

Railway passenger travel demand mining method based on candidate ticket purchase
-
摘要:
针对铁路旅客出行需求受票额能力限制而难以准确估计的问题,引入候补购票数据,研究铁路旅客出行需求挖掘的方法。梳理了候补购票和出行需求的关系,依据业务规则和旅客选择对候补购票行为进行分类,挖掘旅客的预售出行需求;结合实名制数据和闸机刷卡数据标定旅客实际行程,从而挖掘旅客最终出行需求的上下限。选取北京—南京的城市OD(Origin - Destination)进行验证分析,结果表明,与既有的候补需求统计规则相比,最终出行需求能够与闸机推算的实际行程需求保持相似规律,更具合理性,为客运需求预测和铁路日常营销分析等工作提供了科学的基础数据支撑。
Abstract:In response to the problem of inaccurate estimation of railway passenger travel demand due to limited by ticket capacity, this paper introduced candidate ticket purchase data to study the railway passenger travel demand mining method. The paper sorted out the relationship between candidate ticket purchasing and travel demand, classified candidate ticket purchasing behavior based on business rules and passenger choices, mined passengers' pre-sale travel needs, and calibrated passengers' actual itineraries based on real name registration data and gate card swiping data, thereby mined the upper and lower limits of passengers' final travel demand. The paper selected the urban OD (Origin - Destination) of Beijing - Nanjing for verification analysis. The results show that compared with the existing candidate demand statistical rules, the final travel demand can maintain a similar pattern to the actual travel demand calculated by the gate, which is more reasonable and provides scientific basic data support for passenger demand forecasting and railway daily marketing analysis.
-
