

Integrated BIM technology for design and construction of prefabricated U-grooves in railway subgrade
-
摘要:
为解决预制U型槽各构件设计深度不足、U型槽和泵站间接口复杂且易出现渗漏水病害、传统的预制构件外观质量检测手段效率低且精度不足的问题,开展铁路路基装配式U型槽设计施工一体化BIM技术研究。通过BIM深化设计,精细模拟钢筋、套筒、波纹管、下料孔等构件的空间位置关系,优化钢筋布置;进行泵站与U型槽主体结构一体化BIM设计,共用侧墙,消除二者连接薄弱点;制定预制U型槽外观质量检测标准,通过光学追踪激光扫描仪获取构件点云,开展关键尺寸分析处理,实现自动化外观质量检测。应用结果表明,该技术可有效降低钢筋干扰、增强设计整体性、提高外观质量检测的效率和精度,为铁路预制装配式结构提供了基于BIM的设计施工一体化解决方案。
Abstract:To solve the problems of insufficient design depth of prefabricated U-shaped groove components, complex interface between U-shaped groove and pump station, and low efficiency and accuracy of traditional prefabricated component appearance quality inspection methods, this paper researched on integrated BIM technology for the design and construction of prefabricated U-shaped grooves in railway subgrade. The paper conducted BIM deepening design, finely simulated the spatial position relationship of components such as rebar, sleeves, corrugated pipes, and feeding holes, and