

Risk user identification based on horizontal federated learning
-
摘要:
第三方平台推出的各种铁路旅客抢票服务,给中国铁路12306互联网售票系统(简称:12306)带来了较大压力,为保障12306的稳定性和旅客购票的公平性,亟需对风险用户进行识别。为应对因12306部署在不同的物理位置、不同中心的数据聚合存在一定风险的情况,研究在用户数据分散的条件下,基于横向联邦学习的风险用户识别方法。文章基于用户的访问行为,构建和提取用户特征,构建基于XGboost、逻辑回归和神经网络等算法的横向联邦学习模型,并进行模型验证。实验结果表明,基于XGboost算法的横向联邦学习模型具有较好的风险用户识别效果,为铁路数据的安全使用提供了技术支撑。
-
关键词:
- 12306互联网售票系统 /
- 横向联邦学习 /
- XGBoost /
- 风险用户 /
- 神经网络
Abstract:Various railway passenger ticket grabbing services launched by the third-party platform have brought great pressure to the China railway 12306 Internet ticketing and reservation system (12306 for short). In order to ensure the stability of 12306 and the fairness of passenger ticket purchase, it is urgent to identify risk users. This paper aimed to address the risk of data aggregation caused by the deployment of 12306 in different physical locations and centers, studied a risk user identification method based on horizontal federated learning under the condition of dispersed user data. Based on user access behavior, the paper constructed and extracted user features, constructed a horizontal federated learning model using algorithms such as XGboost, logistic regression, and neural networks, and validated the model. The experimental results show that the horizontal federated learning model based on XGboost algorithm has good risk user recognition performance, provides technical support for the safe use of railway data.
