

Defect detection method for track fastener based on Transformer and local feature fusion
-
摘要:
为解决传统人工巡检轨道交通线路存在的效率低和有安全隐患等问题,提出一种基于Transformer与局部特征融合的轨道紧固件缺陷检测方法。构建轨道紧固件缺陷检测模型,将Transformer与局部特征模块融合,整合局部信息,进而提取轨道紧固件缺陷特征;同时,采用数据增强的方法对轨道紧固件缺陷样本进行数据扩增,扩充数据集,验证所建模型的检测效果。实验结果表明,相较于传统方法,文章提出的方法在识别轨道紧固件缺失和损坏两类缺陷方面的精度和平均准确率均有所提升,在不同的轨道线路实验环境下也表现出良好的检测效果。
-
关键词:
- 轨道线路 /
- 紧固件缺陷检测 /
- Transformer /
- 局部特征 /
- 数据增强
Abstract:To solve the problems of low efficiency and safety hazards in traditional manual inspection of rail transit lines, this paper proposed a rail fastener defect detection method based on Transformer and local feature fusion. The paper constructed a defect detection model for rail fasteners, integrated Transformer with local feature modules, integrated local information, and extracted defect features of rail fasteners, at the same time, used data augmentation methods to expand the dataset of rail fastener defect samples and verify the detection effect of the constructed model. The experimental results show that compared to traditional methods, the proposed method has improved accuracy and average accuracy in identifying two types of defects, namely missed and damaged track fasteners. It also shows good detection performance in different track experimental environments.
-
Keywords:
- track line /
- fastener defect detection /
- Transformer /
- local features /
- data enhancement
-
近年来,我国铁路营业里程不断增加,线路覆盖范围持续扩大,铁路成为促进各地区经济发展的重要交通运输工具[1]。铁路运输高度依赖轨道线路,轨道线路直接关系到列车行驶的安全和稳定,因此,有必要对轨道线路进行定期检测。
