

Pedestrian reidentification model based on self-supervised part perception and its application in railway passenger stations
-
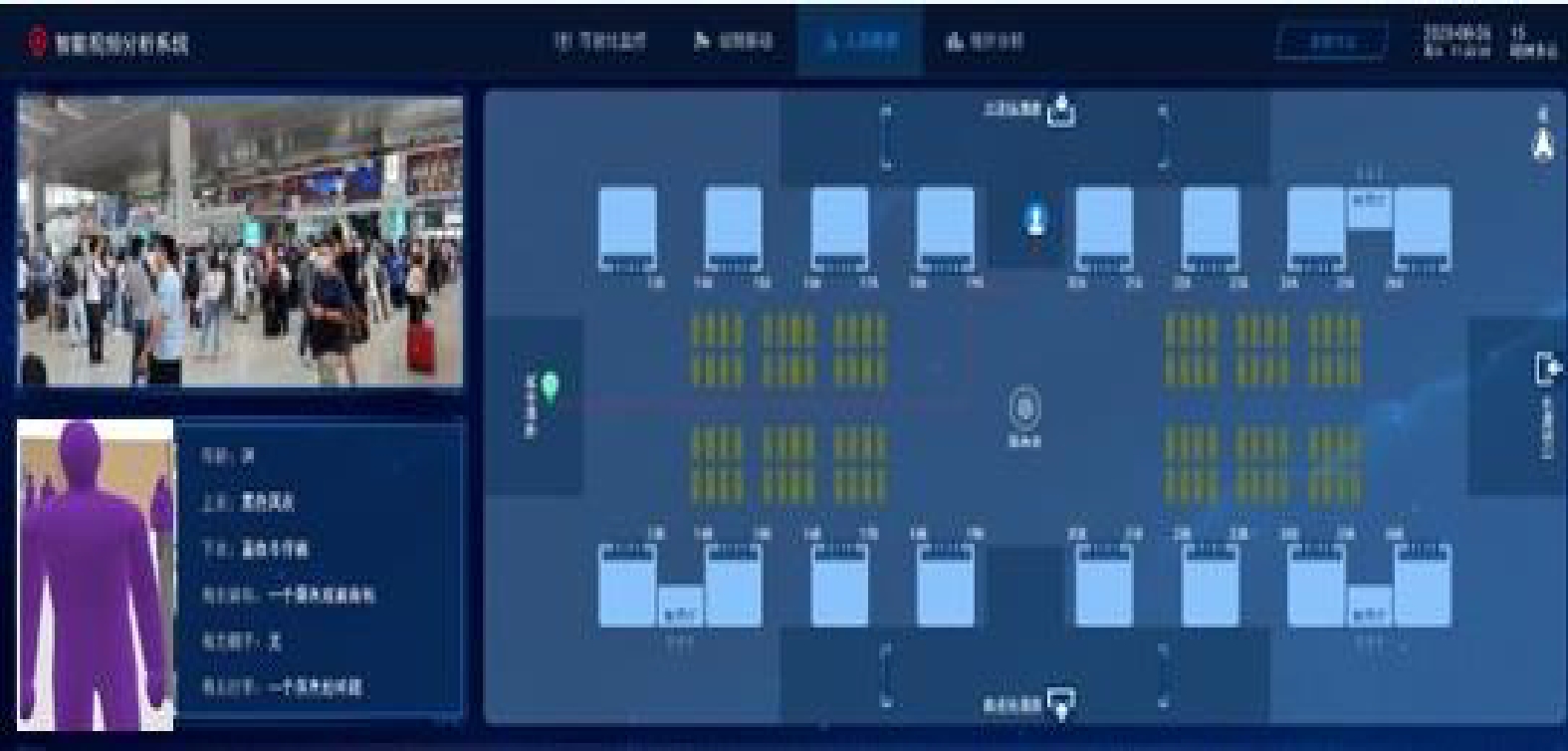
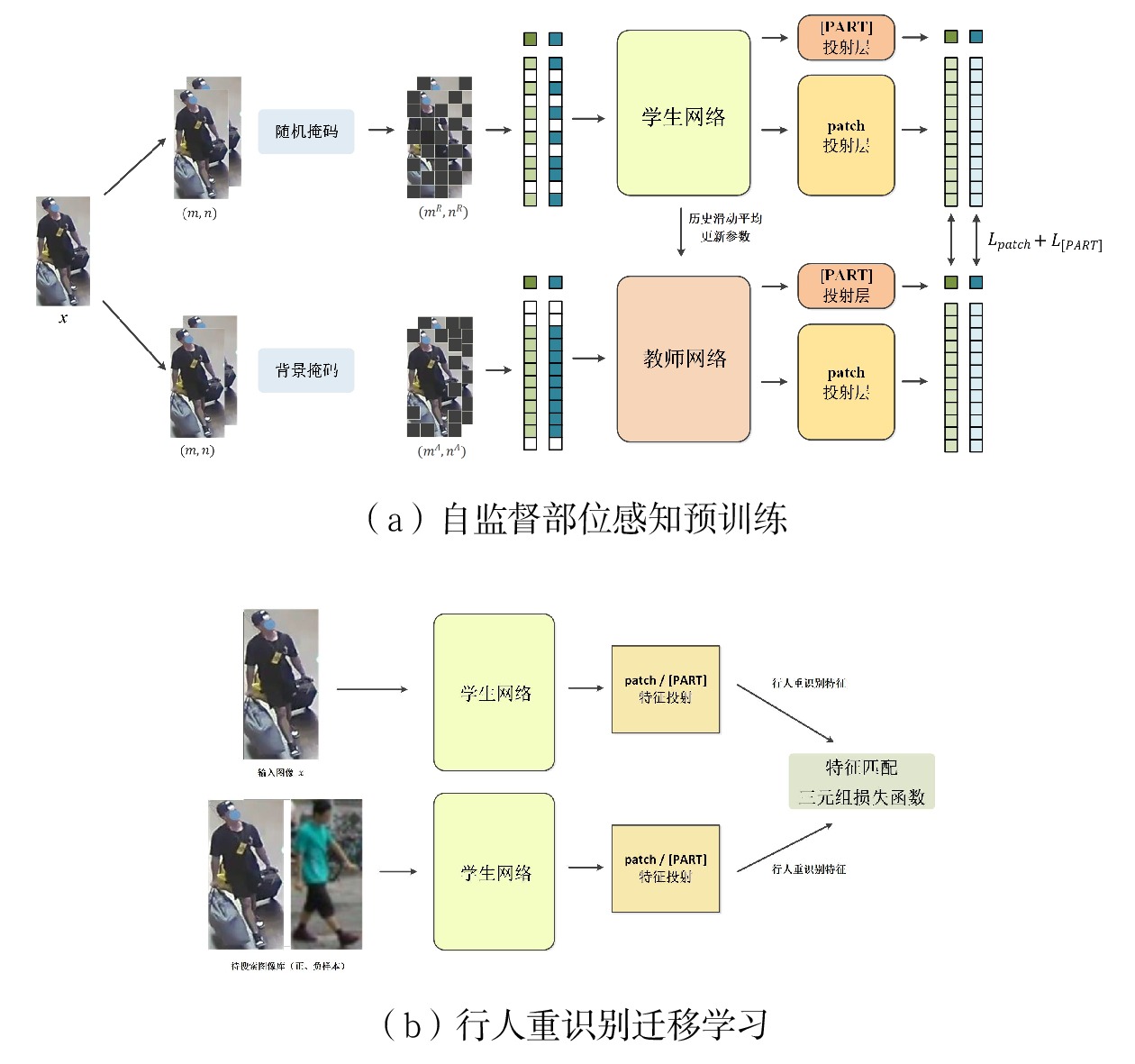
摘要: 铁路客运站环境复杂,客流密集,一旦发生涉及旅客安全、影响站区运营等重要事件时,客运工作人员亟需快速掌握相关旅客的站内轨迹。为此,设计了一种基于自监督部位感知的行人重识别模型,基于该模型可实现对铁路客运站重点旅客的实时跟踪。从自监督部位感知预训练和行人重识别迁移学习两个方面详细阐述了模型的架构。试验表明,该模型在各类尤其是存在严重遮挡的行人重识别数据集上的性能均超越了通用的行人重识别模型。在中国铁路兰州局集团有限公司白银南站的现场试用表明,该模型可有效跟踪重点旅客在铁路客运站内的行进轨迹,为客运相关工作提供技术支持。Abstract: The environment of railway passenger stations is complex and the passenger flow is dense. Once important events involving passenger safety and affecting station operations occur, passenger transport staff urgently need to quickly grasp the station trajectory of relevant passengers. Therefore, this paper designed a pedestrian reidentification model based on self-supervised part perception, and could implement real-time tracking of key passengers at railway passenger stations based on this model. The paper elaborated on the architecture of the model from two aspects: self-supervised part perception pre training and pedestrian re recognition transfer learning. Experiments have shown that the performance of this model