

Image identification of station signal plan based on OpenCV
-
摘要:
为实现异构车站信号平面图图纸数据格式的统一,结合车站信号平面图(简称:平面图)中各模块的形态特征分析与逻辑关系,提出基于OpenCV的图像识别方法以对平面图中主要的站场信号设备进行图像识别。将CAD平面图统一转化为相同分辨率及尺寸的PNG格式图像,采用灰度化和边缘检测算法进行图像预处理,得到站场的轮廓;分析平面图结构,利用Hough圆检测与直线检测实现平面图元的特征提取;根据识别到的圆与直线段,结合每种站场信号设备的属性特点及其之间物理连接的逻辑关系,分别设计识别方法。试验结果表明:基于OpenCV的图像识别方法可较为准确、完整地识别出各类站场信号设备,并获得每个设备相关的站场数据。
Abstract:To implement the standardization of data format for heterogeneous station signal plan drawings, this paper proposed an image identification method based on OpenCV by analyzing the morphological characteristics and logical relationships of each module in the station signal plan (referred to as the plan) to identify the main station signal equipment in the plan. The paper converted CAD floor plans into PNG format images of the same resolution and size, and used grayscale and edge detection algorithms for image preprocessing to obtain the contour of the station, analyzed the structure of the floor plan and use Hough circle detection and line detection to extract features of the floor plan elements, and based on the identified circles and straight line segments, combined with the attribute characteristics of each station yard signal equipment and the logical relationship of the physical