轨道紧固件作为轨道线路的重要组成部分,是保障轨道线路运营安全的重要一环。传统的轨道紧固件检查方式是人工巡检,虽然精度较高,但效率低下,且存在安全隐患[2]。为解决该类问题,主要有基于计算机视觉和图像处理技术结合的方法,以及利用卷积神经网络(CNN,Convolutional Neural Networks)的方法。前者对不同轨道紧固件的故障类型检测效果较差,普适性不强[3-4];后者计算量较大,且受限于传统感受野,在捕获全局特征表示方面有一定的局限性[5-6]。目前,基于自注意力机制的Transformer从自然语言处理领域到计算机视觉领域都取得了成功,成为继CNN和循环神经网络(RNN ,Recurrent Neural Network)之后又一个高效的特征提取器,其优点是能够直接捕捉到全局的联系,因为它直接把序列作两两比较(代价是计算量变为O(
n2 ));相比之下,RNN需要进行一步步递推才能捕捉到全局的联系,而CNN则需要通过层叠来扩大感受野 [7]。与RNN和CNN相比,Transformer的训练效率更加显著,因此,可使用Transformer来完成视觉任务,以降低结构的复杂性,探索可扩展性。常见的轨道紧固件缺陷有缺失和损坏两种情况。其中,轨道紧固件缺失包括钢轨扣压件缺失和螺栓缺失,钢轨扣压件缺失后会遗留轨下垫层,螺栓缺失后会遗留下螺孔,遗留物的背景信息复杂多样且会带来干扰,导致常规目标检测算法产生误检[8];轨道紧固件损坏指钢轨扣件损坏、凸出或凹陷,由于钢轨扣件整体型材相近,裂纹或裂缝难以被常规目标检测算法识别,导致发生漏检情况[9]。
综上,本文提出一种基于Transformer与局部特征融合的方法来识别轨道紧固件缺陷,建立轨道紧固件缺陷检测模型,通过卷积获取局部特征信息,结合Transformer提取全局特征,从而减少缺失误识别和损坏漏识别情况的发生。
1 轨道紧固件缺陷检测模型
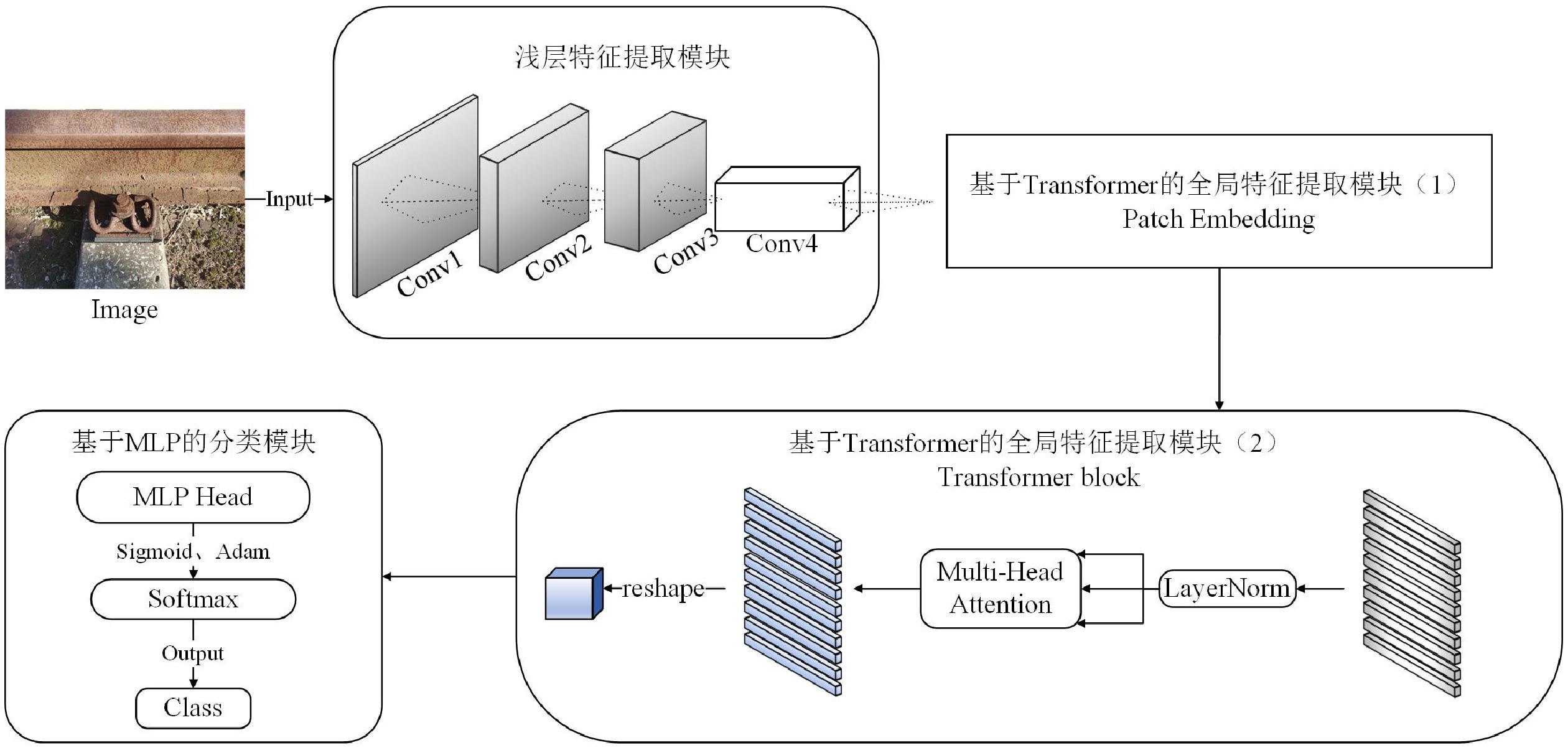
轨道紧固件缺陷检测模型架构如图1所示。该模型由基于CNN的浅层局部特征提取模块、基于Transformer的全局特征提取模块和基于多层感知机(MLP,Multilayer Perceptron)的分类模块组成。
1.1 基于CNN的浅层局部特征提取模块
由于本文使用的数据集规模较小,易出现过拟合的情况[10],故本模块由3个大小为3×3的卷积、1个
ReLU 激活函数及最大池化层组成。局部特征提取过程为:(1)利用卷积函数Conv提取图像的浅层特征,获取局部信息,为防止下采样过程中的图像信息丢失,设置步长为2,保留图片完整信息;(2)通过
ReLU 激活函数进行非线性增强;(3)利用MaxPool 的特征不变性对图像进行降维,压缩图像的空间冗余信息,避免了梯度爆炸和消失问题。将局部特征图输出结果g(x) 用公式表示为g(x)=MaxPool(ReLU(Conv(x))) (1) 1.2 基于Transformer的全局特征提取模块
1.2.1 Patch Embedding
ViT(Vision Transformer)是将Transformer应用在图像分类的模型[11],将输入图片分为多个大小相同的块,再将每个块投影为固定长度的向量输入Transformer,同时,在输入序列中加入Token,实现对图片的分类, Token对应的输出即为类别预测。当训练数据足够多时,ViT的表现可超过CNN,突破Transformer缺少归纳偏置的限制,在下游任务中可获得较好的迁移效果,但当训练数据集不够大时,其表现通常比同等大小的ResNets要差一些。
Patch Embedding过程中,ViT将输入图像切分成大小相同的块,然后线性映射为 Token向量作为输入,但这些Token无法直接适用于不同尺寸图像输入,当图像大小改变时,序列长度也随之改变,造成边缘信息丢失[12]。因此,本文将ViT模型中图像Token 化的Patch Embedding 过程替换为利用CNN提取底层特征的过程来进行 Patch Embedding,每一阶段的Token序列由上一阶段的Token序列卷积而来,这样进行卷积操作不会丢失图像的边缘信息。