为应对日益增长的旅客出行需求,同时兼顾市场化经济的持续发展,铁路运输企业需要深入研究客运市场需求,支撑铁路客运产品的合理设计及客运营销策略的有效制定[1]。客运需求是指从预售期开始至开车时刻,旅客愿意且能够承担相应费用的一定数量的客运产品[2]。真实可靠的铁路客运需求通常难以获取,客流调查是一种较为理想的方式,但需要耗费大量的人力物力,且难以满足时效性;中国铁路客票发售和预订系统(简称:客票系统)的销售订单数据能够在一定程度上体现客运需求,同时具备良好的准确性和时效性,但其反映的是一种“受限需求”[2],受票额能力的限制,旅客在访问客票系统购票时,其第一需求可能因客运产品售罄而无法满足。此时不可售产品的需求会存在两种转移情况:(1)转移至其他车次、席位对应的客运产品,称为“需求转移”;(2)流失至其他交通运输市场(航空、公路等),称为“需求溢出”[3]。
如何利用统计模型对旅客的初始需求进行还原(也称需求非限化估计),是收益管理需求预测的核心问题之一[4],是现代收益管理系统中的关键环节,在铁路、航空、酒店和汽车租赁等领域均有所应用。合理的需求非限化估计能够提升需求预测的精准性,从而使得收益管理中的优化决策更为科学有效,提升企业的期望收入。文献[5]研究了航空客运需求的单舱位、多舱位和多航班场景,提出了航空客运收益管理需求无约束估计方法;文献[6]引入了旅客选择模型估计用户对于可替代性产品的需求;文献[7]提出在需求预测前对铁路客流数据非限化处理以提升预测的准确性;文献[8]提出混合整数非线性规划方法,来估算潜在的铁路客运需求。但上述研究方法均只考虑了产品销售量作为单一数据源。
铁路部门自2018年12月27日正式推出候补购票功能[9],旅客能够在意向车次无余票时,候补下单多个备选车次,进行“排队”购票。因此,候补购票是部分旅客“受限需求”的表征,为铁路客运需求估计提供了良好的数据条件[10],现有对候补购票的研究相对较少,随着大数据技术和业务的不断发展[11-12],数据成为企业的重要资产,深化对数据资源的挖掘是铁路部门实现数据驱动业务创新的必然趋势。
综上所述,本文分析旅客候补购票业务特点,运用大数据技术和数理统计方法,挖掘旅客真实出行需求,为需求预测和营销分析等客运业务提供更精准的数据支撑。
1 铁路旅客出行需求与候补购票
1.1 铁路旅客出行需求定义
本文提出的铁路旅客出行需求可分为预售出行需求和最终出行需求。
(1)预售出行需求指预售期内的出行需求,车票预售期指客票系统在列车开行日期前,提先发售车票的时间段。该需求反映的是预售期内旅客需求随时间的动态变化情况,一般基于实时的售票数据和候补数据进行估计;
(2)最终出行需求指预售期结束、列车开行时的最终旅客需求,此时候补订单的兑现环节已完成,旅客依据最终的购票情况完成出行。最终出行需求包括实际完成购票出行的旅客的需求,以及未能成功购票的旅客的需求,有必要还原后者的“受限”出行需求。
此外,铁路旅客出行需求可从出发城市和到达城市,即城市OD(Origin - Destination)、车站、列车、席位等多种维度统计测算,旅客在候补购票时,需要选择城市OD,以及具体的列车和席别,一次候补下单可包含多趟列车,但只有唯一的城市OD,在城市OD维度,可认为出行需求是唯一的,不受具体选择的车次、席位影响。本文后续研究的旅客出行需求仅针对城市OD维度,不涉及列车、席位等其他维度。
1.2 候补购票与出行需求的关系