connections between attribute characteristics to design identification methods separately. The experimental results show that the OpenCV based image identification method can accurately and completely identify various types of station yard signal equipment, and obtain station yard data related to each equipment.
-
Keywords:
- station signal plan /
- OpenCV /
- image identification /
- feature extraction /
- Hough detection
-
车站信号平面图(简称:平面图)是车站信号系统设计的一部分,为车站联锁及相关系统的设计、研制和现场施工提供重要依据,其传统的绘制方式是由相关技术人员手动绘制,主要借助CAD软件实现铁路站场辅助设计。因平面图由不同的设计人员绘制,图纸数据格式不统一,导致数据无法直接使用,使得联锁及其相关系统必须重复编制数据,自动化程度较低[1-2]。CAD二次开发技术的推广应用在一定程度上提高了设计人员的工作效率,文献[3—5]均采用AutoCAD系统环境下的二次开发技术,实现平面图信号设备信息的识别提取,从而建立平面图数据信息库,实现信号图纸工程参数化、标准化设计,但需要设计人员以统一标准对图元进行组块,人工定义每个模块的属性信息,且开发环境单一,可移植性差。
目前,图像识别技术已应用到铁路的诸多领域,尤其在信号检测和轨面检测方面有较为广泛的研究。文献[6]提出一种主成分分析和圆拟合与分段随机 Hough 变换圆检测相结合的信号灯检测方法,适用于对复杂环境中调车信号灯的准确检测和定位;文献[7]提出一种基于实时视觉检测系统的轨道表面缺陷检测算法,该算法已在216 km/h速度的检测列车上通过实验验证;文献[8]提出基于数据挖掘的平面图图像信息提取算法,该算法准确率较高。
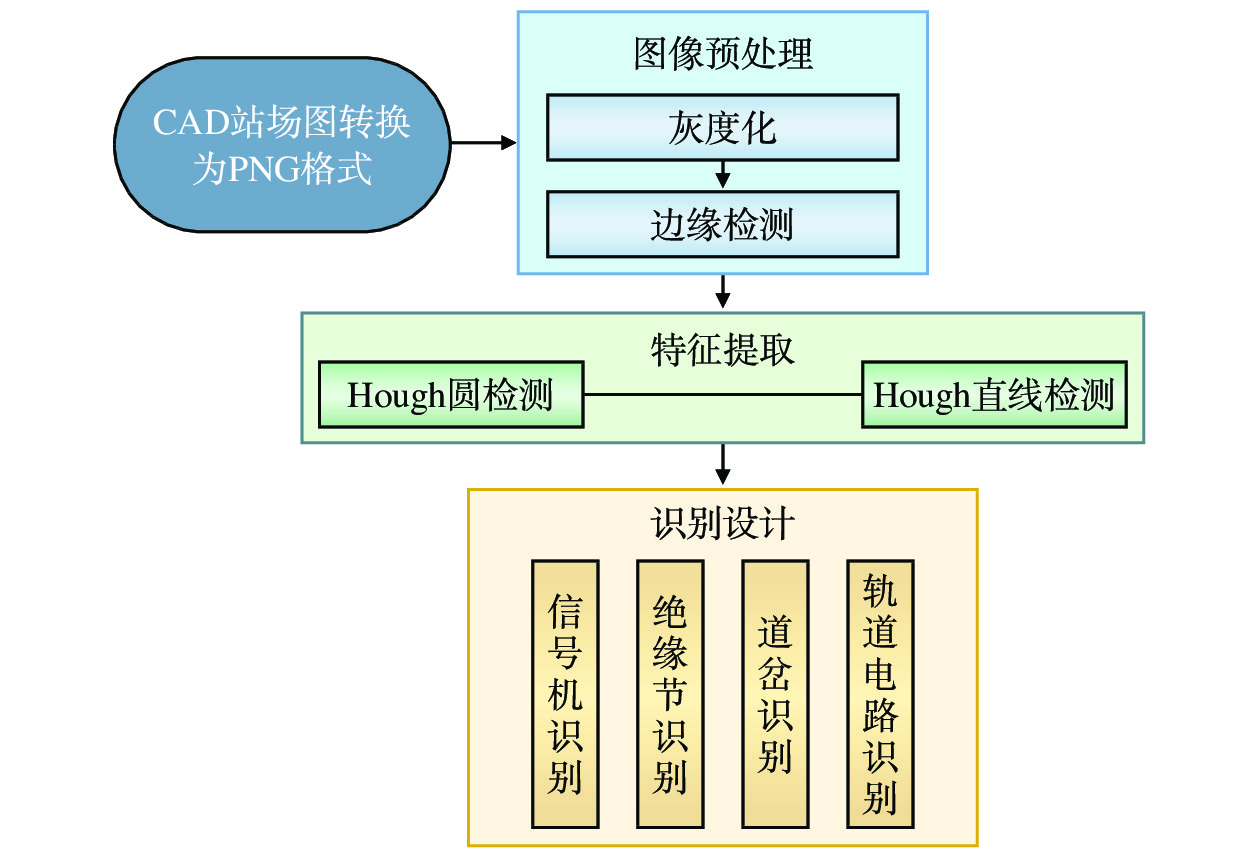
本文以PyCharm为开发平台,针对平面图中主要元素的图像形态学特征,基于OpenCV的图像识别技术,设计信号基础设备的图像识别方法,提取平面图内所包含的信号机、道岔、轨道电路等信号设备的数据信息,形成站场数据,为异构平面图的标准化提供依据,提高联锁工程设计的自动化程度。
1 平面图图像预处理
CAD格式的平面图(简称:CAD平面图)描述了联锁区及其相关的非联锁区范围内的线路布置情况,是编制联锁控制数据的根本依据。主要包含的站场设备有信号设备(信号机、道岔等)、线路设备(轨道电路等)、客货运设备(站台等)和其他附属设备。CAD平面图不能直接用来自动编制联锁控制数据,本文将CAD平面图人工转换为站场图像,再利用图像识别技术获取可处理的站场信号设备信息。