optimized the arrangement of steel bars; focused on the integrated BIM design of the pump station and U-shaped groove main structure, sharing side walls to eliminate weak connection points between the two; established a standard for the appearance quality inspection of prefabricated U-shaped grooves; obtained the component point cloud through an optical tracking laser scanner, and conducted the key dimension analysis and processing to implement automated appearance quality inspection. The application results show that this technology can effectively reduce rebar interference, enhance design integrity, improve the efficiency and accuracy of appearance quality inspection, and provide a BIM based integrated design and construction solution for railway prefabricated structures.
-
装配式工程具有成品质量高、节约材料、环境污染小、建设周期短、人工成本低等优势,其作为一种新型工业化生产方式,代表了铁路工程新的发展方向,也是近年来智能建造的主要研究对象[1]。BIM(Building Information Modeling)是一个涵盖设计到运营维护(简称:运维)全生命周期的管理工具,利用BIM进行设计、施工应用和建设管理,可解决项目建设过程中复杂的技术问题,提升铁路精细化管理水平、增加资源利用率。铁路工程BIM技术的应用研究已取得一定成果[2],包括建立BIM协同设计平台[3]、制定BIM标准体系[4]、研发BIM信息化施工管理系统[5]等。将以BIM为中心的众多前沿信息技术与装配式工程相结合,实现融合创新,从而推进铁路建造的精益、智慧、高效、绿色协同发展,成为未来铁路工程建设的发展方向,也是铁路工程智能建造内涵在装配式结构领域的具体实现。
张胜超等人[6]以郑州南站为例,基于BIM技术开展了装配式联方网壳雨棚智慧建造技术研究;王永等人[7]针对铁路预制装配式桥墩,面向其全生命周期管理需求,依托BIM+GIS技术开展了精细设计、工艺仿真、沉降监测、建设管理等方面的研究;侯宇飞等人[8]在京雄城际铁路桥梁装配式一体化段落开展了BIM+GIS数据集成应用研究;王志伟等人[9]提出基于企业资源计划(ERP,Enterprise Resource Planning)系统、轻量化BIM与RFID技术深度融合的预制装配式隧道工程智能建造系统。既有铁路装配式工程BIM技术的研究应用主要以装配式桥梁隧道和站房为对象,较少涉及装配式路基工程。
本文依托北京—唐山高速铁路(简称:京唐高铁)建设项目,开展装配式U型槽设计施工一体化BIM技术研究,相关成果可有效降低钢筋干扰、增强设计整体性、提高混凝土预制构件外观质量检测的效率和精度。
1 工程概况
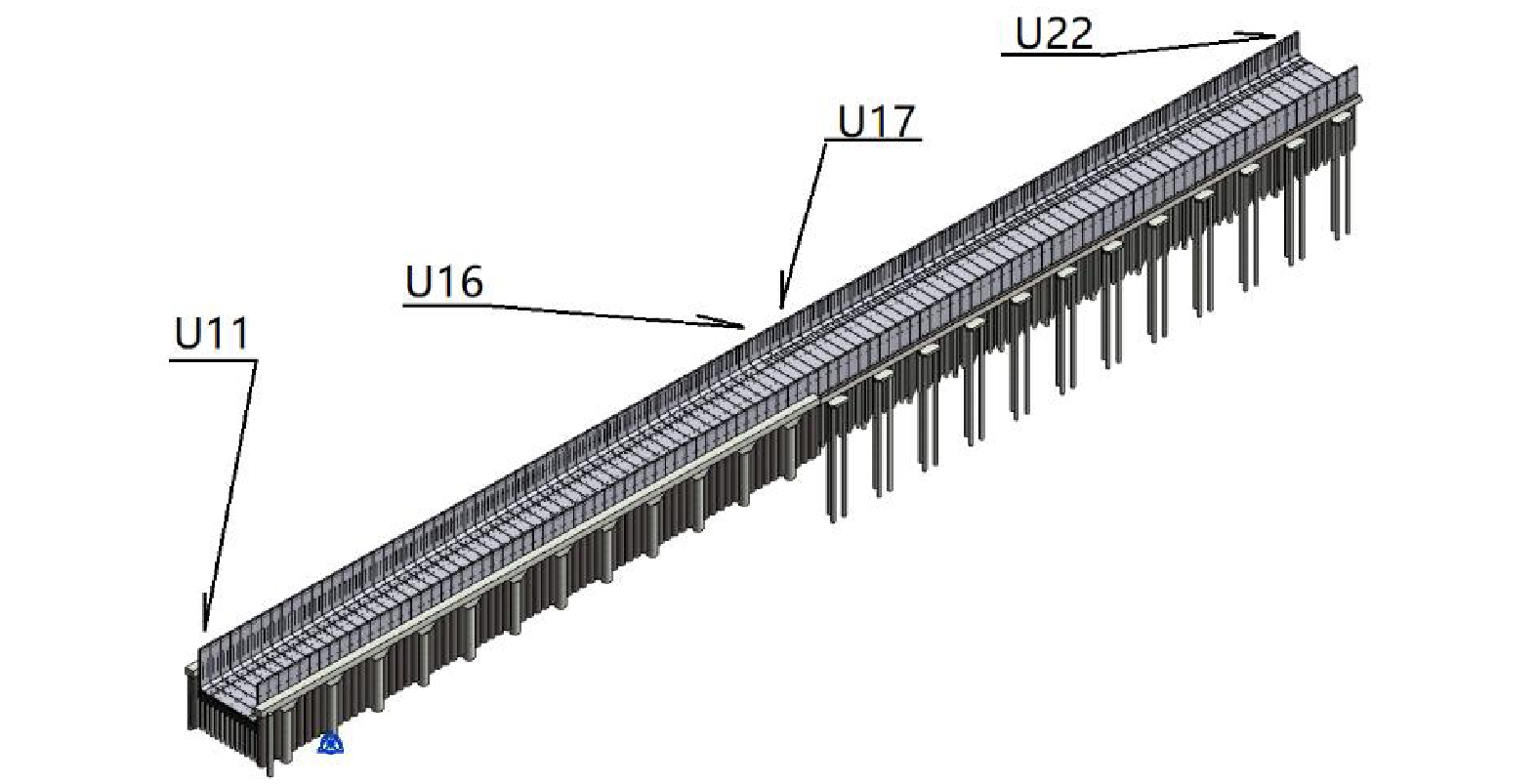
京唐高铁路基段落设置预制装配式U型槽,如图1所示。U11~U22采用C50防水钢筋混凝土预制,共12节,节长18 m。其中,U11~U16为路堑U型槽,边墙厚0.34 m,底板厚0.5 m;U17~U22为路堤U型槽,边墙厚0.4 m,底板厚0.5 m。
每单元拼装U型槽由2个L型墙及1块预制底板组成,构造复杂,设计、加工、装配精度要求高。为保证工程安全与质量,采用BIM技术对装配式U型槽开展预制构件深化设计、工程接口优化设计及外观质量自动化检测技术研究。
2 设计施工一体化BIM技术
2.1 预制构件BIM深化设计
对于每一环拼装U型槽单元,沿横断面方向,路堑段采用凹凸榫+交替布置直螺栓连接,路堤段采用凹凸榫+精轧螺纹钢连接,预制构件单元长度1.996 m;沿线路方向采用凹凸榫+精轧螺纹钢套筒连接。与现浇结构相比,预制装配式混凝土结构除了钢筋以外,还包含各类预埋装置,构造更加复杂。因此,在加工制造阶段,有必要对传统二维施工图成果进行深化设计,避免各类错漏碰缺问题。