具体操作为:(1)设定用卷积核大小为7×7的卷积对输入的特征图像块进行卷积操作,映射结果输入到新的Token map中;(2)利用全局平均池化将Token map展平,得到最终的Token序列;(3)通过 Transformer 的多头注意力机制(MHA ,Multi-Head Attention),获取对全局的理解。
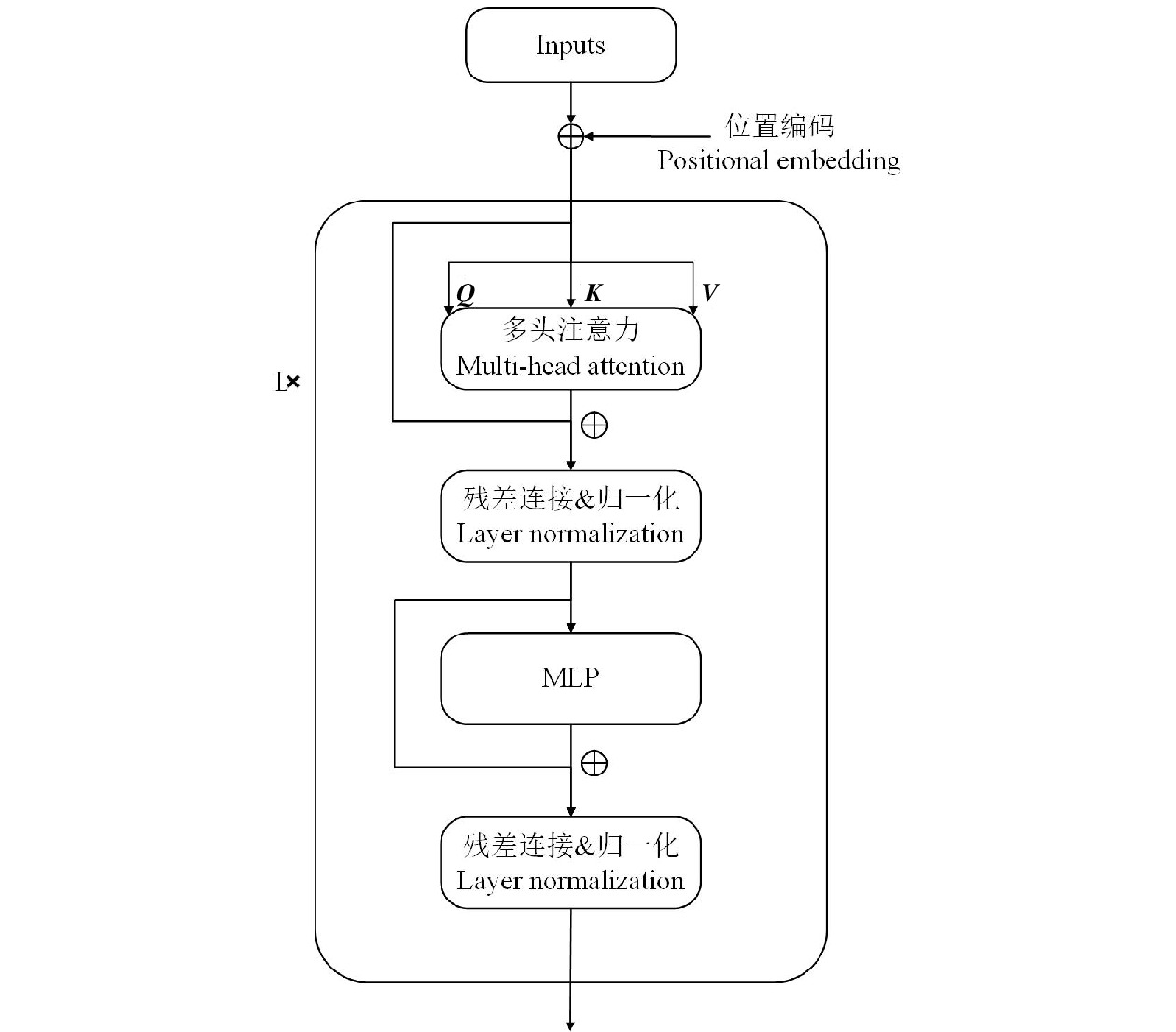
1.2.2 Transformer block
Transformer 利用注意力机制建立起序列间的远距离依赖关系,能够提高缺陷识别的准确率。Token序列进入到Transformer block中,为防止模型过拟合和输入数据特征分布的不断变化,通过Layer Norm实现归一化,使数据分布更加稳定,对Token序列进行标准化处理,保留不同特征间的大小关系。
图1中Transformer block的具体结构如图2所示,其功能主要由多头注意力(MHA,Multi-Head Attention)和MLP实现,层与层之间使用ResNet中的残差结构进行连接。每一层的MHA块和 MLP 块中的残余连接之前都使用层归一化处理[13]。
MHA是Transformer架构的核心。其计算过程为
\begin{array}{c}\boldsymbol{Q}=\boldsymbol{X}_{\boldsymbol{A}}\cdot\boldsymbol{W}_{\boldsymbol{Q}},\;\boldsymbol{K}=\boldsymbol{X}_{\boldsymbol{A}}\cdot\boldsymbol{W}_{\boldsymbol{K}},\;\boldsymbol{V}=\boldsymbol{X}_{\boldsymbol{A}}\cdot\boldsymbol{W}_{\boldsymbol{V}}\end{array} (2) Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V})=Softmax\left(\frac{\boldsymbol{QK^{\mathrm{T}}}}{\sqrt{d_k}}\right)\boldsymbol{V} (3) 式(2)、式(3)中,
\boldsymbol{X_A} 为上层输入的Token特征序列,矩阵\boldsymbol{W_Q} 、\boldsymbol{W_K} 、\boldsymbol{W_V} ∈R,\boldsymbol{Q} (query)、\boldsymbol{K} (key)、\boldsymbol{V} (value)分别为Token特征序列投影到不同的权重矩阵所对应的查询向量、键值向量和值向量;为得到不同特征位置的概率分数,将\boldsymbol{Q} 与\boldsymbol{K} 相乘,计算出不同输入矩阵间的注意力分数,同时引入比例因子\sqrt{{d}_{k}} 保障数据稳定性,{d}_{k} 为\boldsymbol{K} 向量的维度;引入Softmax函数将各特征位置上的注意力分数转为概率,再与V 矩阵相乘,得到加权后的特征图矩阵[14],Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) 表示单头注意力机制的输出结果。与单头注意力机制相比,MHA能够计算整张特征图的所有特征间的相关性,从而获得全局视野和充足的上下文信息,因此需将多个独立的自注意力头拼接成多头自注意力机制(MHSA,Multi-Head Self-Attention),计算过程为