客票系统推出的候补购票功能,有效避免了旅客需求向铁路外市场的流失。以往,当旅客的意向车次无余票时,旅客需要重复访问售票系统,自行监控余票情况,购票体验较差,使得部分旅客放弃铁路购票出行;若旅客进行候补需求下单,客票系统能够在相应列车产品新增余票时,自动地帮助旅客完成购票,及时有效地匹配了动态变化的铁路旅客出行需求与票额能力。
候补购票为旅客带来便利服务的同时也丰富了客运营销分析工作,对于需求非限化估计方法,旅客因票额能力限制而未被客票系统记录的需求恰好能够在一定程度上反映在候补订单中。候补订单中的信息颗粒度等同于直接购票的订单信息,包括乘车日期、出发和到达车站、车次及席位等。因此,候补订单是铁路旅客出行需求未满足状态下真实、直观的数据表征。
1.3 铁路旅客候补购票行为分类
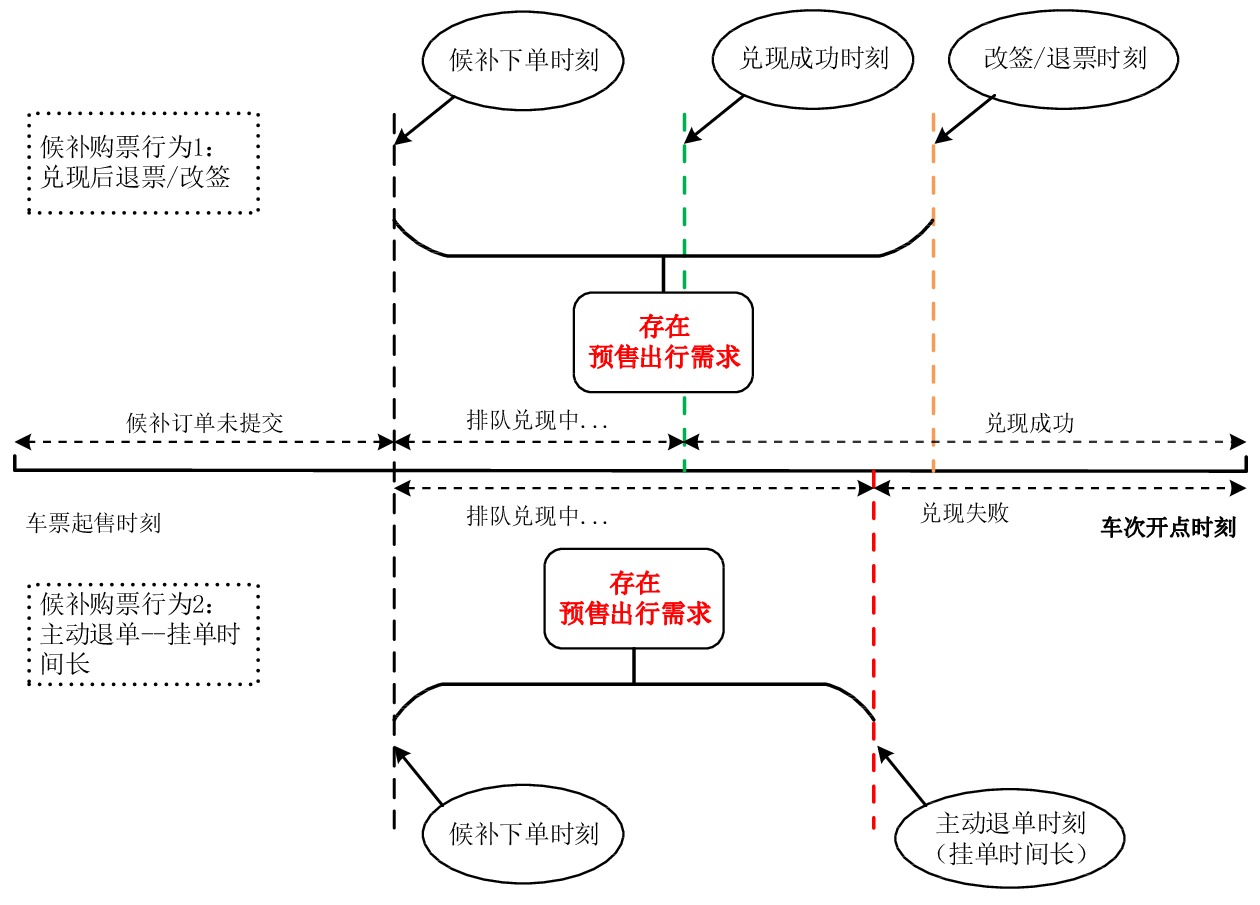
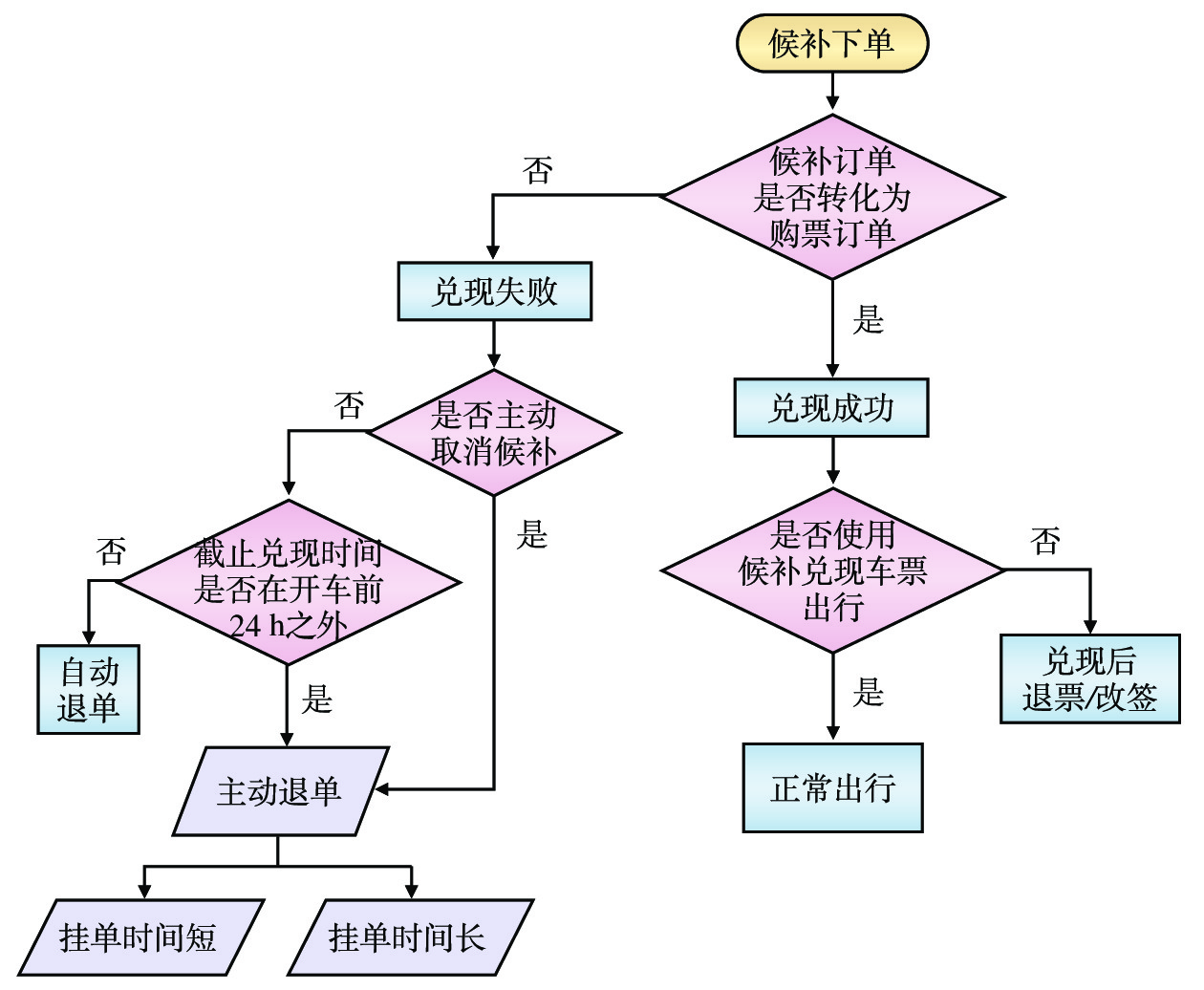
旅客候补购票中的城市OD、乘车日期、车次、席位、候补时间、兑现时间等信息组合成候补需求列表。由于旅客的出行需求是动态变化的,在旅客候补下单到实际完成出行过程中,依据客票系统对候补的实时兑现情况和旅客自身选择行为,归纳了旅客的候补购票行为,如图1所示。本文研究中,旅客提交候补订单但未支付成功时,假设其没有对应的城市OD出行需求。
(1)兑现成功且正常出行:此类旅客出行意愿强烈,候补出行需求从候补下单时刻产生,直到完成出行一直存在。
(2)兑现成功后退票或改签:退票和改签是旅客需求动态变化的直观表征,尽管旅客候补下单并兑现成功,也会因为各种原因改变行程,这类情况下,只能认为从候补提交时刻到退票/改签时刻之间存在出行需求,至于旅客退改时刻之后的出行需求,则由退票/改签后的新车票体现。
(3)自动退单:旅客依据自身情况合理设置“截止兑现时间”,若“截止兑现时间”在开车时刻前24 h及以内,认为属于自动退单行为,旅客出行需求强烈,可替代的出行方案少。
(4)主动退单:挂单时间指候补下单时刻到旅客取消候补订单时刻之间的时长,若时长较长,则认为旅客对候补订单存在一定预期,愿意去等待兑现结果,出行方案的优先级较高。可依据不同城市OD的具体情况,设置挂单时间阈值,若大于阈值,则候补出行需求从候补下单到退单时刻均存在,一般节假日期间可设置为6 h。若挂单时间小于阈值,则体现了旅客出行需求的不确定性,旅客对候补订单中客运产品的依赖性相对较弱,出行方案是可替代的,这部分候补出行需求可忽略,或依据挂单时间折减。挂单时间的长短也和旅客自身出行习惯、其他可替代客运产品的可预订状态等多种因素相关。此外,若旅客设置的“截止兑现时间”在开车时刻前24 h之外,则归类为主动退单行为。
2 基于候补购票的出行需求挖掘
2.1 预售出行需求的挖掘
在预售期内,旅客可进行候补购票下单,候补订单会经历3种状态:
(1)尚未提交候补购票订单;
(2)提交候补购票订单后兑现排队中;
(3)兑现成功或兑现失败(旅客主动取消或者程序自动取消)。
预售出行需求描述了预售期内不同时间动态的旅客出行需求,由购票需求和候补需求组成,购票需求是直观的售出车票数,而候补需求则是本节的重点研究对象。
候补购票订单的不同状态和不同的旅客选择行为形成了差异化的出行需求。以兑现后退票/改签和主动退单(挂单时间长)的两种候补购票行为举例,如图2所示。对于兑现成功的候补购票订单,从下单时刻开始均存在候补需求,但由于发生了改签或退票,因此,候补需求只存在于候补购票下单时刻至退票/改签时刻之间。