CAD绘制的平面图文件通常为DWG格式,若将其转换成PDF文件,则分辨率达不到图像识别的要求,且站场设备的绘制尺寸不统一,影响识别结果。本文将CAD绘制的矢量图转换为PNG格式图像,信号机图标中圆的直径统一为5 mm,分辨率为500 dpi,以解决平面图尺寸标准各不相同的问题,再利用灰度化和边缘检测方法进行图像预处理,提高图像的质量,突出目标特征,从而满足应用需求[9]。
1.1 灰度化
处理后的PNG格式平面图的颜色模型为RGB,每个颜色通道有256个变量。这些颜色信息对本文的图像识别方法无特别影响,且占用大量存储空间,为降低运算复杂度,需要将图像进行灰度化处理。转换后的灰度图像不仅保留了原色彩图像的基本结构,且缩短了运算时间。本文采用加权平均值法对平面图进行灰度转化,Gray表示图像灰度值,其公式为
$$ {{Gray}}=0.2989\cdot {{R}}+0.5870\cdot{{G}}+0.1140\cdot{{B}} $$ (1) 式(1)中,R为红色分量;G为绿色分量;B为蓝色分量。
1.2 边缘检测
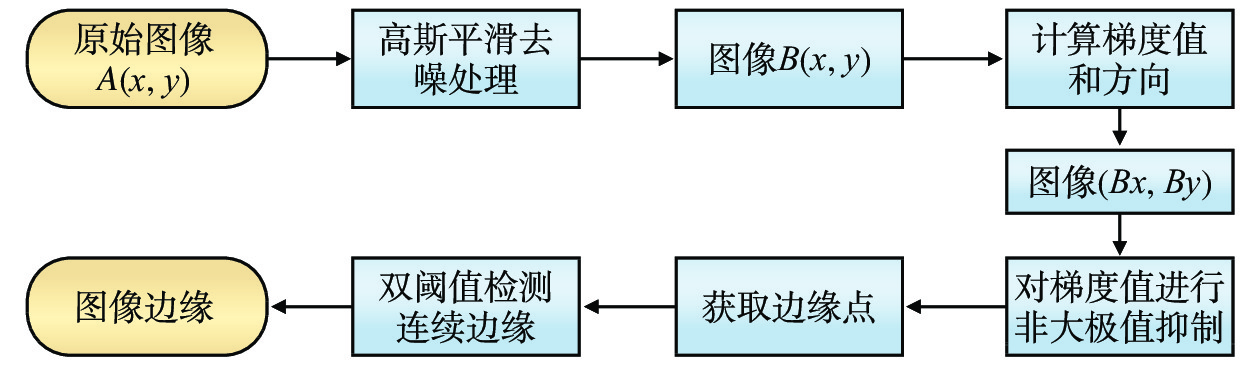
边缘检测是图像分割和特征提取的必要前提。所谓边缘是指图像局部亮度或灰度出现跃变的像素集合[10],而边缘检测是将这些反映图像特征急剧变化的点集以离散点的形式表示出来。本文采用基于二维高斯滤波的Canny边缘检测算法进行边缘检测,其主要优势为:(1)图像边缘点的误识别率与漏识别率较低;(2)噪声干扰小,使得图像检测边缘与图像实际边缘的误差小,定位精确;(3)图像检测边缘与图像实际边缘的像素点在像素坐标上一一对应。Canny边缘检测算法流程如图1所示。
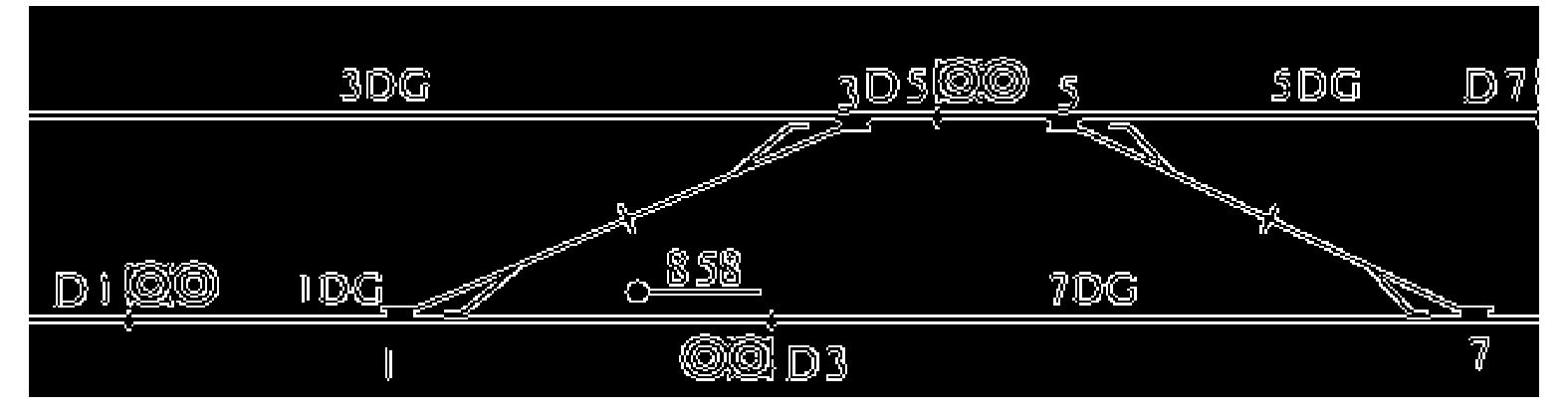
某车站局部平面图经过图像预处理后的效果如图2所示,边缘检测的效果较好,车站各信号设备轮廓完整清晰,为后续工作打下良好基础。
2 平面图识别方法设计
2.1 平面图特征分析与特征提取
本文主要对平面图中的信号机、绝缘节、道岔和轨道电路进行识别研究。这些站场信号设备的形状结构均由圆和直线段构成,形状特征明显、边界清晰,易于从周围环境中区分开。平面图作为2D图像,反映出的形状信息与人视觉系统感受到的一致,不存在视点上的失真。本文采用轮廓特征法Hough的圆检测与直线检测,分别将目标信息提取出来。
2.1.1 Hough圆检测
数字图像中目标圆的一般表达式为
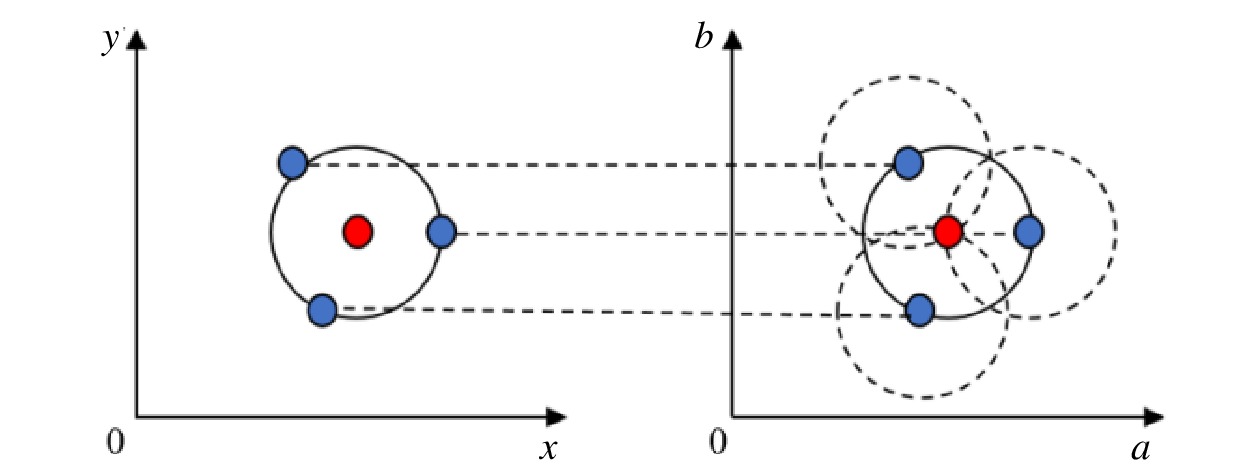