\begin{array}{c}\boldsymbol{Q}_i=\boldsymbol{X}_{\boldsymbol{A}}\cdot\boldsymbol{W}_i^{\boldsymbol{Q}},\;\boldsymbol{K}_i=\boldsymbol{X}_{\boldsymbol{A}}\cdot\boldsymbol{W}_i^{\boldsymbol{K}},\;\boldsymbol{V}_i=\boldsymbol{X}_{\boldsymbol{A}}\cdot\boldsymbol{W}_i^{\boldsymbol{V}}\end{array} (4) \begin{array}{c}head_i=Attention\left(\boldsymbol{Q}_i,\boldsymbol{K}_i,\boldsymbol{V}_i\right)\end{array} (5) \begin{array}{l}MultiHead\left(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}\right)= \\ Concat\left(head_1,head_2,\cdots,head_h\right)\boldsymbol{W}^0\end{array} (6) 式(4)~式(6)中,
{{\boldsymbol{W}}}_{i}^{{\boldsymbol{Q}}} 、{{\boldsymbol{W}}}_{i}^{{\boldsymbol{K}}} 、{{\boldsymbol{W}}}_{i}^{{\boldsymbol{V}}} 分别为\boldsymbol{Q} 、{\boldsymbol{ K}} 和{\boldsymbol{V}} 线性变换时对应的权重矩阵[13];Concat 为拼接函数;{{\boldsymbol{W}}}^{0} 为计算头部时的投影矩阵;h 是自注意力头的数目,本文中设置h =6。通过输入的Token特征序列编码模块的反复堆叠,并不断将不同注意力层的信息合并,得到包含全局上下文依赖和聚合特征信息的图像特征。最后,通过reshape操作改变张量维度和形状,将包含特征信息的图像特征整合,输入到基于MLP的分类模块中。
1.3 基于MLP的分类模块
将图像特征输入到分类模块中,用于实现轨道紧固件缺陷的分类识别。在分类模块中搭建MLP模型,模型输出层采用Sigmoid函数,优化器采用Adam,通过对扩增数据集的训练与测试,得到缺陷所属类别,同时,引入Softmax函数,将各类别的注意力分数转为概率,最终得到缺陷所属类别及其概率。
2 实验与分析
2.1 数据集的制作
因轨道紧固件没有公开的数据集,所以本文收集了大量轨道紧固件近景图,通过修改图片亮度和对比度来模拟不同光照和不同天气情况下的轨道情况。由于异常紧固件在实际轨道上出现较少,因而通过样本扩增的策略对损坏、缺失的轨道紧固件图像采用平移、旋转、缩放、裁剪、镜像等方式来扩充训练集,最终得到1800张图像,并按照7∶2∶1的比例划分为训练集、验证集和测试集。使用LabelMe标注软件进行标注,标注类型分为正常紧固件(Normal)、损坏紧固件(Damage)、丢失紧固件(Lost),共3类。
2.2 实验准备
表 1 实验环境配置 型号 实验平台 Ubuntu18.04.6LTS 深度学习框架 PyTorch CPU Intel(R) Core(TM) i9-9900KF CPU @ 3.60GHz GPU NVIDIA TITAN RTX 编程语言 Python 3.8.17 表 2 模型参数设置参数 设置 图像大小 384 × 384 优化算法 Adam 动量系数 0.9 学习率 0.0001 权重衰减系数 0.01 batch size 32 注意力头数量 6 2.3 实验分析
2.3.1 模型对比实验
为验证本文轨道紧固件缺陷检测模型的缺陷检测能力,选择传统的CNN模型(ResNet-50)、经典的YOLO(You Only Look Once)模型(YOLOv3)和原始的Transformer模型(ViT)与本文模型进行对比实验。评价内容为Normal、Damage和Lost,共3类,采用的评价指标为准确率P、召回率R和平均准确率均值mAP。3者的计算公式为
