

Online detection method for high-speed railway perimeter intrusion based on video sequence inference
-
摘要:
针对高速铁路(简称:高铁)周界入侵事件检测任务中面临的事件时序依赖性导致的建模难度高、样本类间差异小的问题,提出一种基于视频序列推理的高铁周界入侵在线检测方法。利用门控循环单元捕捉视频序列的动态特征,区分不同事件差异;通过Transformer编码器构建视频序列的全局时序依赖关系,理解事件的全局上下文;使用Transformer解码器的预测结果作为补充信息,辅助当前事件的检测。实验结果显示,与传统检测方法相比,该方法能够更准确地进行高铁周界入侵事件检测,具有推广价值。
Abstract:This paper proposed an online detection method for high-speed railway perimeter intrusion based on video sequence inference to address the issues of high modeling difficulty and small differences between sample classes caused by event temporal dependency in the detection of high-speed railway perimeter intrusion events. The paper utilized gated loop units to capture the dynamic features of video sequences, distinguished differences between different events, constructed global temporal dependencies of video sequences through Transformer encoders, understood the global context of events, and used the prediction results of Transformer decoders as supplementary information to assist in the detection of current events. The experimental results show that compared with traditional detection methods, this method can more accurately detect high-speed rail perimeter intrusion events and has promotional value.
-
随着我国高速铁路(简称:高铁)大规模投入运营,及时发现和杜绝由人为因素、自然灾害导致的高铁周界入侵现象,对保障高铁行车环境安全具有重要意义。
高铁周界环境极为复杂,通常包括多种地形,不同地形会影响监控摄像头的架设方式和覆盖范围,沿线植被也会造成视线遮挡等问题。高铁周界入侵事件包括人员入侵和车辆入侵等类型,检测场景包括建筑物密集的城市区域、植被茂密的农村区域及隧道、桥梁等特殊结构区域,这些均对高铁周界防护提出了更高要求。