-
节假日期间,我国铁路旅客出行意愿强烈、需求旺盛。2023年9月22日,售票量突破历史记录,高达
2695 万张,中国铁路12306互联网售票系统(简称:12306)承受的压力也随之增大。与此同时,第三方代购票平台为获取非正常收益,推出抢票功能、推销加速包、鼓励买短乘长等行为,并且利用技术手段频繁调用12306的系统接口,严重影响了12306的安全稳定运行,扰乱了公平公正的售票秩序,侵犯了旅客的合法权益,且存在个人隐私信息泄露风险。为更好地保障旅客权益和12306的稳定性,中国国家铁路集团有限公司(简称:国铁集团)建立了12306风险防控子系统,实现了多维度数据分析、多样化控制手段,同时,通过指数权重算法[1]、多渠道异常检测[2]等技术,持续提升12306的风险识别能力。目前,国内外针对风险用户识别的研究主要集中在电商平台和社交平台,如Wang J等人[3]针对社交平台陌陌的风险用户进行研究,对比了C4.5决策树、随机森林、支持向量机、贝叶斯和XGBoost等多种分类算法;Yan Zhang等人[4]、Xiao Sun等人[5]使用深度学习算法提取特征,进行谣言和发帖情绪的识别。上述算法在使用时需要将数据聚合起来,但随着《数据安全法》《个人信息保护法》等法律的实施,确保用户数据安全和保护隐私是企业必须面对的问题,会影响不同系统间的联合分析和数据应用等。
在此背景下,联邦学习应运而生,各数据持有方不需要对外提供自身数据,以一种加密的参数交换方式共建模型,从而保障用户的隐私和数据安全[6],该技术由Mc Mahan等人[7-8]提出,用来解决移动设备上语言预测模型的更新问题。联邦学习主要分为横向联邦学习、纵向联邦学习和迁移联邦学习[9],在交通流量预测[10-12]、物联网设备联合计算[13]、网络入侵检测[14-15]、异常检测[16-18]等场景都有较多的应用。文献[11]基于纵向联邦学习进行航班延误预测;文献[14—15]应用横向联邦学习提升了网络入侵检测的准确率。
12306分别部署在一中心和二中心,采用双中心的方式提供售票服务,不同区域的用户会访问不同中心。为提升12306的风险用户识别能力,同时满足保护隐私的要求,本文将联邦学习的概念融入到风险用户识别模型中,利用双中心的数据挖掘用户特征,从而提升风险用户识别效果,同时,避免数据融合和数据传输带来的风险,保障数据的安全性。
1 联邦学习概述
按照数据分布划分,联邦学习可分为横向联邦学习、纵向联邦学习和联邦迁移学习。
(1)横向联邦学习是指各数据持有方在本地训练模型,并且只与服务器共享模型参数来更新全局模型,避免集中服务器访问数据持有方的本地数据,对支持分布式训练的场景具有较大优势。适用于不同数据持有方用户特征重合较多,而用户重合较少的情形,利用横向联邦学习可增加参与训练的用户量。