候补购票订单
i 在预售期内观察时刻t 的候补需求估计值Dt,i 为Dt,i={n,c=0且tbuy<t<ttrainn,c=1且tbuy<t<trefundn,c=2且tbuy<t<tfailn,c=3且tbuy<t<tfail且tfail−tbuy>Limit0,c=4且tbuy<t<tfail且tfail−tbuy<Limit0,其他 (1) 式(1)中,
n 为订单号对应的出行人数量;t为观察时刻;tbuy 为候补购票下单时刻;ttrain 是列车开行时刻;trefund 是候补兑现后的改签/退票时刻;tfail 是候补订单退单时刻;Limit 是挂单时间阈值;c∈[0,1,2,3,4] ,分别对应兑现成功且正常出行、兑现成功后退票或者改签、自动退单、主动退单(挂单时间长)、主动退单(挂单时间短)这5类状态。在预售期内的任意观察时刻,对相同城市OD的所有候补订单挖掘候补需求,累计求和并叠加购票需求,即得到城市OD维度的预售出行需求。
˙Dt,OD=ODi∈OD∑iDt,i+St,OD (2) 式(2)中,
OD 代表统计目标城市OD,ODi 代表候补订单i 的下单所选城市OD,St,OD 代表城市OD的购票需求。2.2 最终出行需求挖掘
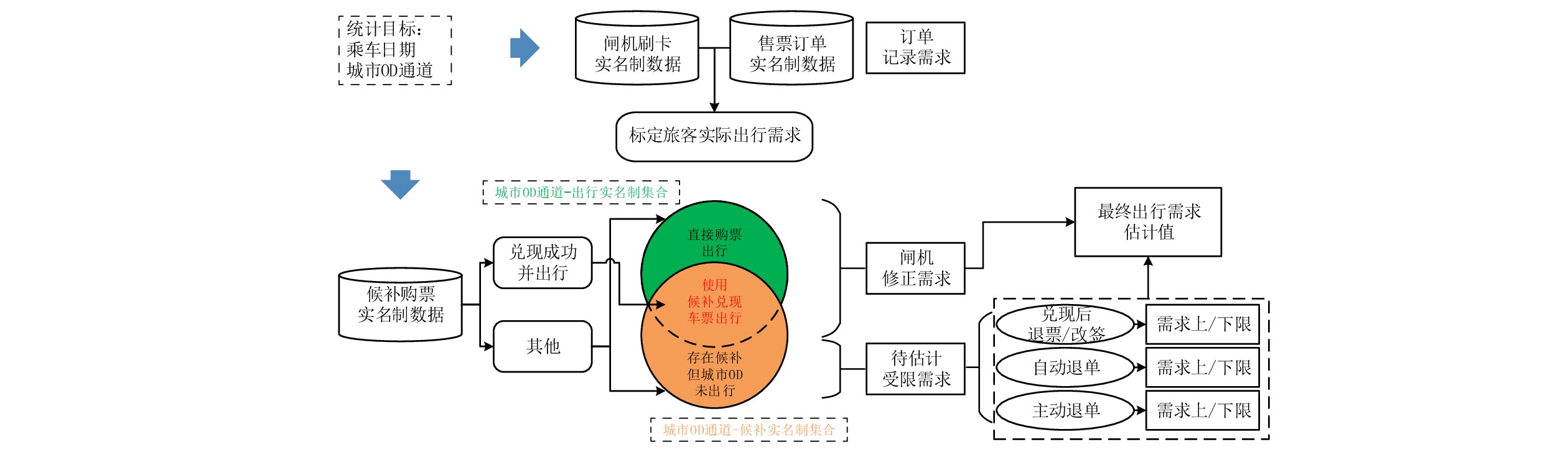
客票系统订单数据并不能完全代表最终的旅客的行程,部分旅客存在“买短乘长”“买长乘短”等异常行程,随着电子客票在全国铁路的应用,闸机刷卡数据能够提供更加准确的旅客出行需求。因此,可通过对客票系统订单数据和闸机刷卡数据的关联和处理,跟踪客票订单的闸机刷卡记录,标定旅客的实际出行需求。如式(3)所示,对旅客
j 票面记录的出发站和到达站[sfrom,sto]j ,通过闸机数据AFCj 修正为实际行程出发站和实际行程到达站[s′from,s′to]j ,并以此作为最终出行需求的计算基础。[s′from,s′to]j=g([sfrom,sto]j,AFCj) (3) 式(3)中,
g(∗) 是基于业务规则的判定函数。每一位旅客在目标乘车日期的需求是存在上限的,即每一位可能出行的旅客,最多存在一人次的出行需求。基于此前提,引入旅客实名制数据[13],以出行人为研究目标,结合其候补购票行为,能够合理地估计城市OD中最终出行需求的上下限值。
如图3所示,最终出行需求可分为出行实名制集合及候补实名制集合,其中候补实名制集合中,存在一部分兑现成功或直接购票出行的旅客,这部分需求是可观测记录的,因此属于订单记录需求,通过式(3)可进一步处理得到闸机修正需求;而候补实名制集合中,存在过候补行为但最终未出行的旅客,依据3种不同的候补行为可估计需求的上下限。
Hj,U 和Hj,L 分别代表旅客j 由候补购票产生的待估计受限需求上限和下限。(1)兑现后退改
旅客的最终出行需求上限是1,下限是0,因为旅客在目标乘车日期改变了行程,其待估计受限需求为
{Hj,U=1Hj,L=0,cj=1 (4) 式(4)中,
cj=1 表示旅客j 的候补订单属于兑现后退票/改签的状态。(2)自动退单
旅客若截止兑现时间设置在距离发车24 h及以内且候补订单状态属于自动退单,认为旅客出行需求强烈且受其他因素影响较少,则待估计受限需求上限和下限均是1。
{Hj,U=1Hj,L=1,cj=2且ttrain−trefund<24 (5) 式(5)中,