针对上述问题,众多学者进行了相关研究,傅荟瑾等人[1]基于YOLO(You Only Look Once)v5模型提出一种高铁周界入侵人员检测方法;王瑞等人[2]设计了一种MOD算法,通过当前帧与背景帧差分实现高铁周界入侵检测。然而,高铁周界入侵事件本质上是一种时间序列数据。与依赖静态图像分析的传统方法不同,其检测基于视频序列,通过分析连续的视频帧,识别出如人员穿越线路、车辆闯入轨道等的动态变化,强调目标的动态行为和运动轨迹。因此,缺乏时序依赖关系建模能力的深度学习模型在挖掘周界入侵事件语义信息方面的局限性较大。随着视频动作检测技术的发展,Geest等人[3]提出基于LSTM(Long Short Term Memory)的双流反馈网络,用于建模序列时序依赖关系,在只观察过去部分的情况下识别正在发生的动作;Wang等人[4]提出的OadTR方法,利用Transformer神经网络的自注意力机制,对序列时序依赖关系进行建模,实现对目标动作的在线检测。
此外,不同于常规的离线视频检测,在实际应用场景中,监控视频的检测通常需要在线进行。在线检测的本质在于能够在事件未完全结束前,实时分析和处理视频数据,及时发现和响应潜在的安全威胁。
综上,本文提出一种基于视频历史序列推理的高铁周界入侵在线检测方法,通过提取视频序列的动态特征,并对全局时序依赖关系进行建模,提高对高铁周界入侵事件检测的准确率。
1 模型设计
1.1 模型架构
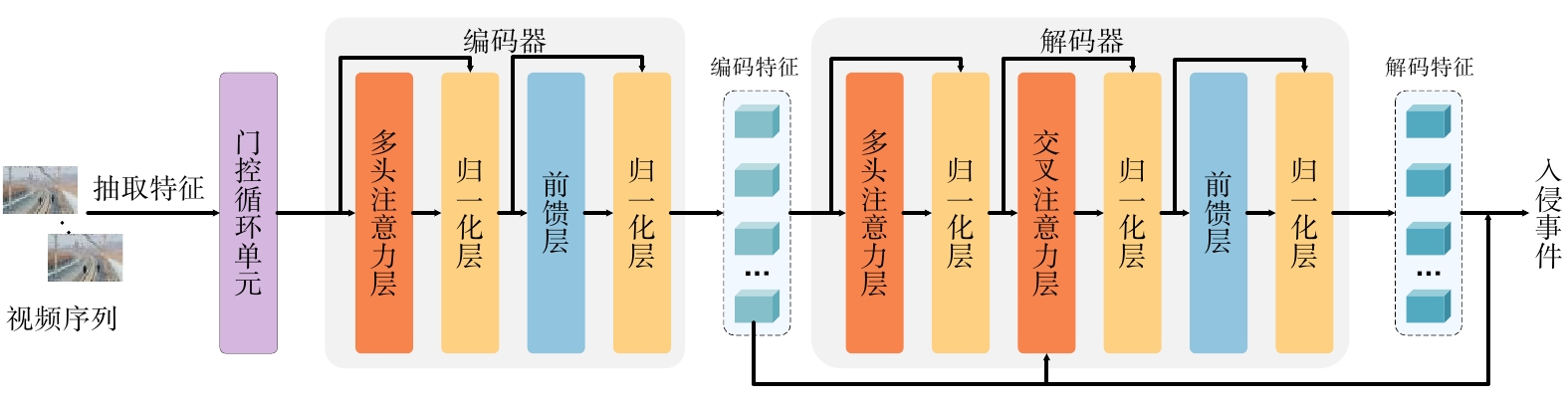
基于递归神经网络的模型和基于Transformer神经网络的模型是用于视频动作检测的两种主流模型。基于递归神经网络的模型通过学习视频序列中的时序关系,理解序列中相邻帧间的细微差别。然而,由于依赖信息在传输过程中逐渐衰减,导致其在抽象全局依赖关系方面的性能受限。相比之下,基于Transformer神经网络的模型通过自注意力机制实现视频帧间的广泛交互,从而学习视频序列中的全局依赖关系,但这种全局交互可能会使该模型在一定程度上忽视序列的局部动态特征。因此,本文提出了一种结合自注意力机制[5]和门控循环单元[6]的高铁周界入侵在线检测模型(简称:本文模型),其框架如图1所示。
本文模型先利用门控循环单元提取视频序列的动态特征,区分不同事件间的差别;再利用Transformer编码器对视频序列中的全局时序依赖关系进行建模,挖掘周界入侵事件的语义信息;最终基于Transformer解码器的预测结果辅助当前的周界入侵事件检测。
1.2 门控循环单元
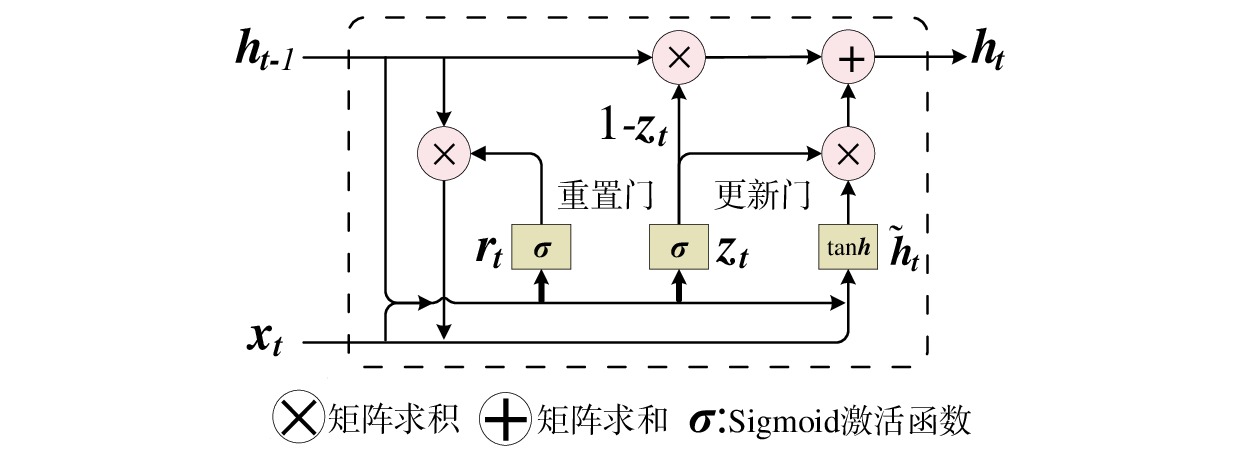
传统的递归神经网络通过连接隐藏层之间的结点使网络具有记忆功能,但会遇到梯度消失或梯度爆炸等问题[7]。门控循环单元通过引入门控机制调节信息流动,以克服递归神经网络的缺陷[6]
门控循环单元结构如图2所示,其通过重置门和更新门来调节信息流动。重置门的状态与前一时间步隐藏状态信息相关,该门激活时,门控循环单元融合大部分前一时间步的隐藏状态信息;反之,前一时间步的隐藏状态信息被忽略。更新门决定前一时间步隐藏状态信息和当前时间步候选隐藏状态信息的综合记忆与遗忘程度,该门激活时,门控循环单元倾向于保留前一时间步隐藏状态信息,反之,更多保留候选隐藏状态信息。
本文模型利用门控循环单元提取监控视频特征,以减少原始数据中的噪声和冗余信息,再向门控循环单元输入当前时间步
$ \boldsymbol{t} $ 的特征${{{{\boldsymbol{x}}_{\boldsymbol{t}}}}}$ 矩阵和前一时间步的隐藏状态${{\boldsymbol{h}}_{{{{\boldsymbol{t}}}} - 1}}$ 矩阵,最后计算得到$ {{{\boldsymbol{t}}}} $ 时刻重置门和更新门的激活值${{\boldsymbol{r}}_{\boldsymbol{t}}}$ 和${{\boldsymbol{z}}_{\boldsymbol{t}}}$ ,公式为$$ {{\boldsymbol{r}}}_{t}=\sigma ({{\boldsymbol{W}}}_{r}·[{{\boldsymbol{h}}}_{t-1},{{\boldsymbol{x}}}_{t}]+{{\boldsymbol{b}}}_{r}) $$ (1) $$ {{{\boldsymbol{z}}}}_{{\boldsymbol{t}}}=\sigma ({{\boldsymbol{W}}}_{z}·[{{\boldsymbol{h}}}_{t-1},{{\boldsymbol{x}}}_{t}]+{{\boldsymbol{b}}}_{z}) $$ (2) 式(1)和式(2)中,