(2)纵向联邦学习是汇总不同数据持有方的数据特征,并采用一种保护数据安全的设计对训练过程中的损失进行运算,使得模型可分析的维度增强,进而提升模型效果。适用于不同数据持有方用户重合部分较大[10],但用户特征重合部分相对较小的情形。
(3)联邦迁移学习是指当不同数据持有方的数据集中,用户重合部分较少[10],同时用户特征重叠部分也较少,并且部分数据缺失标签值时,这种情况称为联邦迁移学习,如参与训练的数据持有方位于不同区域时,用户交集可能比较小,且若二者开展的业务不完全相同时,数据特征也不完全相同。因此,联邦迁移学习主要用来解决数据量小且数据特征少的场景下的训练难题,同时,保障不同数据持有方数据的安全性和隐私性。
2 用户的特征构建
2.1 用户的基础特征构建
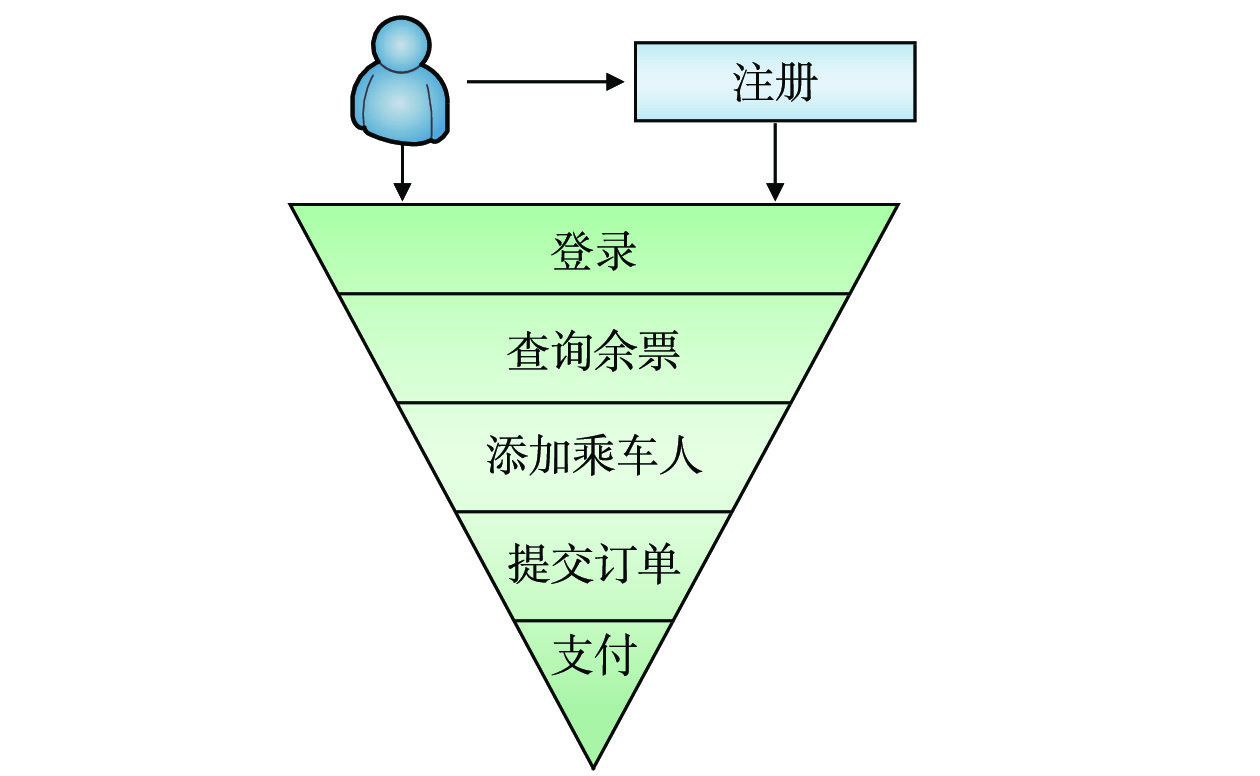
用户在12306的购票流程如图1所示,每个环节覆盖的用户数逐渐减少,但各环节都存在着一定的风险行为。例如,利用机器人进行批量注册,使用其他网站的用户名密码登录进行撞库,通过爬虫或高频调用等方式查询余票,利用程序自动化提交订单、支付订单等操作行为。因此,需要从多个环节挖掘用户特征,才能识别风险用户并对其进行有效拦截,更好地保护12306购票用户的权益。
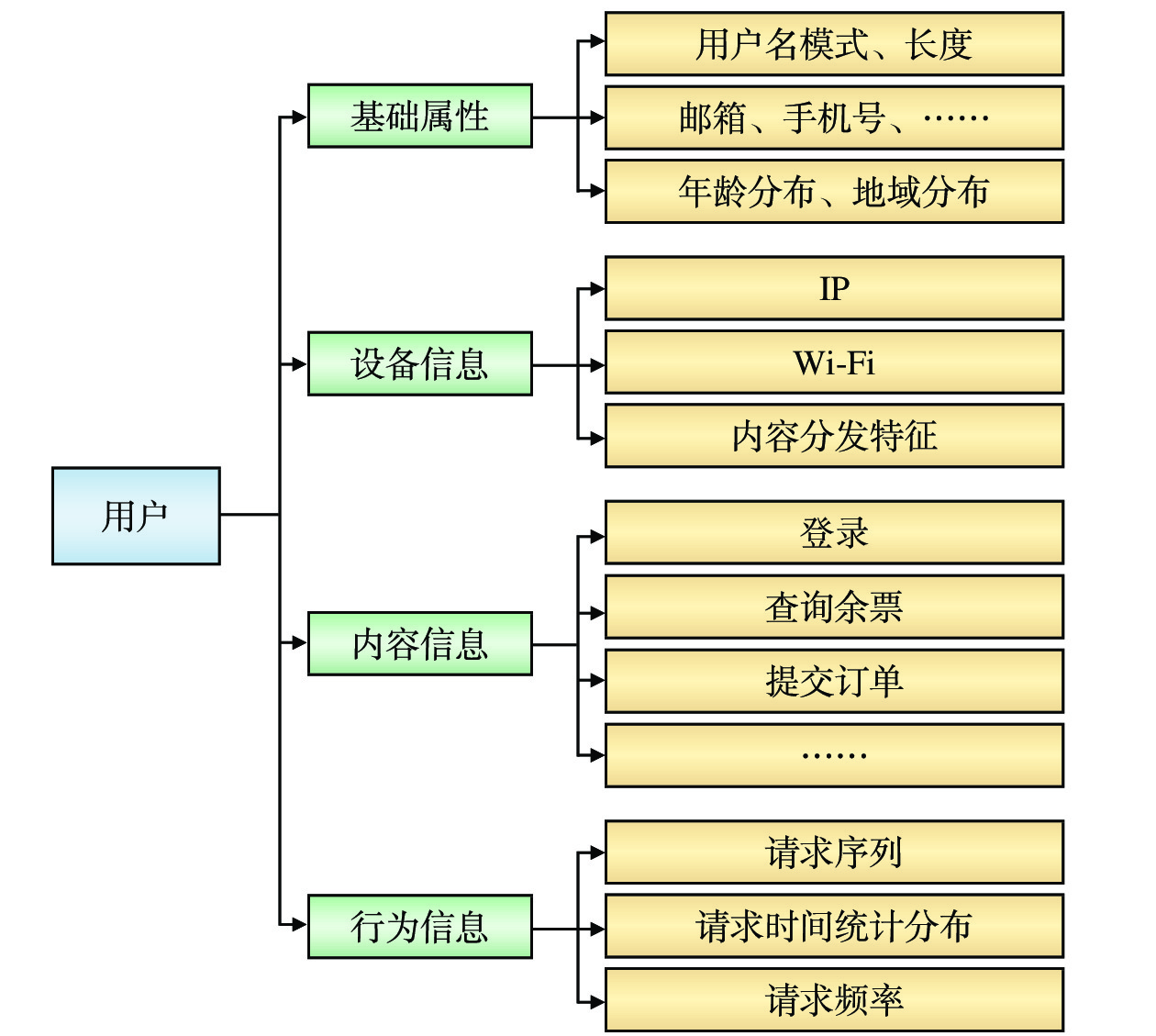
为了更好地识别风险用户,借鉴文献[19]中描述的特征等维度,构建用户特征挖掘架构,如图2所示。
2.1.1 基础属性
基础属性包含用户名、邮箱、手机号码、年龄和地域等。用户名由大写字母、小写字母、数字、特殊字符组成,不同字符的组合会形成特定的组合模式,而机器人批量注册会存在一定的规律性,所以该特征具有较强的区分意义,另外批量注册的用户名年龄分布、地域分布也可能存在着聚集现象。
2.1.2 设备信息
用户访问12306,需要使用IP、Wi-Fi等设备信息,且12306使用了内容分发网络(CDN ,Content Delivery Network),不同地区的用户会访问到对应的设备信息,所以用户使用的设备信息具有一定的代表性。
2.1.3 内容信息
登录、查询余票、提交订单等各种业务请求对应的是用户访问内容。用户访问接口与时间维度、设备信息等进行不同的组合,可形成不同粒度范围的风险用户识别特征,如1 min内登录使用的IP地址个数。
2.1.4 行为信息
用户的操作行为是用户购票流程的体现,应从整体和局部提炼操作行为的特征。整体操作行为特征包括访问总请求的序列长度、去重请求的个数等;局部操作行为特征提取主要针对用户购票的关键环节,如登录、查询联系人、提交订单等请求的顺序和访问时间间隔等。
用户的行为涉及范围较广,构建的基础特征越多,对风险用户的识别越精准,因此,在识别风险用户时,需要从以上不同维度丰富特征,从而提升风险用户识别的效果。
2.2 用户的特征提取
本文基于相关系数和随机森林方法对用户进行特征提取,主要步骤如下。
(1)去掉空值样本,如用户IP和请求较少的用户。