ttrain 是列车开点时刻;cj=2 表示旅客j 的候补订单属于自动退单的状态。(3)主动退单
旅客若在设置的挂单时间阈值外退单,认为旅客的出行需求存在一定的概率,则待估计受限需求上限是1,下限是
α ,0<α<1 ,需要按比例折减;{Hj,U=1Hj,L=α,cj=3 (6) 式(6)中,
cj=3 表示主动退单(挂单时间长)。若旅客在设置的时间阈值内退单,则上限是
β ,0<β<1 ,同样按比例折减,下限是0。{Hj,U=βHj,L=0,cj=4 (7) 式(7)中,
cj=4 表示主动退单(挂单时间短)基于给定城市OD,最终出行需求上下限的计算公式为
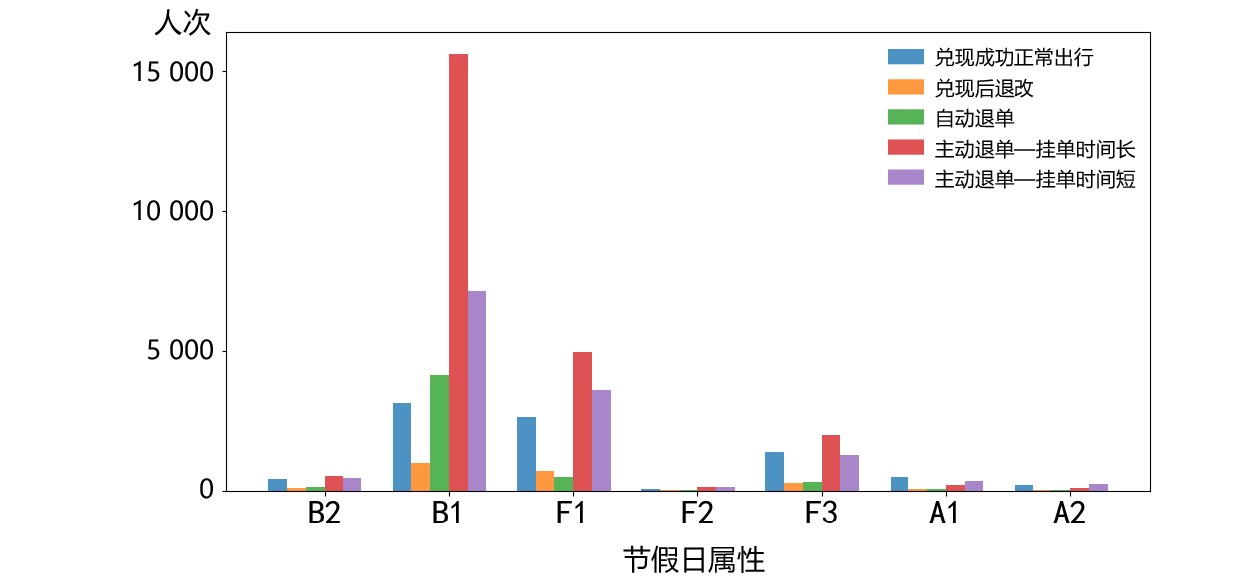
{Dj,U=ODj∈OD∑jHj,U+D0Dj,L=ODj∈OD∑jHj,L+D0 (8) 式(8)中,
ODj 为旅客j 候补订单对应的城市OD,D0 为城市OD闸机修正需求。3 验证分析
3.1 城市OD通道候补情况
本文选取北京—南京的城市OD通道开展验证分析,北京和南京的客流等级较高、成分复杂,存在大量的商务流、旅游流和务工流,旅客出行需求的波动性较大。北京—南京约
1011 km,属于中长距离运输,综合交通市场以铁路和航空为主,铁路线路包括京沪(北京—上海)线和京沪高速线,旅客列车包括大站停和站站停的高速列车、普速列车和夜间动卧等,可满足不同旅客群体出行需求。然而,京沪高速线的票额能力主要集中在北京—上海区段,南京南站作为京沪高速线的中间站,北京—南京区段在节假日等高峰期票额能力受限严重,旅客候补需求旺盛。因此,验证分析的时间选取2024年清明假期,法定节假日共3天,并额外选取假期前、后各2天的乘车日期,即从2024年4月2日—2024年4月8日,共计7天。统计客票系统的销售订单,北京—南京的客流最高峰出现在2024年4月3日,即放假前1天,达到
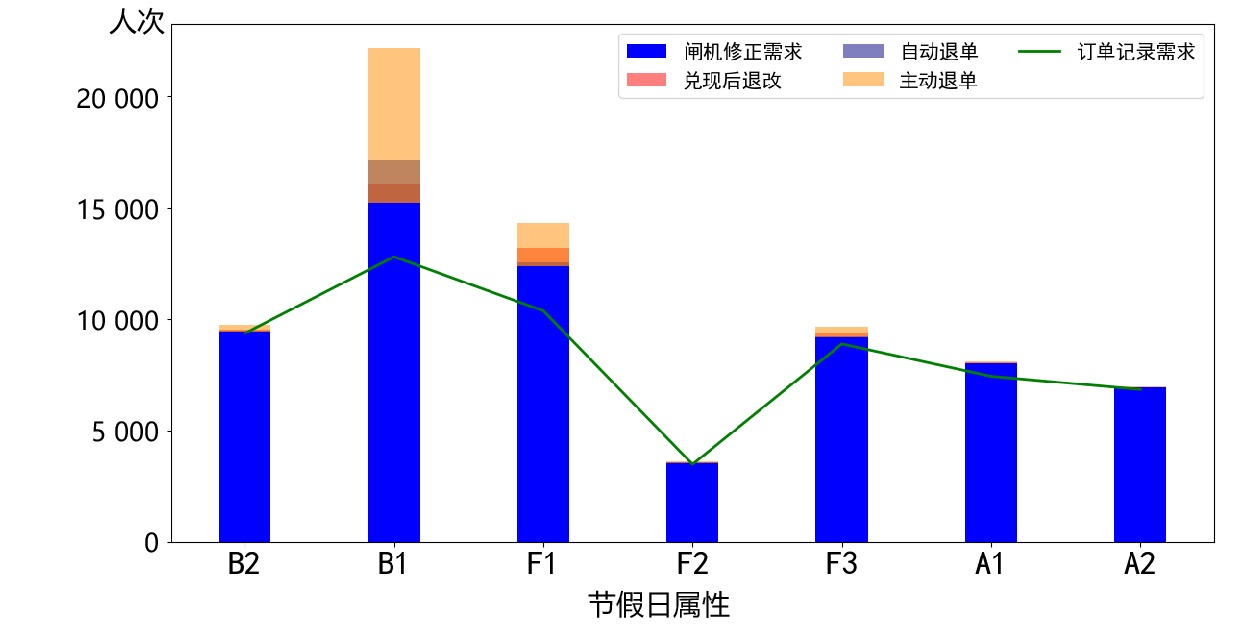
12799 人次,7天内客流合计59182 人次。候补购票订单的基本情况如表1所示。表1中给出了候补购票订单数和候补购票订单记录需求人数(简称:订单需求量),候补购票订单可包含多位出行人需求,因此,城市OD订单需求量一般大于候补购票订单数量。表 1 候补购票订单基本情况序号 乘车日期 候补购票订单数量 订单需求量 1 20240402(B2) 1324 1655 2 20240403(B1) 21841 31014 3 20240404(F1) 7505 12318 4 20240405(F2) 244 376 5 20240406(F3) 3487 5224 6 20240407(A1) 997 1174 7 20240408(A2) 570 630 清明假期北京—南京的城市OD候补购票行为分类情况如图4所示。可看出,在所有日期中,主动退单行为的旅客均占比较高,对应的出行需求存在不确定性;对于兑现成功部分,B1和F1的兑现成功数量相差不多,但在需求总量中占比不同,F1的兑现成功率更高;从兑现后退改的数量来看,尽管B1兑现难度大,仍然存在部分旅客在兑现成功后退票或改签的情况。
3.2 预售出行需求估计结果分析
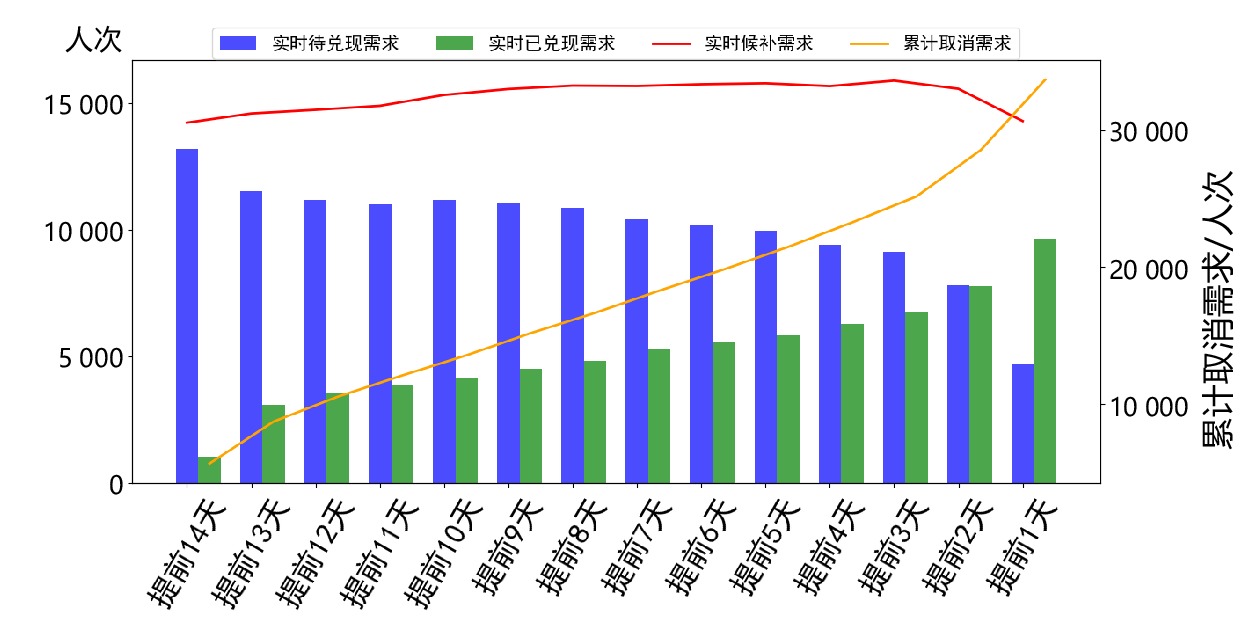