${{\boldsymbol{W}}_r}$ 和$ {{\boldsymbol{b}}_r} $ 分别为重置门的权重矩阵和偏置矩阵;${{\boldsymbol{W}}_z}$ 和${{\boldsymbol{b}}_z}$ 分别为更新门的权重矩阵和偏置矩阵。通过
${{\boldsymbol{r}}_{\boldsymbol{t}}}$ 计算当前时间步候选隐藏状态$ {\tilde {\boldsymbol{h}}_{\boldsymbol{t}}} $ ,本文模型能够综合前一时间步的隐藏状态与当前输入特征,遗忘与当前特征无关的历史信息,其公式为$$ {\tilde{{\boldsymbol{h}}}}_{{\boldsymbol{t}}}=\mathrm{tanh}({{{\boldsymbol{W}}}}·[{{\boldsymbol{r}}}_{{\boldsymbol{t}}}\otimes {{\boldsymbol{h}}}_{{\boldsymbol{t}}-1},{{\boldsymbol{x}}}_{{\boldsymbol{t}}}]+{\boldsymbol{b}}) $$ (3) 式(3)中,
$W$ 和$ b $ 分别为候选隐藏状态的权重和偏置。通过
${{\boldsymbol{z}}_{\boldsymbol{t}}}$ 计算当前时间步隐藏状态${{\boldsymbol{h}}_{\boldsymbol{t}}}$ ,本文模型自适应决定当前时间步隐藏状态中应包含多少前一时间步的隐藏状态信息和候选隐藏状态信息,公式为$$ {{\boldsymbol{h}}_{\boldsymbol{t}}} = (1 - {{\boldsymbol{z}}_{\boldsymbol{t}}}) \otimes {{\boldsymbol{h}}_{{\boldsymbol{t}} - 1}} + {{\boldsymbol{z}}_{\boldsymbol{t}}} \otimes {\tilde {\boldsymbol{h}}_{\boldsymbol{t}}} $$ (4) 1.3 编码器和解码器
1.3.1 多头注意力机制
Transformer神经网络的Transformer编码器通过多头注意力机制使输入序列中的每一帧都能够与其他帧进行交互,从而建立序列全局时序依赖关系,使得本文模型能够关注到视频序列中各个时刻的重要信息。Transformer神经网络的Transformer解码器则基于多头和交叉注意力机制的预测结果辅助当前入侵事件的检测。多头注意力机制中,单个注意力头通过缩放点积注意力实现。
先对输入的视频序列进行线性变换,得到查询向量、键向量和值向量,计算查询向量与键向量的点积;通过softmax函数对点积结果进行归一化,得到注意力权重;基于注意力权重对值向量进行加权求和,得到单个注意力头的输出向量;将所有注意力头的输出向量拼接在一起,并通过线性变换进行投影,得到多头注意力层的输出向量,公式为
$$ MHA({\boldsymbol{Q}},{\boldsymbol{K}},{\boldsymbol{V}}) = Concat({H_1},{H_2},\cdots,{H_h}){\boldsymbol{W}} $$ (5) 式(5)中,
