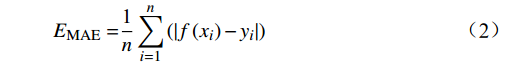
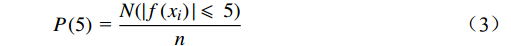
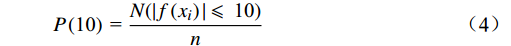
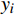
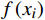
计量
- 文章访问数: 43
- HTML全文浏览量: 28
- PDF下载量: 28
- 被引次数: 9