2.1.1 钢筋BIM深化设计
对预制L型及一字型混凝土块体开展BIM深化设计,在Revit软件依次通过制作混凝土构件对象、设置保护层厚度、定制弯钩、制作形状族、放置并调整钢筋这5个步骤,创建钢筋模型。 最终形成包含纵向钢筋、横向钢筋、箍筋、直螺栓套筒、精轧螺纹钢套筒、预埋波纹管、预埋螺栓、预埋钢筋接驳器、振捣孔、下料孔在内的BIM深化设计成果,如图2所示。
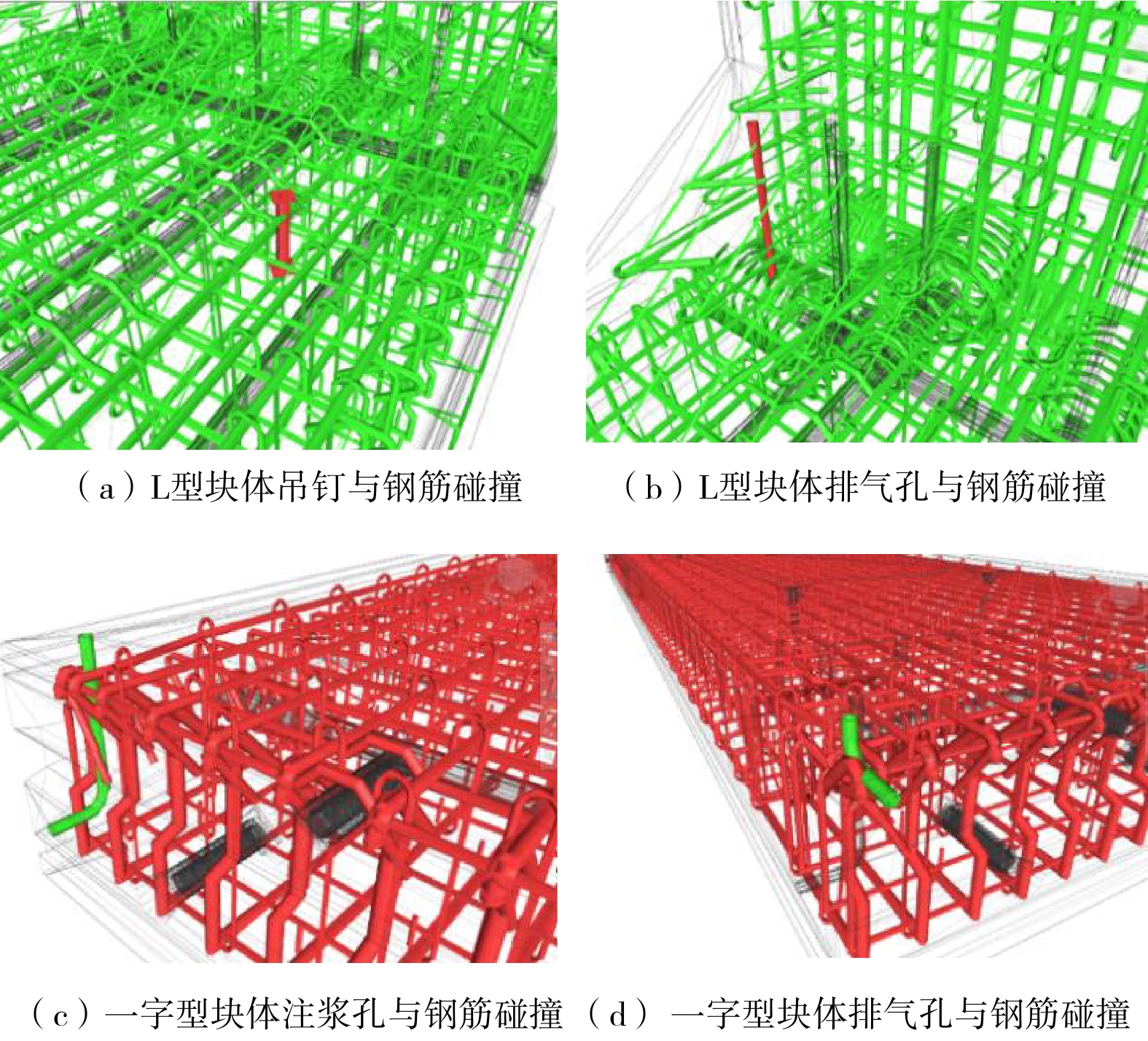
2.1.2 空间干涉检查深化设计
通过深化设计,检查各类预制块体是否存在吊钉、预埋锚栓、注浆孔、排气孔与普通钢筋之间的空间干涉问题,如图3所示。这些干涉问题在二维设计环境下很难察觉,根据检查结果修改钢筋位置,有效避免了构件预制加工过程的返工现象。
2.1.3 工程数量统计
精确创建所有钢筋对象BIM模型后,借助Revit软件的明细表功能,按规定格式快速统计各类预制块体钢筋工程数量。
在混凝土工程量计算时,传统方式一般不扣除体内的钢筋、预埋件及小型挖孔(如排气孔)的体积。BIM设计环境下,能够将钢筋、预埋件及挖孔模型的空间占位情况都精确地体现出来,为进一步准确计算构件混凝土工程量提供了基础,因此,可得到扣除后的混凝土体积。
2.2 工程接口BIM优化设计
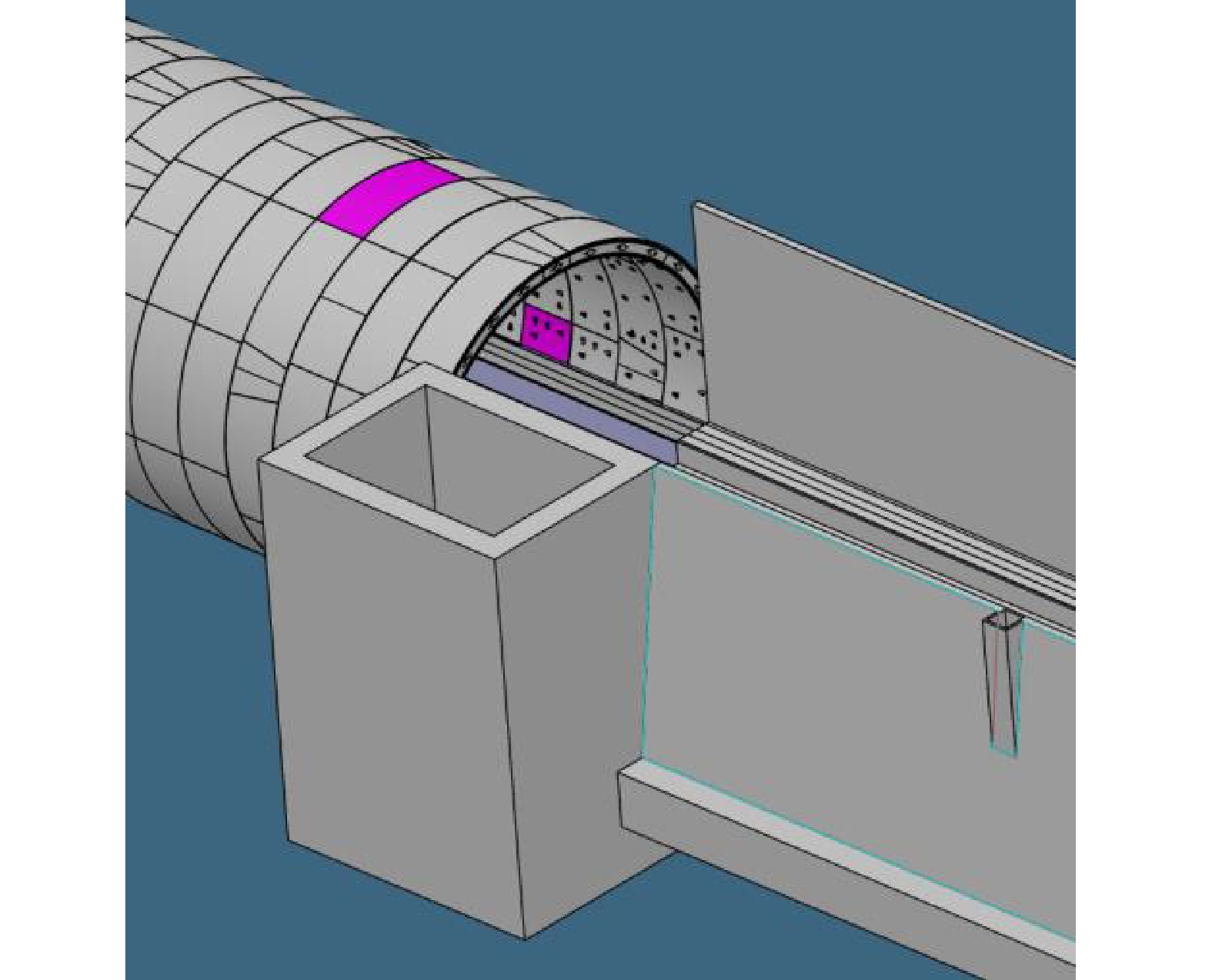
对于U型槽与泵站的接口,现阶段大部分高速铁路工程采用分设方案,将泵站设置在U型槽与隧道分界位置的U型槽一侧,距离U型槽结构5 m~10 m范围内单独建设泵房,通过管道连接U型槽结构和泵站,设计与施工接口多。
U型槽与管道连接主要有底板内布设和底板下布设这2种方式。管道自身、管道与U型槽连接处、管道与泵站连接处均暴露在土体中,易出现渗漏水病害。由于管道需要穿过U型槽的维护结构,增加了施工难度;同时,在运营过程中,强降雨工况下易出现机排渗水及泥土通过排水管道倒灌进入隧道等情况,影响列车通行。
为了提高工程整体质量、减少病害,在达索平台创建盾构管片环、U型槽、泵站的结构参数化工程模板,以空间坐标系为输入元素,通过工程模板实例化完成泵站与U型槽主体结构一体化BIM设计,如图4所示,泵站与U型槽结构共用侧墙,不存在暴露于土体中的管道及其连接薄弱点。