P=\frac{TP}{TP+FP} (7) R=\frac{TP}{TP+FN} (8) mAP=\frac{\displaystyle \sum_{i=0}^{n}A{P}_{i}}{n} (9) 式(7)~式(9)中,
TP 表示检测正确的数量;FN 表示未检测出的数量;FP 表示误检测的数量;AP表示某一类别缺陷检测的平均准确率,即P和R积分的结果。i表示评价内容的类别,本文共有3种类别,故i =3。4种方法的检测结果对比如表3所示。由表3可知,相对于传统的CNN、YOLO及Transformer模型,本文方法的准确率、召回率及平均准确率均值均有所提升,准确率达到了90%以上,相较于ResNet-50、YOLOv3、ViT 模型分别提升了6.6%、3.6%、1.9%,mAP值相对于次好的ViT模型也提升了1.4%。实验结果表明,本文提出的方法在轨道紧固件缺陷检测效果上具有良好表现。
表 3 4种方法的检测结果对比方法 P R mAP ResNet-50 84.8% 90.3% 80.2% YOLOv3 87.8% 90.6% 81.9% ViT 89.5% 92.3% 84.7% 本文方法 91.4% 96.9% 86.1% 2.3.2 可视化分析
为验证模型在真实场景下的缺陷检测效果,从测试集中随机选取图片,使用本文的模型进行缺陷检测,并将输出结果可视化。4 种方法对轨道紧固件缺陷检测效果定性对比,如图3和图4所示。
图3展示了 4 种方法对轨道紧固件缺失的检测效果。 ResNet-50 模型对于近距离的紧固件检测效果较好, 但是对于远距离的轨道紧固件存在漏检;YOLOv3 模型与 ViT模型相对于ResNet-50 模型远距离检测的置信度更高,但对于部分遮挡下的轨道紧固件存在误检;本文方法的检测效果最佳, 无论轨道紧固件的距离远近,均能有效检测出缺失情况, 部分遮挡下的轨道紧固件也不存在误检测。
图4展示了 4 种方法对轨道紧固件损坏的检测效果。 ResNet-50 模型未能识别图中的紧固件损坏情况;YOLOv3 模型将轨道紧固件损坏误检为轨道紧固件缺失;ViT模型虽然识别到轨道紧固件损坏的情况,但检测的置信度偏低;本文方法不仅能够检测到轨道紧固件损坏的情况,同时检测的置信度值也较高。
由图3、图4可看出,本文提出的方法可在铁路轨道复杂环境下更准确地检测到轨道紧固件缺失及损坏的情况。
3 结束语
为提升轨道紧固件的巡检效率和准确率,本文提出一种基于Transformer与局部特征融合的轨道紧固件缺陷检测方法。构建轨道紧固件缺陷检测模型,在扩充数据集上进行的模型对比实验及可视化实验表明,该方法检测精确率达91.4%,平均准确率均值达86.1%,高于原始的 CNN和Transformer模型,证明本文方法在轨道紧固件缺陷检测方面的有效性,对轨道线路的安全检测具有参考意义。同时,由于轨道线路环境的不确定性,在检测过程中仍存在误检或漏检等现象,因此,需要进一步克服不确定环境对检测结果造成的影响,研究更高准确率的检测方法。
-
表 1 实验环境
配置 型号 实验平台 Ubuntu18.04.6LTS 深度学习框架 PyTorch CPU Intel(R) Core(TM) i9-9900KF CPU @ 3.60GHz GPU NVIDIA TITAN RTX 编程语言 Python 3.8.17  下载: 导出CSV
下载: 导出CSV
表 2 模型参数设置
参数 设置 图像大小 384 × 384 优化算法 Adam 动量系数 0.9 学习率 0.0001 权重衰减系数 0.01 batch size 32 注意力头数量 6
下载: 导出CSV
表 3 4种方法的检测结果对比