surpasses the general pedestrian reidentification model on various types of pedestrian reidentification datasets, especially those with severe occlusion. The on-site trial at Baiyin South Station of China Railway Lanzhou Group Co. Ltd. shows that the model can effectively track the trajectory of key passengers inside the railway passenger station, and provide technical support for passenger related work.
-
-
表 1 不同模型的试验性能结果
方法 主干网络 Market1501 MSMT17 Occluded-Duke mAP R1 mAP R1 mAP R1 MGN Res50 87.5 95.1 63.7 85.1 39.0 46.8 TransReID ViT-B 87.4 94.7 63.6 82.5 44.8 52.4 TransReID-SSL ViT-S 90.9 96.0 66.1 84.6 50.6 59.5 TransReID-SSL Swin-T 92.5 96.3 66.8 86.0 55.7 61.1 本文模型 ViT-S 92.8 96.6 75.1 89.1 57.2 68.7 本文模型 ViT-B 93.4 96.8 75.3 89.7 60.3 68.5 本文模型 Swin-T 94.1 96.9 75.9 90.2 61.5 69.0  下载: 导出CSV
下载: 导出CSV
-
[1] 单仁光. 智能视频监控中行人检测与跟踪技术的研究与实现[D]. 杭州:浙江工业大学,2015. [2] Zheng L, Shen LY, Tian L, et al. Scalable person Re-identification: A benchmark[C]//2015 IEEE International Conference on Computer Vision (ICCV), 7-13 December, 2015, Santiago, Chile. New York, USA: IEEE, 2015: 1116-1124.