2.3 外观质量自动化检测
2.3.1 基于光学追踪激光扫描的三维数据获取
为满足大型构件三维数据采集需求,采用光学追踪三维激光扫描技术,该技术具有精度高、速度快、范围大的优点,且无须在检测构件上粘贴靶标。光学追踪三维激光扫描系统由三维激光扫描仪(简称:扫描仪)、智能光学追踪仪(简称:追踪仪)这2部分组成[10]。
由于一字型块体构造相对简单,本文重点介绍L型预制块体外观自动化检测的研究情况,采用国产扫描仪,对装配式U型槽的L型预制块体进行扫描,从而获取预制构件的三维点云数据。
扫描过程中,扫描仪始终处于移动变化状态,需要通过追踪仪完成坐标系固定。通过双目视觉追踪技术对360°可旋转的靶球进行追踪定位,而扫描仪设备则安置在靶球内部,与靶球之间属于刚性连接,使得追踪仪可直接对扫描仪进行定位。
2.3.2 预制构件三维检测数据分析
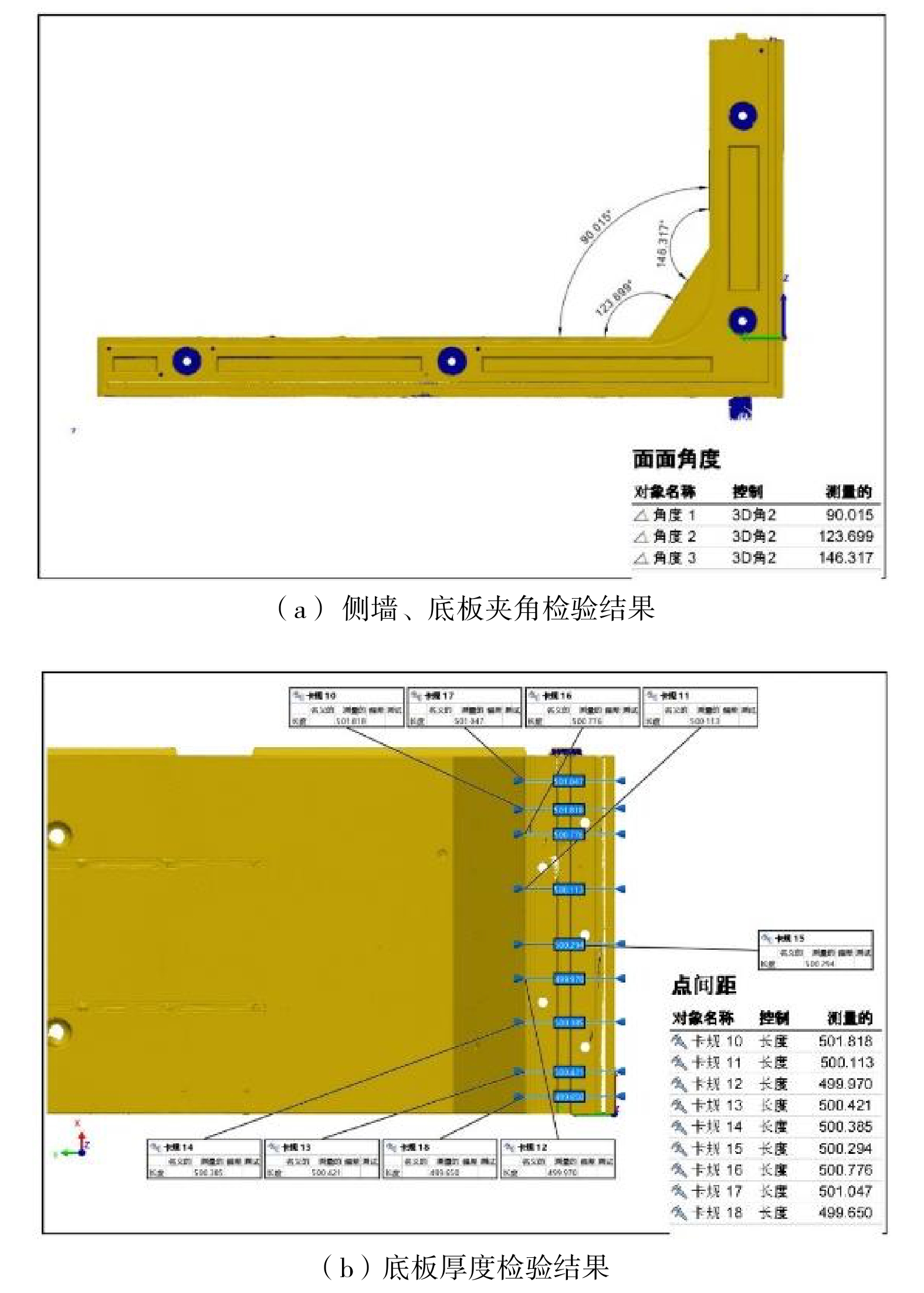
采用三维激光扫描手段获取高精度点云数据,分割每个面的点云,再基于分割后的点云重建各表面三维模型,最终在重建后的三维模型基础上自动计算U型槽外形尺寸,L型预制块体的部分外观尺寸检测结果如图5所示。
本项目采用铁路预制装配式U型槽结构,目前,国内尚无针对此类结构外观质量的专门规范,因此,综合参考《铁总科技[2013]125号(后张法)》《CJJT 164-2011盾构隧道管片质量检测技术标准》《高速铁路桥涵工程施工质量验收标准》(TB10752-2018)等技术文件和规范对无砟轨道板、盾构管片、装配式桥梁等预制构件外观质量的要求,制定预制U型槽构件外观质量检测标准。完成对U型槽L型预制块体的长、宽、厚、角度等关键尺寸的分析处理后,根据设计资料获取上述关键尺寸的理论数据,与检测结果比较,形成如表1所示的分析结果。
表 1 外观质量检测分析结果序号 尺寸类型 理论值 最不利
检测值容许差值 实际差值 结果 1 侧墙高度/mm 4610 4607.217 3 2.783 合格 2 节段长(负检测值)/mm 1996 1995.924 1 0.076 合格 3 节段长(正检测值)/mm 1996 1997.535 3 1.535 合格 4 底板厚度/mm 500 501.818 3 1.818 合格 5 侧墙与底板夹角/° 90 90.015 1 0.015 合格 可以看出,当前L型侧墙各尺寸检测结果均符合要求,侧墙高度的尺寸偏差与容许值最为接近,需要在剩余节段预制过程中多加注意。