$${{{(x-a)} ^{ {2} } {+(y-b)} ^{{2} } =r ^{ {2} }}} $$ (2) 式(2)中,r为半径;(a, b)为圆心坐标。Hough圆检测原理如图3所示,将2D轮廓圆图像的0-xy坐标空间转换成参数空间0-ab,0-xy坐标中圆边界上的1个点对应到0-ab坐标中为1个圆,即在0-xy中1个圆周上各个点组成的集合在0-ab中表现为半径相等,而圆心坐标不等的各个圆锥的集合[11]。基于Hough圆检测的站场信号设备圆特征提取效果如图4所示。
2.1.2 Hough直线检测
在笛卡尔坐标系0-xy中,设直线斜率为k,与y轴的截距为b,公式为
$$ {y=kx+b}$$ (3) 但是存在垂直于x轴的直线斜率无法表示的情况,需要将笛卡尔坐标系转换到极坐标系0-dθ,由参数极径d和极角θ表示[12],则其公式为
$$ {d=x{\mathrm{Cos}}\theta +y{\mathrm{Sin}}\theta } $$ (4) 相似于Hough圆检测0-xy坐标空间与0-ab参数空间的转换关系,在笛卡尔坐标系直线上的1点可映射为极坐标系0-dθ上的1条正弦曲线,则曲线上的公共交点(d',θ')是所求直线的极坐标参数,如图5所示。OpenCV中的HoughLinesP函数相对于HoughLines函数计算代价更小,可检测到直线段两端端点,基于Hough直线的站场信号设备直线特征提取效果如图6所示。
2.2 信号机识别设计
信号机是保障行车安全的关键设备,用于向机车司机传达机车车辆运行条件、行车命令及设备状态等信息。信号机一般分为调车信号机、进站/出站信号机、通过信号机、遮断信号机和驼峰信号机等。本文针对进站信号机、出站信号机和调车信号机3种常用信号机进行研究识别。
2.2.1 信号机识别
通过Hough圆检测得到图中所有圆图像的圆心坐标与半径信息,信号机包含的圆图像大多两两相切,形成一个连通域才可判断为信号机,否则,单独的圆可能是超限绝缘或文字符号。从圆到信号机的识别过程为:(1)将检测到的圆按x坐标从小到大排序,一架信号机最多包含5个灯位,以当前y坐标最小的灯为主灯位;(2)从上到下开始搜索,每次在灯位表更新主灯位,寻找y坐标和主灯位相差小于阈值的所有圆,形成连通域,即判定为信号机。
2.2.2 信号机分类
根据信号机的特点对其进行分类。调车信号机的特点为2个圆水平相切;进站信号机的特点为水平方向上包含5个圆,其中,4个圆水平相切;出站信号机的特点为有4个圆呈正方形排列在水平、竖直方向,两两相切。再由颜色重心法区分信号机的上行和下行方向,具体流程如图7所示。
2.3 绝缘节识别方法
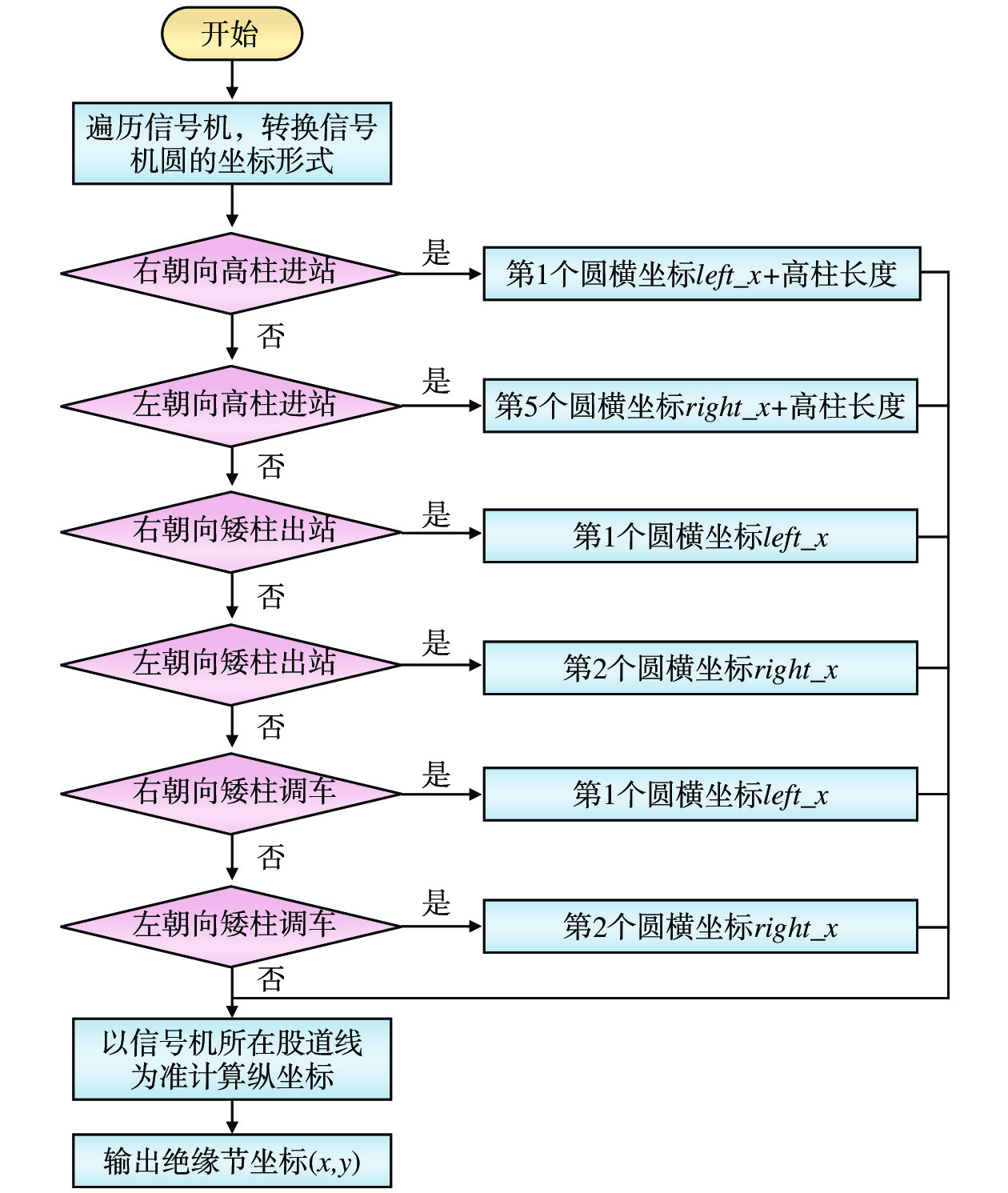
绝缘节是保障铁路运输通信质量的电气绝缘设备,用于避免相邻线路间发生电容耦合、电感耦合等轨道电路干扰问题。其形状特征多以垂直于轨道电路的短小直线段为主,由于无法直接通过Hough直线检测到,考虑到一般绝缘节会根据信号机灯柱设置,因此,一般绝缘节的识别需要参考信号机的坐标信息进行判断,在已知信号机朝向、类型等属性前提下,将信号机中圆的(a,b,r)坐标转换成笛卡尔坐标(left_x, left_y, right_x, right_y) ,其中,left_x = a-r;left_y = b-r;right_x = a+r;right_y = b+r。绝缘节纵坐标以信号机所在股道线为准,其横坐标具体计算流程如图8所示。