$ {\boldsymbol{Q}} = {\boldsymbol{X}}{{\boldsymbol{W}}^q} $ ;$ {\boldsymbol{K}} = {\boldsymbol{X}}{{\boldsymbol{W}}^k} $ ;$ {\boldsymbol{V}} = {\boldsymbol{X}}{{\boldsymbol{W}}^v} $ ;${\boldsymbol{X}}$ 表示输入向量的矩阵;$ {{\boldsymbol{W}}^q} $ 、$ {{\boldsymbol{W}}^k} $ 、${{\boldsymbol{W}}^v}$ 是可学习的投影矩阵;$Concat$ 表示将不同注意力头的输出结果进行拼接;$ h $ 为注意力头的数目;$W$ 为输出投影的参数。单个注意力头的公式可表示为
$$ {H_i} = softmax(\frac{{{{\boldsymbol{Q}}_i}{K_i}^T}}{{\sqrt {{d_k}} }}){V_i} $$ (6) 式(6)中,
$ {{\boldsymbol{Q}}_i} = {\boldsymbol{Q}}{\boldsymbol{W}}_i^q $ 、${{\boldsymbol{K}}_i} = {\boldsymbol{K}}{\boldsymbol{W}}_i^k$ 和${{\boldsymbol{V}}_i} = {\boldsymbol{V}}{\boldsymbol{W}}_i^v$ 分别为查询矩阵、键矩阵和值矩阵,$ {\boldsymbol{W}}_{\boldsymbol{i}}^{\boldsymbol{q}} $ 、${\boldsymbol{W}}_{\boldsymbol{i}}^{\boldsymbol{k}}$ 、${\boldsymbol{W}}_{\boldsymbol{i}}^{\boldsymbol{v}}$ 分别对应第$i$ 个头的线性变换权重矩阵;$\sqrt {{d_k}} $ 为缩放因子。1.3.2 编码器
本文将一个任务标记嵌入到来自门控循环单元的带有动态特征的序列
$ {{\boldsymbol{F}}_{\boldsymbol{g}}} $ 中,得到编码器的输入序列$ {{\boldsymbol{X}}_{{\boldsymbol{enc}}}} $ 。该任务标记可通过与Transformer网络的编码器的其他输入特征进行注意力交互来获得,用于学习与在线周界入侵事件检测任务相关的全局判别特征。编码器先通过基于自注意力的多头注意力层$ MH{A_{SA}} $ ,得到输出向量$ {\boldsymbol{F}} $ 。随后通过残差连接和归一化层得到$ {\boldsymbol{F}}' $ ,再将$ {\boldsymbol{F}}' $ 输入到一个带有GELU激活函数的两层前馈网络FFN中得到编码器输出Fenc,公式为$$ {\boldsymbol{F}} = MH{A_{SA}}({{\boldsymbol{X}}_{enc}}{{\boldsymbol{W}}^q},{{\boldsymbol{X}}_{enc}}{{\boldsymbol{W}}^k},{{\boldsymbol{X}}_{enc}}{{\boldsymbol{W}}^v}) $$ (7) $$ {{\boldsymbol{F}}_{{\boldsymbol{enc}}}} = Norm(FFN(F') + F') $$ (8) 式(8)中,Norm为归一化函数。
1.3.3 解码器
本文模型中,Transformer解码器接收来自编码器的带有全局时序依赖信息的向量