乘车日期为B1的预售出行需求变化如图5所示。累计取消需求指累计候补兑现失败的人数(主动取退单和自动退单),对应右侧坐标轴,其他3个指标对应左侧坐标轴。实时候补需求可分解为实时待兑现需求和实时已兑现需求,实时待兑现需求表征了当前时刻“候补中”的需求;已兑现需求表征了当前时刻已经兑现产生实际车票的需求,因其存在退票/改签的情况,在计算过程中进行了对应冲减。实时候补需求在预售期内基本维持在
15000 人次左右,累计取消需求随着时间推移逐步上升,最大超过30000 人次,直接统计订单需求量未能剔除累计取消需求的影响,导致需求估计产生 “虚高”的情况,影响决策结果。另外可看出,预售期内最后2天的实时待兑现需求明显下降,一部分因售票组织策略分解票额,将候补订单转化为已兑现需求,同时,部分旅客在临近假期前由于候补订单没有结果而取消候补,改变行程。3.3 最终出行需求估计结果分析
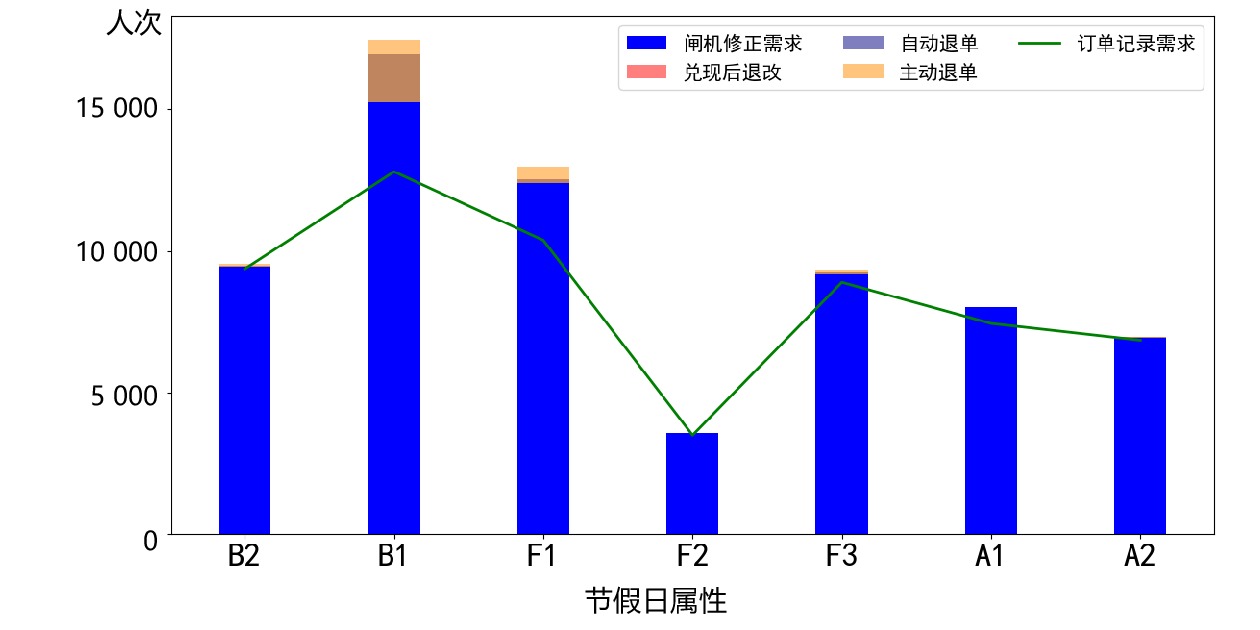
最终出行需求上限和下限估计值如图6、图7所示,可看出,B1和F1的闸机修正需求较订单记录需求已经明显增加,对应地,待估计受限需求偏高,即兑现后退改、自动退单、主动退单的3者之和。
而其他日期,闸机修正需求则接近订单记录需求,待估计受限需求对应偏小。最终出行需求较订单记录需求和闸机修正需求较订单记录需求趋势性吻合,验证了本文需求估计的合理性。
表1中,直观的订单需求量偏高,尤其是放假最后1天(4月6日),订单需求量超
5000 人次,经过本文提出的精细化方法挖掘候补需求,可看出,最终出行需求接近订单记录需求,即受限需求量较少,原因是此类旅客需求大部分转移至北京—南京的其他车次,但仍然属于北京—南京的城市OD,因此,从城市OD的维度,其需求是“未受限”的。对比不同候补购票行为对最终出行需求上限、下限的贡献程度,上下限差异主要来源于主动退单群体,此类旅客需求变化较大,需求更容易转移到其他列车或者铁路外部市场;而兑现后退改的旅客群体,在需求下限的计算过程中不予考虑,这也是造成差异的一种原因。
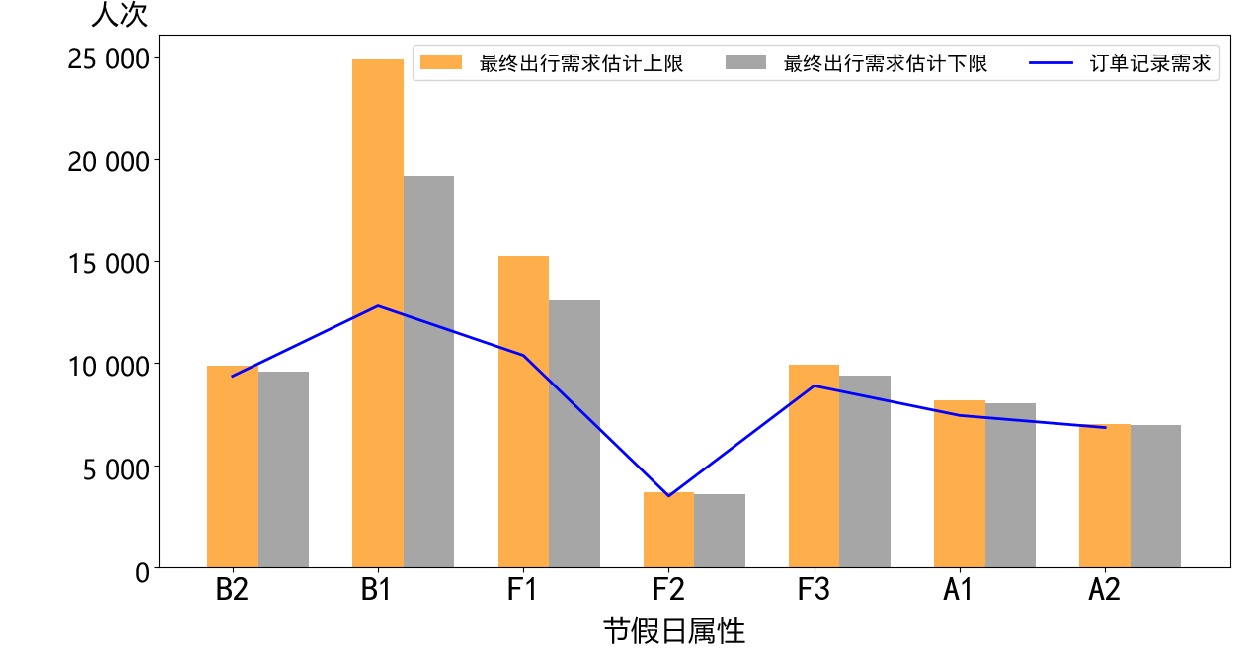
图8给出了最终出行需求估计上下限和订单售票曲线的关系,旅客出行需求受限主要集中在B1和F1,B1的需求上限甚至接近当前售票量的2倍,存在较大的潜在客运市场需求,此时若增加一定的运输能力,能够满足旅客出行需求,同时带来良好的收益;而F3和A1,对城市OD而言,需求缺口较小,这与候补订单直观的统计(表1中的订单需求量)规律不一致,若依据传统方法估计订单需求量开展决策,可能会造成运力资源的浪费,本文提出的方法可更加科学地估计城市OD的最终出行需求,能够为运营部门决策提供合理的数据支撑。
4 结束语
旅客出行需求在票额能力紧张时期受限程度较大,本文提出的需求估计方法能够合理地挖掘候补订单信息,还原“受限”场景下的真实旅客需求,为提升需求预测的精准性和客运营销决策分析的合理性提供科学数据支撑。后续研究中,将进一步扩展需求估计的颗粒度,结合不同的客运业务场景,将旅客出行需求估计细化为分时段和列车席位等多种维度。
-
表 1 候补购票订单基本情况
序号 乘车日期 候补购票订单数量 订单需求量 1 20240402(B2) 1324 1655 2 20240403(B1) 21841 31014 3 20240404(F1) 7505 12318 4 20240405(F2) 244 376 5 20240406(F3) 3487 5224 6 20240407(A1) 997 1174 7 20240408(A2) 570 630  下载: 导出CSV