3 应用效果
本文研究的装配式U型槽设计施工一体化BIM技术已在京唐高铁建设项目成功应用,结果如下:
(1)使用Revit软件开展预制L型及一字型混凝土块体BIM深化设计,精细化模拟钢筋、套筒、波纹管、下料孔等的空间位置关系,进行干涉检查,优化钢筋布置,自动统计工程数量,有效避免构件预制加工阶段的返工现象;
(2)针对目前高铁U型槽与泵站分设方案易出现渗漏水病害的问题,通过BIM手段开展泵站与U型槽主体结构一体化设计,二者共用侧墙,使得泵站与U型槽间不存在暴露在土体中的管道及连接薄弱点;
(3)调研铁路预制工程有关技术文件,制定预制U型槽外观质量检测标准;通过光学追踪激光扫描仪获取预制构件点云,开展预制块体关键尺寸分析处理,与理论尺寸及检测标准比较,形成分析报表,实现外观质量自动化检测。
4 结束语
本文研究铁路路基装配式U型槽设计施工一体化BIM技术,详细阐述钢筋混凝土预制构件BIM深化设计、工程接口BIM优化设计、基于三维激光扫描的预制构件外观自动化检测技术,将其应用于铁路工程实际设计与施工,验证了该技术路线在铁路行业的适用性。未来将进一步增强BIM技术在铁路工程智能运维领域的应用广度和深度,实现BIM技术的铁路工程全生命周期应用价值。
-
表 1 外观质量检测分析结果
序号 尺寸类型 理论值 最不利
检测值容许差值 实际差值 结果 1 侧墙高度/mm 4610 4607.217 3 2.783 合格 2 节段长(负检测值)/mm 1996 1995.924 1 0.076 合格 3 节段长(正检测值)/mm 1996 1997.535 3 1.535 合格 4 底板厚度/mm 500 501.818 3 1.818 合格 5 侧墙与底板夹角/° 90 90.015 1 0.015 合格  下载: 导出CSV
下载: 导出CSV
-