$ {{\boldsymbol{F}}_{{\boldsymbol{enc}}}} $ ,与可学习的预测查询向量进行交叉注意力操作,利用对过去关键信息的观察进行事件的动态预测。解码器包括两个多头注意力层和一个前馈层,$ MH{A_{SA}} $ 基于多头注意力层,$ MH{A_{CA}} $ 基于多头交叉注意力层,通过两个注意力层得到$ {{\boldsymbol{F}}_{{\boldsymbol{DSA}}}} $ 和$ {{\boldsymbol{F}}_{{\boldsymbol{DCA}}}} $ ,之后利用残差连接和归一化层得到$ {{\boldsymbol{F}}_{{\boldsymbol{DSA}}}}^\prime $ 和$ {{\boldsymbol{F}}_{{\boldsymbol{DCA}}}}^\prime $ ,最后通过前馈网络FFN得到解码器输出$ {{\boldsymbol{F}}_{{\boldsymbol{dec}}}} $ ,将其作为补充信息辅助当前事件的检测。计算过程为$$ {{\boldsymbol{F}}}_{{\boldsymbol{DSA}}}=MH{A}_{SA}({\boldsymbol{Q}}{{\boldsymbol{W}}}^{q},{\boldsymbol{Q}}{{\boldsymbol{W}}}^{k},{\boldsymbol{Q}}{{\boldsymbol{W}}}^{v}) $$ (9) $$ {{\boldsymbol{F}}_{{\boldsymbol{DCA}}}} = MH{A_{CA}}({{\boldsymbol{F}}_{{\boldsymbol{DSA}}}}^\prime {{\boldsymbol{W}}^q},{{\boldsymbol{F}}_{{\boldsymbol{enc}}}}{{\boldsymbol{W}}^k},{{\boldsymbol{F}}_{{\boldsymbol{enc}}}}{{\boldsymbol{W}}^v}) $$ (10) $$ {{\boldsymbol{F}}_{{\boldsymbol{dec}}}} = Norm(FFN({{\boldsymbol{F}}_{{\boldsymbol{DCA}}}}^\prime ) + {{\boldsymbol{F}}_{{\boldsymbol{DCA}}}}^\prime ) $$ (11) 2 实验与结果验证
2.1 数据集
本文选择在线动作检测任务数据集Thumos’14和TVSeries作为公共数据集,用于实验、评估本文方法的有效性。Thumos’14数据集包含20个动作类别的200个训练视频和213个带有时间标注的测试视频;TVSeries数据集包含6部电视剧,每部约150 min,
6231 个动作实例。高铁行车环境监控视频的特点是具有大量的背景片段,且入侵事件主体占据画面像素区域小,本文收集标注了用于高铁周界入侵事件检测的数据集CRH-Intrusion。数据集包含路基地段、低矮桥梁、匝道等3种典型场景,白天、黑夜等2种环境。对筛选得到的454个视频进行人工标注,划分出沿线路行走、护栏内侧活动、横向穿越线路、车辆横向穿越线路等4类入侵事件。随机选择318段视频为训练集,136段视频为测试集。图3为数据集部分样例。
2.2 模型参数设置
通过在Kinetics数据集[8]上预训练的TSN双流网络[9](其中,时空子网络分别采用ResNet-50和BN-Inception)提取监控视频特征。本文模型使用Adam优化器进行训练,初始学习率设置为
0.0001 ,每次训练的样本批量大小为32,权重衰减设置为0.0005 。2.3 实验结果分析
2.3.1 检测准确率对比分析
本文选择通用的基于递归神经网络的TRN(Temporal Recurrent Network)[10]、IDN(Information Discrimination Network)[11]和基于Transformer的OadTR与本文模型在Thumos’14、TVSeries及CRH-Intrusion数据集上进行对比实验;采用校准平均精度均值mcAP(%)作为检测准确率的评价指标,实验结果如表1所示。