下载: 导出CSV
-
[1] 卫铮铮,单杏花,王洪业,等. 基于客运大数据平台的铁路客流预测系统[J]. 铁路计算机应用,2022,31(1):37-42. DOI: 10.3969/j.issn.1005-8451.2022.01.06 [2] 骆泳吉,刘 军,马敏书. 客票数据“受限”条件下旅客选择偏好估计[J]. 交通运输系统工程与信息,2015,15(2):189-194. DOI: 10.3969/j.issn.1009-6744.2015.02.029 [3] 郭 鹏,周 杰. 航线网络中非参数需求非限化估计的MM算法[J]. 工业工程与管理,2023,28(4):107-120. [4] 单杏花. 铁路客运收益管理模型及应用研究[D]. 北京:中国铁道科学研究院,2012. [5] 郭 鹏. 需求信息缺失下的航空客运收益管理无约束估计方法研究[D]. 成都:西南交通大学,2014. [6] Désir A, Goyal V, Jagabathula S, et al. Mallows-smoothed distribution over rankings approach for modeling choice[J]. Operations Research, 2021, 69(4): 1206-1227. DOI: 10.1287/opre.2020.2085
[7] 卫铮铮. 基于客户分层的高速铁路收益管理需求预测研究[D]. 北京:中国铁道科学研究院,2015. [8] Azadeh S S, Marcotte P, Savard G. A non-parametric approach to demand forecasting in revenue management[J]. Computers & Operations Research, 2015 (63): 23-31.
[9] 李 雯. 12306候补购票服务系统的研究与实现[D]. 北京:中国铁道科学研究院,2019. [10] 王 煜,徐 彦,安仲文,等. 铁路候补购票兑现问题优化模型研究[J]. 铁道学报,2023,45(1):1-8. DOI: 10.3969/j.issn.1001-8360.2023.01.001 [11] 单杏花,王富章,朱建生,等. 铁路客运大数据平台架构及技术应用研究[J]. 铁路计算机应用,2016,25(9):14-16,30. DOI: 10.3969/j.issn.1005-8451.2016.09.004 [12] 阎志远,翁湦元,戴琳琳,等. 铁路客运大数据平台的数据采集技术研究[J]. 铁路计算机应用,2016,25(9):17-21. DOI: 10.3969/j.issn.1005-8451.2016.09.005 [13] 郭 鹏. 网络环境下收益管理系统需求无约束估计综述[J]. 计算机工程与应用,2017,53(19):17-25. DOI: 10.3778/j.issn.1002-8331.1706-0196 -
期刊类型引用(10)
1. 熊红康,周琪. 机务段整备调车防护系统总体设计和应用. 铁道机车车辆. 2025(S1): 45-50 .  百度学术
百度学术
2. 王丽丽. 机辆一体化数字生产管理平台的设计与应用. 铁路计算机应用. 2024(12): 55-58 . 本站查看