(2)对提取的特征进行填充。统计特征填0,文本特征填空字符串;对于请求序列,设定固定的长度值,将用户形成的请求序列进行对齐操作,对长度大于阈值的请求序列进行尾部截取,长度小于阈值的请求序列进行空操作填充。
(3)利用公式
r=∑(x−ˉx)(y−ˉy)√∑(x−ˉx)2∑(y−ˉy)2 ,计算用户不同特征与用户风险标签之间的相关系数,进而发现强相关特征,其中,x和y分别为特征变量和风险标签的取值;ˉx 和ˉy 分别表示变量x和y的均值。(4)确定特征与标签相关系数的阈值,将筛选出的强相关性特征输入到随机森林模型中,通过随机森林算法输出各个特征的重要性。
(5)分别提取一中心和二中心用户重要性较高的特征,取二者之并集,形成风险用户识别的特征集合,输入风险用户识别模型。
3 风险用户识别模型构建
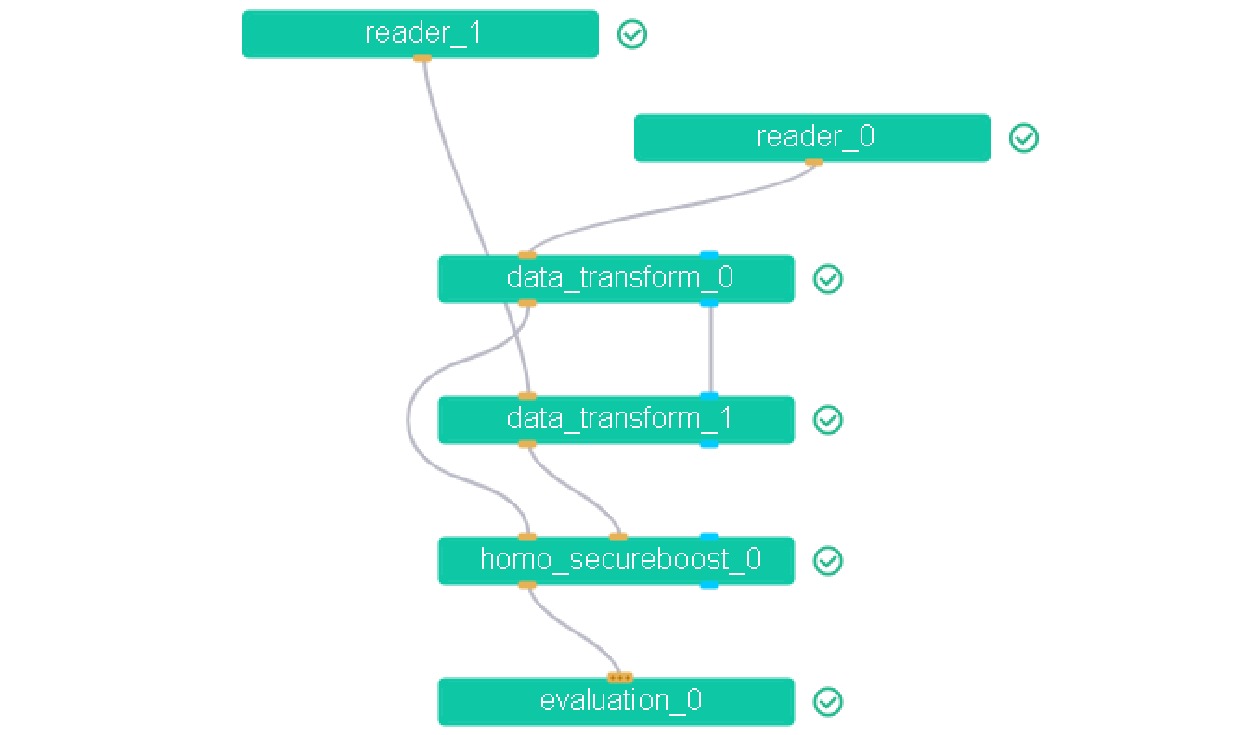
基于横向联邦学习技术,利用一中心和二中心用户数据共同训练风险用户识别模型,模型结构一致。一中心和二中心作为数据持有方,分别拥有带标签的样本,且二者的用户数据具有相同的特征空间。训练时,一中心和二中心分别将对应的数据集上传到对应的客户端,客户端将训练好的模型参数上传到聚合服务器,聚合服务器完成梯度信息的聚合,选择最优分割点,再发送给一中心和二中心对应的客户端,进一步优化模型,直到满足训练停止条件。根据风险用户识别的需求,利用第2章中的特征构建方法形成风险用户识别的特征集合,为保证特征含义一致,需要统一特征的统计口径,在FATE(Federated AI Technology Enabler)平台进行模型训练。数据集文件采用CSV(Comma-Separated Values)格式,应包含用户名、特征集合和标签。
FATE平台的Reader组件用于读取训练集和测试集;DataTransform组件将上传的用户数据转换成FATE平台支持的实例;Evaluation组件主要用于测试集和验证集评价。本文采用支持XGBoost算法(Fed_XGb)的HomoSecureBoost组件,构建基于Fed_XGb的横向联邦学习模型(简称:Fed_XGb模型);采用支持逻辑回归算法(Fed_lr)的HomoLR组件,构建基于Fed_lr的横向联邦学习模型(简称: Fed_lr模型);采用支持神经网络算法(Fed_nn)的HomoNN组件,构建基于Fed_nn的横向联邦学习模型(简称:Fed_nn模型)。上述3种模型,即为本文所建的风险用户识别模型。
3.1 Fed_XGb模型
一中心和二中心的客户端和聚合服务器端初始化本地设置。一中心和二中心的客户端应用特征挖掘组件从所有的特征中寻找最优的分割点;一中心和二中心的客户端分别建立对应的决策树,将计算的局部梯度信息加一个随机数发给聚合服务器端,双方的随机数在聚合服务器计算时刚好可以抵消;聚合服务器端找到最优的分隔节点并同步给一中心和二中心的客户端;一中心和二中心的客户端获得最优的分割点后,开始进行下一层节点的选择,当达到树的最大深度或满足停止条件时,结束当前树的构造,重新选样,开启下一棵树的构造;当树的最大个数满足停止条件时,构造过程结束。