2.4 道岔识别方法
道岔是实现股道转换的重要设备,它的基本形式有3种,即线路的连接、交叉、连接与交叉的组合,常见类型包括单动、双动和交叉渡线等3种。其识别步骤为:(1)通过边缘检测筛选矩形块定位道岔岔尖位置,并检测筛选与其相连接的斜线段,以判断道岔整体所在位置;(2)根据斜线段端点计算斜率k,以判断道岔开向;(3)由斜线段端点分别向上和向下取道岔所属的矩形范围,计算该范围内各个端点的灰度值均值,通过超出阈值的灰度值均值的个数以判断道岔类型,1个判断为单动道岔,2个判断为双动道岔,4个判断为交叉渡线。
由于不同种类的道岔外形特征相似,但同一类道岔由于功能定位不同存在异构,如图9所示,以单动道岔的普通型和提速型2种不同的绘制形式为例,需要判断斜线分支的斜率是否在阈值范围内,若在阈值范围内则认为是同一单动道岔。同时,结合后续轨道电路有岔与无岔的属性判断,需进一步将双动道岔按其绝缘节所在位置(通常为道岔连接线中点)划分为上下2部分,其上下2部分隶属于不同的轨道区段,此内容将在轨道电路识别方法中作具体说明。
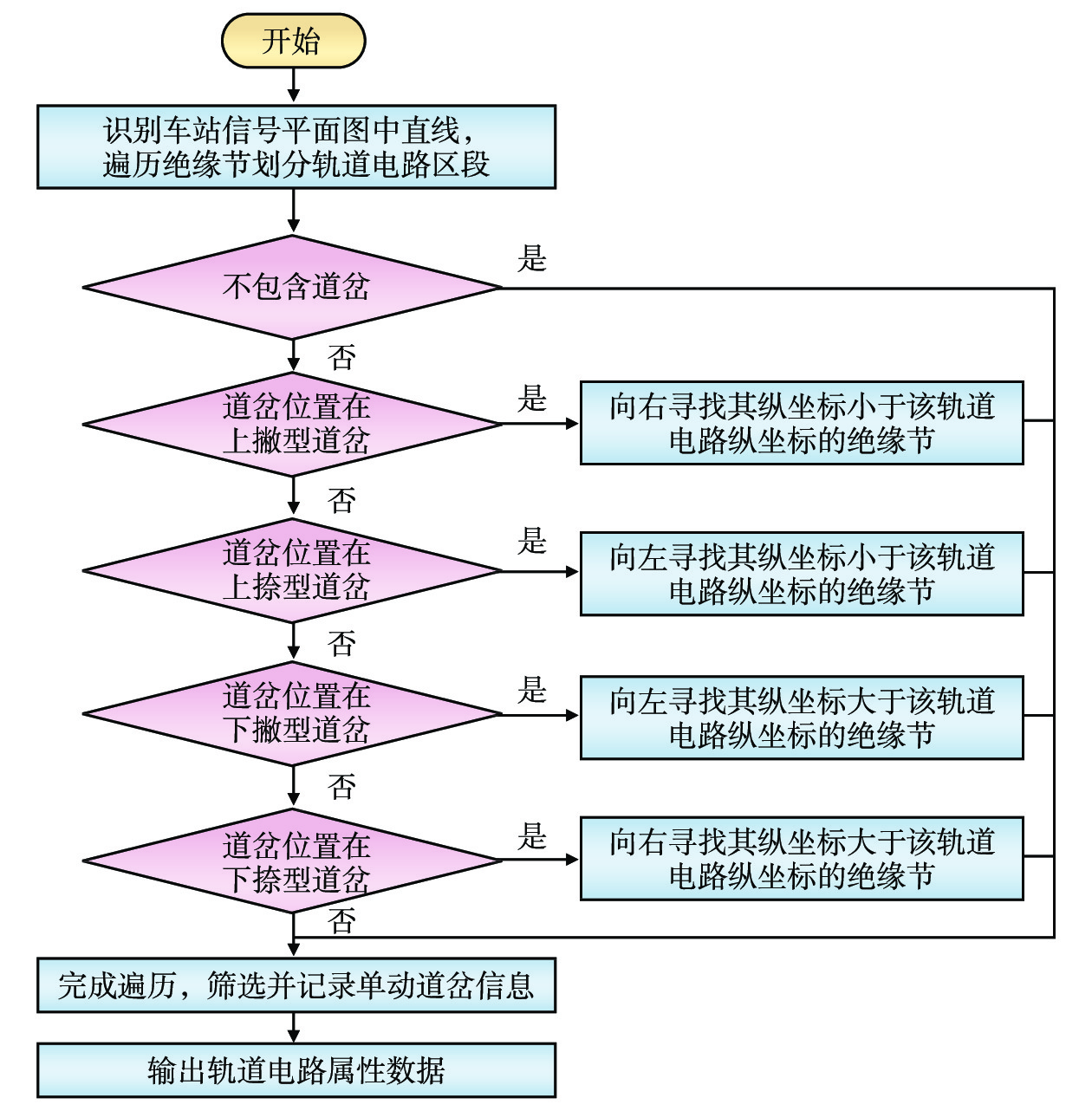
2.5 轨道电路识别方法
轨道电路用于监督列车的行车状态并传递行车信息。在平面图上的形状特征为连续的长直线段,水平方向上的直线段长于其他直线段,需要通过遍历绝缘节得到轨道电路横坐标,从而将轨道电路划分为多个独立区段。
划分水平方向上的轨道电路后,需要判断区段内是否存在道岔并筛选出双动道岔数据,再结合道岔撇型和捺型开向以与区段作连接,在图形上表现为水平方向的直线段与短斜线段的集合;区段内若是包含上行咽喉单动道岔,则道岔线段末端水平向右延伸寻找最近绝缘节;若是下行咽喉,则道岔线段末端水平向左延伸寻找最近绝缘节,以此完善所有轨道区段的识别。轨道电路识别的具体流程如图10所示。
3 平面图识别效果与分析
本文在PyCharm+Anaconda编译环境下,集成OpenCV库环境,采用Python语言进行平面图图像识别。实现流程如图11所示。
3.1 信号机图像识别效果
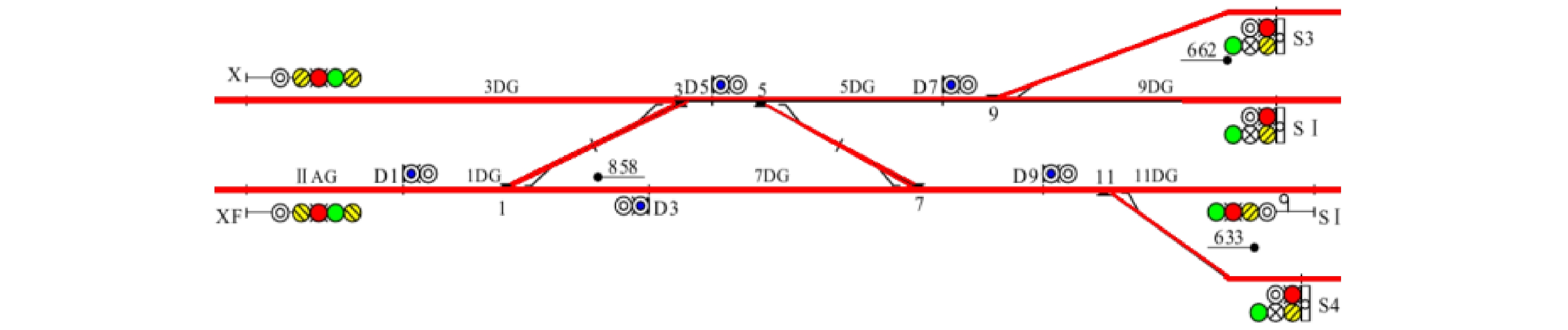
信号机的图像识别数据以(x1, y1, x2, y2, x3, y3, x4, y4, x5, y5, type, direct, circlenum)形式进行输出,各字段含义如表1所示。识别效果如图12所示。
表 1 信号机图像识别数据字段说明字段 类型 备注 x1 int 灯位1圆心横坐标 y1 int 灯位1圆心纵坐标 … … … x5 int 灯位5圆心横坐标 y5 int 灯位5圆心纵坐标 type tinyint 信号机的类型(0=出站,1=进站,2=调车) direct tinyint 朝向(0=右朝向,1=左朝向) circlenum tinyint 灯位数 3.2 绝缘节识别效果