表 1 不同模型在3个数据集上的mcAP值Thumos’14数据集 TVSeries数据集 CRH-Intrusion数据集 TRN 91.52% 85.27% 94.22% IDN 93.46% 86.11% 94.47% OadTR 97.33% 87.25% 95.21% 本文模型 98.15% 88.36% 96.61% 由表1可知,相比TRN、IDN和OadTR,本文模型在3个数据集上的检测精度均得到提升。在CRH-Intrusion数据集上检测准确率的提升,说明本文模型能够有效提取高铁周界入侵视频序列的动态特征,建立序列的全局时序依赖关系。
2.3.2 不同类别周界入侵事件检测结果分析
本文模型对CRH-Intrusion数据集中不同类别周界入侵事件的检测结果如表2所示。
表 2 本文模型在CRH-Intrusion数据集上检测不同入侵事件的mcAP值入侵事件类别 mcAP值 行人沿线路行走 97.52% 行人横向穿越线路 99.01% 行人在护栏内侧活动 95.76% 车辆横向穿越线路 94.87% 所有类别入侵事件 96.61% 由表2可知,本文模型在多个类别入侵事件的检测任务中均有较高的准确率。特别地,在“行人横向穿越线路”类别中检测效果最优,这表明了该模型对人体动作和行为模式的高度敏感性。相比之下,“车辆横向穿越线路”的检测准确率是4个类别中最低的,可能因该类数据较少所致。
2.3.3 连续时段检测分析
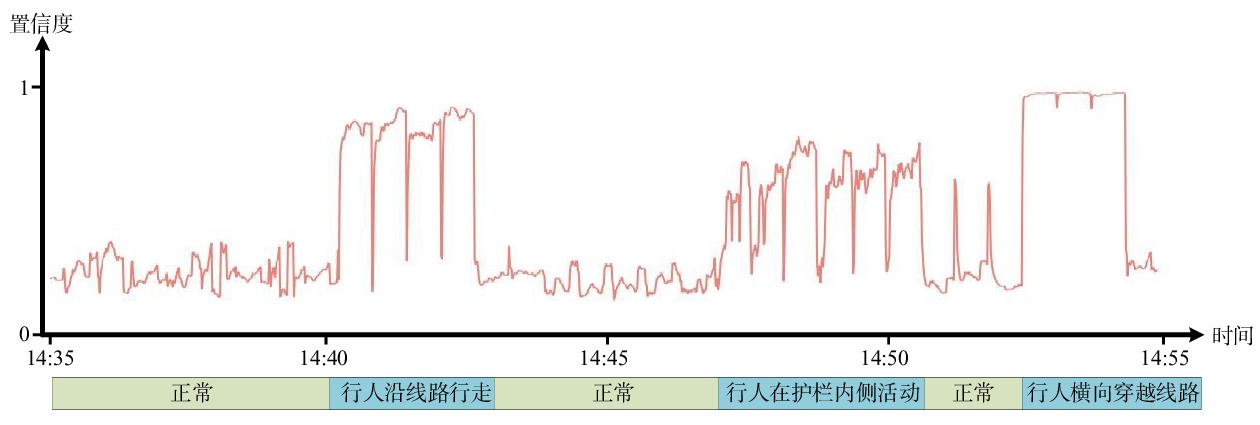
为验证本文方法在实地场景中的有效性,选取20 min的高铁周界监控视频进行在线周界入侵事件检测,可视化结果如图4所示。纵轴表示检测置信度,横轴表示连续时段,高置信度的3个时段与场景中发生入侵事件的时段完全对应,表明本文方法能够实时检测到入侵事件。同时,能够在早期检测到每一次入侵事件发生。
3 结束语
根据高铁行车环境监控视频的特性和周界入侵检测要求,本文设计了一种基于视频序列进行推理的周界入侵事件在线检测方法。通过提取视频序列的动态特征和全局时序依赖关系进行建模,对入侵事件作实时检测。然而,实地检测时的背景噪声和动态环境下的不确定因素等都会增加事件检测难度,因此,提高本文方法在多变环境下的检测能力和鲁棒性将是下一步的研究方向。
-
表 1 不同模型在3个数据集上的mcAP值
Thumos’14数据集 TVSeries数据集 CRH-Intrusion数据集 TRN 91.52% 85.27% 94.22% IDN 93.46% 86.11% 94.47% OadTR 97.33% 87.25% 95.21% 本文模型 98.15% 88.36% 96.61%  下载: 导出CSV
下载: 导出CSV
表 2 本文模型在CRH-Intrusion数据集上检测不同入侵事件的mcAP值
入侵事件类别 mcAP值 行人沿线路行走 97.52% 行人横向穿越线路 99.01% 行人在护栏内侧活动 95.76% 车辆横向穿越线路 94.87% 所有类别入侵事件 96.61%
下载: 导出CSV
-
[1] 傅荟瑾,史天运,王 瑞,等. 基于改进YOLOv5的高铁周界入侵人员检测方法研究[J]. 铁道标准设计,2023,67(9):162-169. [2] 王 瑞,史天运,包 云. 一种基于视频的铁路周界入侵检测智能综合识别技术研究[J]. 仪器仪表学报,2020,41(9):188-195. [3] De Geest R, Tuytelaars T. Modeling temporal structure with LSTM for online action detection[C]//2018 IEEE Winter Conference on Applications of Computer Vision (WACV), 12-15 March, 2018, Lake Tahoe, NV, USA. New York, USA: IEEE, 2018. 1549-1557.