3.2 逻辑回归Fed_lr模型
一中心和二中心的客户端使用相同的风险用户识别模型结构,每次训练时使用本地数据进行训练,训练完成后将加密的参数信息传输到聚合服务器;根据设定的参数聚合方案(求和、取均值等)进行客户端参数的计算;将参数信息同步到一中心和二中心客户端的本地模型,不断迭代直到满足误差要求,将最终模型同步作为一中心和二中心的本地模型。该模型计算的是各个特征的权重。
3.3 Fed_nn模型
该模型与其他横向联邦学习模型的构建过程基本一致,需要一中心和二中心的客户端构建相同的网络结构,通过仲裁服务器进行神经网络结构的参数更新。
模型训练完成后,提取对应的模型标识(id)和模型版本(version),将其部署至FATE平台,即可进行用户的风险预测,一中心和二中心的用户可分别上传到对应的客户端,提交检测任务。
4 实验
本文基于Dockers环境,将风险用户识别模型部署在FATE平台上。基于Spark软件,统计用户的初步特征;基于Python,进行数据集的预处理。分别实现Fed_XGb模型、Fed_lr模型和Fed_nn模型。
4.1 数据选取和标记
分析用户的提交订单环节,用户行为选择用户过去1 h的活动轨迹。从一中心和二中心分别选取1万个用户,通过调整访问方式确定用户标签。基于12306用户特征构建的方法,结合基础属性、设备信息及行为信息,形成89个基础特征,部分特征集合如图3所示。
对构建的用户基础特征进行预处理后,去掉相关性绝对值小于0.02的特征和随机森林计算的特征重要性小于0.001的特征,取一中心和二中心的特征并集,最终选取63个特征参与模型训练。将一中心和二中心用户的数据集按照训练集∶验证集∶测试集=6∶2∶2的比例进行分配,每份数据集的正常用户与异常用户的比例均为4∶1。
4.2 实验设置
4.2.1 Fed_XGb模型实现
目标函数为cross_entropy;任务类型为二分类;基准方法为XGBoost;树的个数为5,最大深度设为9;最小分割样本设为2; 节点纯度最小阈值为0.001;特征重要性为'split';验证频次为1;停止标准为0.001。由Reader、Data_Transform、HomoSecureBoost、Evaluation组件组成,组件对应的工作流图如图4所示。
4.2.2 Fed_lr模型实现
该模型由Reader、DataTransform、FeatureScale、HomoLR、Evaluation等5个组件组成。组件工作流与Fed_XGb模型类似。部分参数的权重如表1所示。
表 1 Fed_lr模型部分参数的权重参数 权重 Intercept(常变量) -1.978 len_full - 1.03212 min_dur - 0.94088 len_uniq - 0.89904 getwaittime_num_5min - 0.37734 confirmpassengerinfosingle_num_15min - 0.29207 url3 - 0.28003 querypassenger_num_5min - 0.24953 4.2.3 Fed_nn模型实现