绝缘节的图像识别数据主要为其坐标,该坐标也是识别道岔和轨道电路的基础。数据以(x1, y1, type)形式进行输出, 各字段含义如表2所示。识别效果如图13所示。
表 2 绝缘节图像识别数据字段说明字段 类型 备注 x1 int 绝缘节横坐标 y1 int 绝缘节纵坐标 type tinyint 所属的咽喉区(1=普通,2 =超限) 3.3 道岔图像识别效果
道岔的图像识别数据以(x1, y1, x2, y2, direct, type, pos)形式进行输出,各字段含义如表3所示,其中,pos是指在包含绝缘节的道岔中,以绝缘节为中心将道岔划分为上撇形、上捺形或下撇形、下捺形,为后续轨道电路的划分识别做铺垫。道岔图像识别效果如图14所示。
表 3 道岔图像识别数据字段说明字段 类型 备注 x1 int 道岔端点1横坐标 y1 int 道岔端点1纵坐标 x2 int 道岔端点2横坐标 y2 int 道岔端点2纵坐标 direct tinyint 朝向(1=撇形,-1=捺形) type tinyint 类型(0:单动道岔、1:双动道岔、2:交叉渡线) pos tinyint 道岔划分(0=上,1=下) 3.4 轨道电路图像识别效果
轨道电路的图像识别数据以(x1, y1, x2, y2, x3, y3, track_t, x00, y00, x01, y01, x10, y10, x11, y11, k2, p2, type)形式进行输出,各字段含义如表4所示,其中,道岔分支斜率为0的无效区段数据默认为0,有效部分参考直线端点与绝缘节横坐标,识别效果如图15所示。
表 4 轨道电路图像识别数据字段说明字段 类型 备注 x1 int 轨道电路包含的绝缘节横坐标 y1 int 轨道电路包含的绝缘节纵坐标 … … … track_t tinyint 所包含的道岔类型 … … … x10 int 包含的道岔2端点1的横坐标 y10 int 包含的道岔2端点1的纵坐标 x11 int 包含的道岔2端点2的横坐标 y11 int 包含的道岔2端点2的纵坐标 k2 tinyint 道岔2朝向(1=撇形,-1=捺形) p2 tinyint 道岔2划分区段(0=上,1=下) type tinyint 轨道电路的类型(0=无岔,1=有岔) 3.5 图像识别效果分析
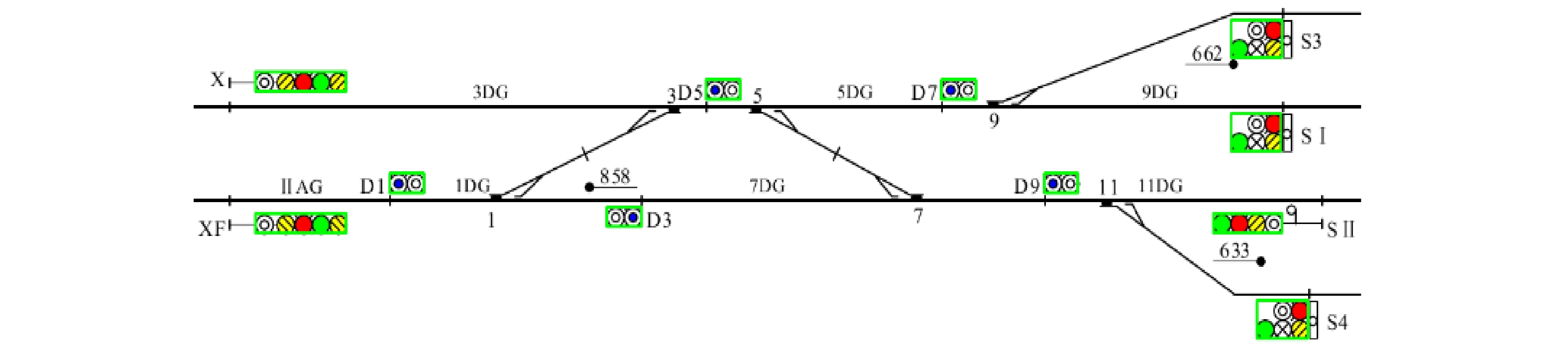
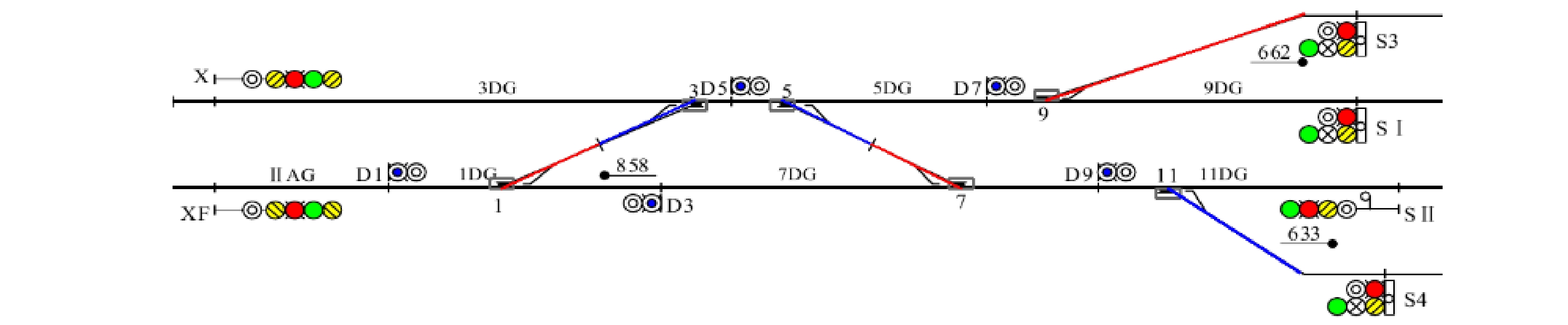
平面图识别的首要目标是要正确地识别出各个站场设备并获得其相关属性,在准确率足够高的情况下进一步满足通用性,使得图像识别方法适用于各类平面图。通过对示例站场(上行方向)进行图像识别,并输出识别效果图及设备类别和属性,可证明本文平面图图像识别方法的准确率为100%。但本文所选示例平面图的站场结构较为简单。