[4] Wang X, Zhang S W, Qing Z W, et al. OadTR: online action detection with transformers[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision, 10-17 October, 2021, Montreal, QC, Canada. New York, USA: IEEE, 2021. 7545-7555.
[5] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems, 4 December, 2017, Long Beach, CA, USA. Red Hook: Curran Associates Inc. , 2017. 6000-6010.
[6] Cho K, Van Merriënboer B, Gulcehre C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, 25-29 October, 2014, Doha, Qatar. ACL, 2014. 1724-1734.
[7] 胡小宁. 基于GRU循环神经网络的云数据中心应用故障预测方法[J]. 铁路计算机应用,2022,31(2):7-11. DOI: 10.3969/j.issn.1005-8451.2022.02.02 [8] Carreira J, Zisserman A. Quo Vadis, action recognition? A new model and the kinetics dataset[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 21-26 July, 2017, Honolulu, HI, USA. New York, USA: IEEE, 2017. 4724-4733.
[9] Wang L M, Xiong Y J, Wang Z, et al. Temporal segment networks: towards good practices for deep action recognition[C]//14th European Conference on Computer Vision, 11-14 October, 2016, Amsterdam, The Netherlands. Cham, Switzerland: Springer, 2016. 20-36.
[10] Xu M Z, Gao M F, Chen Y T, et al. Temporal recurrent networks for online action detection[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, 27 October-2 November, 2019, Seoul, Korea (South). New York, USA: IEEE, 2019. 5531-5540.
[11] Eun H, Moon J, Park J, et al. Learning to discriminate information for online action detection[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 13-19 June, 2020, Seattle, WA, USA. New York, USA: IEEE, 2020. 806-815.
-
期刊类型引用(1)
1. 殷希彦,秦希青,盛步云,周欢,陈鹏,姜峰. 基于本体与Petri网的智能工厂关键要素语义建模. 组合机床与自动化加工技术. 2023(01): 173-178 .  百度学术
百度学术
其他类型引用(0)
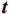
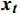
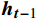
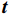
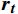
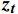
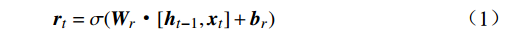
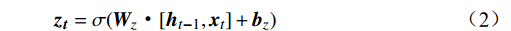

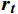
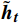
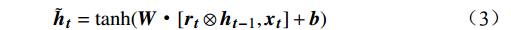
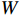

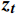
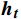
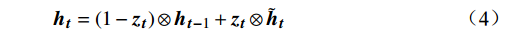
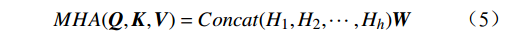
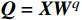
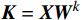
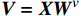
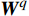
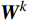
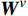
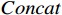
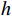
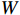
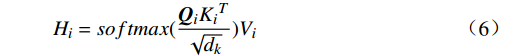


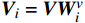
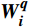
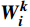
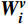

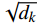
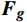
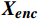
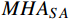


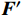
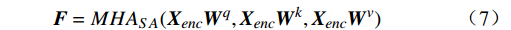
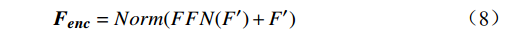


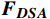
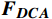
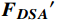

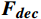
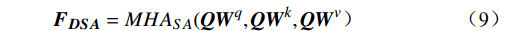



计量
- 文章访问数: 101
- HTML全文浏览量: 29
- PDF下载量: 44
- 被引次数: 1