该模型由Reader、DataTransform、HomoNN、Evaluation等4个组件组成,其中,HomoNN组件包含Linear层和Sigmoid层。优化器选择Adam;学习率设置为0.01;Linear层输入特征维度为63,输出维度为1;损失函数选择交叉熵损失函数BCELoss。训练部分参数设置为:训练器为fedavg_trainer;训练次数为20;批量数据集大小为32;验证频率为1。
4.2.4 基于单个中心数据集训练的XGBoost模型
该模型只使用XGBoost算法,未使用联邦学习框架,训练时使用单个中心的用户数据集,参数使用贝叶斯算法进行调优。该模型用于与Fed_XGb模型作对比。
4.3 实验结果及分析
风险用户识别模型的评价指标主要有准确率(Accuracy)、召回率(Recall)和精准率(Precesion)等。风险用户检测属于非均衡数据集,ROC(Receiver Operating Characteristic)曲线下的面积(AUC,Area Under Curve)和F1值更能体现模型的整体效果,其中,F1 是召回率和精准率的调和均值。 针对上述4种模型,分别计算测试集的AUC、F1值、Accuracy、Recall和Precesion。
利用上述4种模型,分别对一中心和二中心的数据集进行预测。为验证模型的风险用户识别效果,分别针对一中心和二中心的数据集训练了对应的XGBoost模型,所有模型针对同一批测试集,输出的评价指标如表2和表3所示。
表 2 一中心数据集的指标结果模型 AUC F1-score Accuracy Recall Precesion Fed_XGb 0.9856 0.9061 0.9591 0.9490 0.8670 Fed_lr 0.9545 0.7948 0.9036 0.8981 0.7129 Fed_nn 0.9550 0.8130 0.9102 0.9393 0.7167 XGBoost 0.9868 0.8828 0.9510 0.9389 0.8330 表 3 二中心数据集的指标结果模型 AUC F1-score Accuracy Recall Precesion Fed_XGb 0.9837 0.8715 0.9444 0.9491 0.8056 Fed_lr 0.9609 0.8168 0.9186 0.9135 0.7387 Fed_nn 0.9680 0.8598 0.9394 0.9364 0.7948 XGBoost 0.9825 0.8543 0.9335 0.9443 0.7800 从实验结果可知,通过FATE平台训练,相对于基于单中心用户数据集训练的XGBoost模型,Fed_XGb模型利用多个中心的用户数据,在多个指标上,风险用户识别效果都有所提升,尤其是Precesion和F1值提升较大,证明了基于横向联邦学习的模型在12306风险用户识别中的可行性。同时,Fed_XGb模型的风险识别效果优于Fed_lr模型和Fed_nn模型。