除示例站场外,本文通过不同业务性质的平面图对方法的正确率进行验证,验证结果如表5所示,除轨道电路的识别率略低外,其他类别设备的识别率均在93%以上。实验中的误识别率基本上是由识别中阈值的设定导致,平面图规模的不同导致每类信号设备分辨率有差异,后续将考虑用更多不同种类的平面图进行参数优化调试。
表 5 图像识别方法验证结果设备类别 实际个数 正确识别个数 误识别个数 识别率 信号机 204 198 6 97% 绝缘节 223 207 16 93% 道岔 174 162 12 93% 轨道电路 240 203 37 85% 4 结束语
本文利用OpenCV在图像预处理阶段对站场平面图内的特征元素进行有效提取,为平面图图像识别的后续工作打下基础;详细介绍了几种站场信号设备的识别方法,试验表明,该方法的识别率较高,其生成的站场数据可为3D铁路站场的重绘和联锁表的自动化测试提供良好保障。但由于平面图种类繁多,复杂程度相差较大,因此,该方法用在不同平面图的识别准确率有差别,仍需要进一步改进和优化。
-
表 1 信号机图像识别数据字段说明
字段 类型 备注 x1 int 灯位1圆心横坐标 y1 int 灯位1圆心纵坐标 … … … x5 int 灯位5圆心横坐标 y5 int 灯位5圆心纵坐标 type tinyint 信号机的类型(0=出站,1=进站,2=调车) direct tinyint 朝向(0=右朝向,1=左朝向) circlenum tinyint 灯位数  下载: 导出CSV
下载: 导出CSV
表 3 道岔图像识别数据字段说明
字段 类型 备注 x1 int 道岔端点1横坐标 y1 int 道岔端点1纵坐标 x2 int 道岔端点2横坐标 y2 int 道岔端点2纵坐标 direct tinyint 朝向(1=撇形,-1=捺形) type tinyint 类型(0:单动道岔、1:双动道岔、2:交叉渡线) pos tinyint 道岔划分(0=上,1=下)
下载: 导出CSV
表 4 轨道电路图像识别数据字段说明
字段 类型 备注 x1 int 轨道电路包含的绝缘节横坐标 y1 int 轨道电路包含的绝缘节纵坐标 … … … track_t tinyint 所包含的道岔类型 … … … x10 int 包含的道岔2端点1的横坐标 y10 int 包含的道岔2端点1的纵坐标 x11 int 包含的道岔2端点2的横坐标 y11 int 包含的道岔2端点2的纵坐标 k2 tinyint 道岔2朝向(1=撇形,-1=捺形) p2 tinyint 道岔2划分区段(0=上,1=下) type tinyint 轨道电路的类型(0=无岔,1=有岔)
下载: 导出CSV
表 5 图像识别方法验证结果
设备类别 实际个数 正确识别个数 误识别个数 识别率 信号机 204 198 6 97% 绝缘节 223 207 16 93% 道岔 174 162 12 93% 轨道电路 240 203 37 85%