3. 刘国桐,张惟皎,喻冰春,苏浩天. 铁路司机电子手册设计及应用研究. 铁道运输与经济. 2022(03): 67-72 . 百度学术
4. 戴猛,杜懿佳,潘金山. 包神铁路集团机车调度系统功能设计. 铁道运输与经济. 2022(04): 22-29 . 百度学术
5. 戴猛,杜懿佳,潘金山. 基于机车周转图的包神铁路集团机车统计系统设计. 中国铁路. 2022(04): 27-34 . 百度学术
6. 慕治勇. 铁路机务运用安全管理系统的信息化研究. 内蒙古科技与经济. 2022(07): 86-89 . 百度学术
7. 杜晓明,戴猛,罗胜利. 基于实时推算的机车调度系统研究. 铁道运输与经济. 2022(S1): 85-90+96 . 百度学术
8. 沈晓瑜. 朔黄铁路机车调度系统设计. 铁路通信信号工程技术. 2021(05): 28-32 . 百度学术
9. 李道明,王甜甜. 铁路机务系统综合信息平台方案研究. 信息与电脑(理论版). 2020(20): 23-25 . 百度学术
10. 谢久峰. 铁路信息系统故障处理联动平台的研发与应用分析. 信息记录材料. 2019(12): 175-176 . 百度学术
其他类型引用(4)
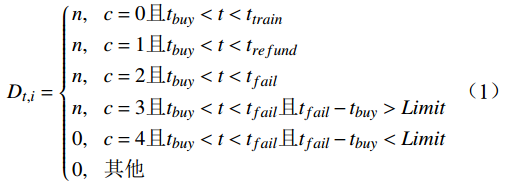
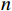
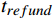
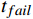
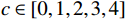
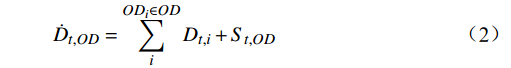
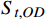
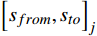
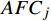
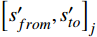
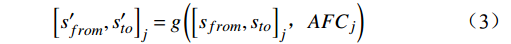
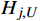
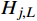

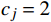
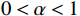

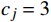
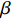

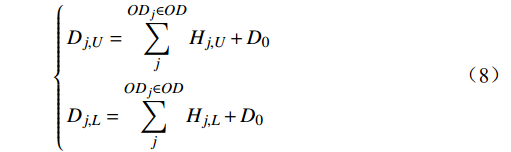
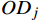
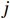
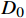
计量
- 文章访问数: 51
- HTML全文浏览量: 15
- PDF下载量: 20
- 被引次数: 14