5 结束语
12306是铁路旅客购票出行的重要服务系统。本文基于横向联邦学习算法,利用FATE平台设计了针对12306的风险用户识别模型,该模型可有效识别非官方渠道购票的用户,进而保障官方购票的旅客权益。后续将进一步从安全性、时效性、多场景出发,进行联邦学习的应用研究,为铁路数据的安全使用提供更好的技术支撑。
-
表 1 Fed_lr模型部分参数的权重
参数 权重 Intercept(常变量) -1.978 len_full - 1.03212 min_dur - 0.94088 len_uniq - 0.89904 getwaittime_num_5min - 0.37734 confirmpassengerinfosingle_num_15min - 0.29207 url3 - 0.28003 querypassenger_num_5min - 0.24953  下载: 导出CSV
下载: 导出CSV
表 2 一中心数据集的指标结果
模型 AUC F1-score Accuracy Recall Precesion Fed_XGb 0.9856 0.9061 0.9591 0.9490 0.8670 Fed_lr 0.9545 0.7948 0.9036 0.8981 0.7129 Fed_nn 0.9550 0.8130 0.9102 0.9393 0.7167 XGBoost 0.9868 0.8828 0.9510 0.9389 0.8330
下载: 导出CSV
表 3 二中心数据集的指标结果
模型 AUC F1-score Accuracy Recall Precesion Fed_XGb 0.9837 0.8715 0.9444 0.9491 0.8056 Fed_lr 0.9609 0.8168 0.9186 0.9135 0.7387 Fed_nn 0.9680 0.8598 0.9394 0.9364 0.7948 XGBoost 0.9825 0.8543 0.9335 0.9443 0.7800
下载: 导出CSV
-
[1] 李 雯,朱建生,单杏花. 基于指数权重算法的铁路互联网售票异常用户智能识别的研究与实现[J]. 铁路计算机应用,2018,27(10):7-10, DOI: 10.3969/j.issn.1005-8451.2018.10.002. [2] Fan C M, Li W, Zhu Y T, et al. Anomaly access detection method based on multi-channel data[C]//Proceedings of the IEEE 5th International Conference on Cloud Computing and Big Data Analytics, 10-13 April, 2020, Chengdu, China. New York, USA: IEEE, 2020. 295-300.