下载: 导出CSV
-
[1] 王 鹏. 铁路站场BIM技术应用研究[J]. 铁道标准设计,2019,63(11):27-29,34. [2] 王许生,蒲 浩,张 恬,等. 多耦合约束条件下铁路站场总体布置图自动生成方法研究[J]. 铁道科学与工程学报,2019,16(1):239-248. [3] 黄孝章,刘双双. 铁路站场平面图CAD系统中图形信息的自动识别和提取方法[J]. 交通与计算机,1998,16(2):53-57. [4] 张天祖,吕兴寿. 铁路站场平面图中主要元素的自动识别算法[J]. 兰州交通大学学报,2013,32(3):124-127,163. [5] 高兵德. CAD二次开发在铁路车站信号设计中的应用[J]. 铁道通信信号,2016,52(8):33-35. [6] 路正凤,王思明,吕国强,等. 基于PCA和随机Hough变换的调车信号灯检测[J]. 铁道标准设计,2014,58(3):130-134,140. [7] Li Q Y, Ren S W. A real-time visual inspection system for discrete surface defects of rail heads[J]. IEEE Transactions on Instrumentation and Measurement, 2012, 61(8): 2189-2199. DOI: 10.1109/TIM.2012.2184959
[8] 龙 芳,杨 扬. 基于数据挖掘的铁路车站信号平面布置图信息提取[J]. 铁路计算机应用,2022,31(12):1-7. DOI: 10.3969/j.issn.1005-8451.2022.12.01 [9] 汤 勃,孔建益,伍世虔. 机器视觉表面缺陷检测综述[J]. 中国图象图形学报,2017,22(12):1640-1663. DOI: 10.11834/jig.160623 [10] 李亚娣,黄海波,李相鹏,等. 基于Canny算子和Hough变换的夜间车道线检测[J]. 科学技术与工程,2016,16(31):234-237,242. DOI: 10.3969/j.issn.1671-1815.2016.31.045 [11] 王 敏,童水光,陈玉辉,等. 一种基于Hough变换的快速圆检测算法[J]. 机械工程与自动化,2018(1):152-154. DOI: 10.3969/j.issn.1672-6413.2018.01.065 [12] 王旭宸,卢欣辰,张恒胜,等. 一种基于平行坐标系的车道线检测算法[J]. 电子科技大学学报,2018,47(3):362-367. DOI: 10.3969/j.issn.1001-0548.2018.03.007










计量
- 文章访问数: 38
- HTML全文浏览量: 14
- PDF下载量: 11