方法 P R mAP ResNet-50 84.8% 90.3% 80.2% YOLOv3 87.8% 90.6% 81.9% ViT 89.5% 92.3% 84.7% 本文方法 91.4% 96.9% 86.1%
下载: 导出CSV
-
[1] Liu S, Wang Q D, Luo Y P. A review of applications of visual inspection technology based on image processing in the railway industry[J]. Transportation Safety and Environment, 2019, 1(3): 185-204. DOI: 10.1093/tse/tdz007
[2] 卢艳东. 基于深度学习的轨道紧固件检测算法研究[D]. 兰州:兰州交通大学,2022. [3] 周 颖. 基于深度学习的轨道扣件缺陷检测方法研究[D]. 成都:四川大学,2021. [4] Liu J B, Huang Y P, Zou Q, et al. Learning visual similarity for inspecting defective railway fasteners[J]. IEEE Sensors Journal, 2019, 19(16): 6844-6857. DOI: 10.1109/JSEN.2019.2911015
[5] 马 茜. 基于图像识别技术的轨道交通缺陷检测研究[J]. 计算技术与自动化,2022,41(1):117-122. [6] Wang T G, Zhang Z J, Yang F F, et al. Automatic rail component detection based on AttnConv-net[J]. IEEE Sensors Journal, 2022, 22(3): 2379-2388. DOI: 10.1109/JSEN.2021.3132460
[7] 王悦林. 基于BERT的对AI理解语言方式的研究[J]. 科技视界,2019(5):88-89. [8] 温忠凯. 铁路钢轨扣件发展综述[J]. 商品与质量,2015(19):224-225. [9] 程智余,张金锋,孙丙宇. 基于Transformer和注意力机制的角钢塔螺栓缺陷检测模型[J]. 计算机系统应用,2023,32(4):248-254. [10] 唐东林,杨 洲,程 衡,等. 浅层卷积神经网络融合Transformer的金属缺陷图像识别方法[J]. 中国机械工程,2022,33(19):2298-2305,2316. [11] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems, 4 December, 2017, Long Beach, California, USA. Red Hook, USA: Curran Associates Inc. , 2017: 6000-6010.
[12] 刘 畅,莫海芳,马 春. 基于Transformer和CNN的真实场景下植物病害识别方法[J]. 现代计算机,2023,29(11):22-27. [13] Wang F, Jiang M Q, Qian C, et al. Residual attention network for image classification[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 21-26 July, 2017, Honolulu, HI, USA. New York, USA: IEEE, 2017: 6450-6458.
[14] 安小松,宋竹平,梁千月,等. 基于CNN-Transformer的视觉缺陷柑橘分选方法[J]. 华中农业大学学报,2022,41(4):158-169.
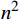
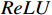
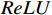
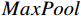
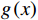
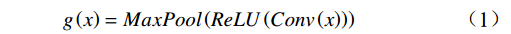
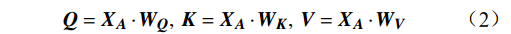
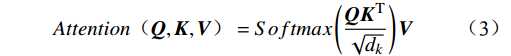
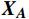
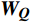
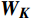
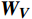
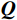
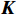
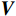
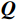
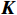
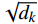
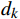
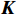
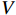
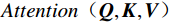
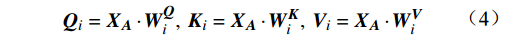
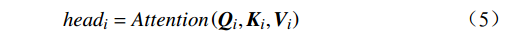
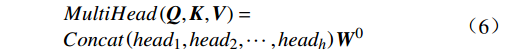
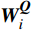
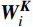
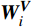
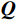
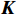
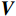
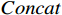
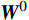
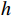
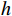



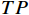
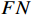
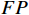
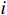


计量
- 文章访问数: 62
- HTML全文浏览量: 30
- PDF下载量: 41