[3] Wei LH, Zhang SL, Gao W, et al. Person transfer GAN to bridge domain gap for person Re-Identification[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 18-23 June, 2018, Salt Lake City, UT, USA. New York, USA: IEEE, 2018: 79-88.
[4] He KM, Chen XL, Xie SN, et al. Masked autoencoders are scalable vision learners[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 18-24 June, 2022, New Orleans, LA, USA. New York, USA: IEEE, 2022: 15979-15988.
[5] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C]//Proceedings of the 9th International Conference on Learning Representations, 3-7 May, 2021. OpenReview. net, 2021.
[6] Fu DP, Chen DD, Bao JM, et al. Unsupervised pre-training for person re-identification[C]//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 20-25 June, 2021, Nashville, TN, USA. New York, USA: IEEE, 2021: 14745-14754.
[7] Miao JX, Wu Y, Liu P, et al. Pose-guided feature alignment for occluded person re-identification[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, 27 October, 2019-2 November, 2019, Seoul, Korea (South). New York, USA: IEEE, 2019: 542-551.
[8] Liu Z, Lin YT, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision, 10-17 October, 2021, Montreal, QC, Canada. New York, USA: IEEE, 2021: 9992-10002.
计量
- 文章访问数: 58
- HTML全文浏览量: 10
- PDF下载量: 11