[3] Wang J Q, He X L, Gong Q Y, et al. Deep learning-based malicious account detection in the Momo social network[C]//Proceedings of the 27th International Conference on Computer Communication and Networks (ICCCN), 30 July - 2 August, 2018, Hangzhou, China. New York, USA: IEEE, 2018. 1-2.
[4] Zhang Y, Chen W L, Yeo C K, et al. Detecting rumors on online social networks using multi-layer autoencoder[C]//Proceedings of 2017 IEEE Technology & Engineering Management Conference (TEMSCON), 8-10 June, 2017, Santa Clara, CA, USA. New York, USA: IEEE, 2017. 437-441.
[5] Sun X, Zhang C, Ding S, et al. Detecting anomalous emotion through big data from social networks based on a deep learning method[J]. Multimedia Tools and Applications, 2020, 79(13-14): 9687. DOI: 10.1007/s11042-018-5665-6
[6] 卫新乐,张志勇,宋 斌,等. 基于纵向联邦学习的社交网络跨平台恶意用户检测方法[J]. 小型微型计算机系统,2022,43(7):1541-1546, DOI: 10.20009/j.cnki.21-1106/TP.2020-1108. [7] Mcmahan H B, Moore E, Ramage D, et al. Federated learning of deep networks using model averaging[DB/OL]. https://arxiv.org/abs/1602.05629, 2017.
[8] Konen J, Mcmahan H B, Ramage D, et al. Federated optimization:distributed machine learning for on-device intelligence[DB/OL]. [2024-05-31]. https://arxiv.org/abs/1610.02527, 2016.
[9] Yang Q, Liu Y, Chen T J, et al. Federated machine learning: Concept and applications[J]. ACM Transactions on Intelligent Systems and Technology, 2019, 10(2): 12.
[10] 陈 涛,郭 睿,刘志强. 面向大数据隐私保护的联邦学习算法航空应用模型研究[J]. 信息安全与通信保密,2020(9):75-84. DOI: 10.3969/j.issn.1009-8054.2020.09.010 [11] 李 国,张秋杰. 基于纵向联邦学习的航班延误预测[J]. 计算机工程与设计,2023,44(5):1594-1601. [12] Liu Y, Yu J J Q, Kang J W, et al. Privacy-preserving traffic flow prediction: A federated learning approach[J]. IEEE Internet of Things Journal, 2020, 7(8): 7751-7763. DOI: 10.1109/JIOT.2020.2991401
[13] William Marfo, William Marfo, Shirley V. Moore. Network Anomaly Detection Using Federated Learning[DB/OL]. [2024-05-31]. https://arxiv.org/abs/2303.07452, 2023.
[14] 赵 英,王丽宝,陈骏君,等. 基于联邦学习的网络异常检测[J]. 北京化工大学学报(自然科学版),2021,48(2):92-99. [15] 刘金硕,詹岱依,邓 娟,等. 基于深度神经网络和联邦学习的网络入侵检测[J]. 计算机工程,2023,49(1):15-21,30. [16] 王 楠,张大林,刘娟. 一种基于联邦学习的风险权重融合的异常检测方法:中国,202111362361.7[P]. 2022-04-15. [17] 曾闽川,方 勇,许益家. 基于联邦迁移学习的应用系统日志异常检测研究[J]. 四川大学学报(自然科学版),2023,60(3):79-86. [18] 张泽辉,李庆丹,富 瑶,等. 面向非独立同分布数据的自适应联邦深度学习算法[J]. 自动化学报,2023,49(12):2493-2506, DOI: 10.16383/j.aas.c201018. [19] 曲 强,于洪涛,黄瑞阳. 社交网络异常用户检测技术研究进展[J]. 网络与信息安全学报,2018,4(3):13-23.
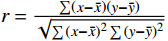

计量
- 文章访问数: 57
- HTML全文浏览量: 35
- PDF下载量: 26