[1] 高明昌. 铁路装配式桥梁研究与应用综述[J]. 铁道建筑技术,2023(9):5-9,19. DOI: 10.3969/j.issn.1009-4539.2023.09.002 [2] 张贵忠. 沪通长江大桥BIM技术应用的总结与思考[J]. 中国铁路,2018(11):88-93. DOI: 10.19549/j.issn.1001-683x.2018.11.088. [3] 张 轩,黄新文,李 纯,等. 基于铁路工程的数字化协同设计平台应用研究[J]. 铁道标准设计,2023,67(10):47-54. DOI: 10.13238/j.issn.1004-2954.202306050001. [4] 郭 芳,李达塽,贺晓玲,等. 中国铁路数字工程体系研究[J]. 工程建设标准化,2023(10):76-83. DOI: 10.13924/j.cnki.cecs.2023.10.015. [5] 王焕松,于胜利,卢文龙,等. 基于BIM的企业级铁路施工管理平台研究[J]. 铁道标准设计,2023,67(2):55-59,123. DOI: 10.13238/j.issn.1004-2954.202111020001. [6] 张胜超,靳小飞,赵兴哲,等. 郑州南站装配式联方网壳雨棚智慧建造技术[J]. 智能建筑,2022(3):39-42. [7] 王 永,齐成龙. 基于BIM+GIS技术的预制装配式桥墩全生命周期解决方案[J]. 市政技术,2021,39(4):63-67. DOI: 10.19922/j.1009-7767.2021.04.063. [8] 侯宇飞,杨 斌,吴明杰,等. BIM+GIS数据集成技术在铁路桥梁施工管理的应用[J]. 铁路技术创新,2020(3):29-33. DOI: 10.19550/j.issn.1672-061x.2020.03.029. [9] 王志伟,马伟斌,王子洪,等. 基于轻量化BIM、RFID技术与ERP系统的预制装配式隧道结构智能建造系统[J]. 中国铁路,2020(1):16-21. DOI: 10.19549/j.issn.1001-683x.2020.01.016. [10] 张立宇. 地铁盾构隧道管片流水线生产智能化技术[J]. 现代城市轨道交通,2022(11):47-52. -
期刊类型引用(1)
1. 刘星. 铁路桥梁深基坑智能监测技术研究与应用. 铁路技术创新. 2022(04): 118-124 .  百度学术
百度学术
其他类型引用(1)

计量
- 文章访问数: 24
- HTML全文浏览量: 4
- PDF下载量: 5
- 被引次数: 2
