

Track region segmentation method based on RGBD fusion image and improved U-net
-
摘要: 传统的轨道分割方法无法满足列车运行时对轨道区域感知的实时性和准确性要求。文章研究基于RGBD融合图像及改进U-net的轨道区域分割方法,将RGB图像与深度图像进行融合,获得RGBD融合图像,将其输入到改进后的U-net中,建立轨道区域分割模型。经实验验证,与仅输入RGB图像的U-net模型相比,轨道区域分割模型的F1 值提升了约0.28,平均交并比提升了约0.1,像素准确率提升了0.0026,证明其对轨道区域分割的精确度更高,同时,验证了该模型的网络性能也得到了显著提升。
-
关键词:
- U-net /
- 轨道分割 /
- RGBD融合图像 /
- 深度图 /
- 卷积神经网络(CNN)
Abstract: Traditional track segmentation methods cannot meet the real-time and accurate requirements for perception of track areas during train operation. This paper studied a track region segmentation method based on RGBD fusion images and improved U-net. The RGB images were fused with depth images to obtain RGBD fusion images, which were input into the improved U-net to establish a track region segmentation model. After experimental verification, compared with the U-net model that only inputs RGB images, the F1 value of the track region segmentation model has been improved by about 0.28, the Mean Intersection over Union (MIoU) has been improved by about 0.1, and the Pixel Accuracy (PA) has been improved by 0.0026, proving its higher accuracy in track region segmentation. At the same time, it has been verified that the network performance of the model has also been significantly improved.-
Keywords:
- U-net /
- track segmentation /
- RGBD fusion image /
- depth image /
- Convolutional Neural Networks(CNN)
-
实时、准确地感知列车运行前方的轨道区域是保障列车安全运行的基础。高速铁路列车处于人工驾驶模式时,主要依靠列车驾驶员对前方运行环境进行判断。当列车在雨天、雾天、夜间等弱光线环境和复杂背景环境下运行时,驾驶员视线受限,很难保证列车的运行安全。因此,研究列车对轨道区域的智能感知是十分必要的。
随着视觉传感器的普及和深度学习技术的进步,众多研究人员在图像分割算法领域取得了显著成果。Shelhamer等人[1]提出了像素级语义分割的定义,并通过将分类网络改编为全卷积网络(FCN, Fully Convolutional Networks)解决分割问题;Ronneberger等人[2]提出了使用U-Net来解决小样本分割问题,用其“编码–解码”结构,通过串联操作,将浅层信息与深层信息融合,从而获得丰富的语义特征;Badrinarayanan等人[3]利用SegNet网络对位置信息丢失问题进行了改进,解决了由于多次池化造成的位置信息丢失问题。
目前,在图像分割任务中,由于光线、噪音等外部因素的影响,仅对RGB图像进行分析的方法存在局限性。铁路线路沿线环境复杂,由于光线变化大、障碍物遮挡等因素,导致基于RGB图像的轨道区域分割存在较大误差。
综上,本文研究基于RGBD融合图像及改进U-net的轨道区域分割方法,提升不同环境下的轨道区域分割精度。
1 相关技术
1.1 RGBD融合图像
深度(Depth)图像反映着物体的空间几何特征,可作为RGB图像的补充,以弥补光照条件不佳时RGB图像的细节损失。典型的轨道RGB图像和深度图像如图1所示。
RGB图像与深度图像的融合方式主要有前融合(Early Fusion)、后融合(Late Fusion)及中间融合(Intermediate Fusion)等3种[4]。其中,前融合也叫作特征级融合(Feature-Level Fusion),本文使用该种融合方式,将轨道RGB图像中的颜色及纹理信息与对应深度图像中的空间几何特征相结合,将其称之为RGBD融合图像。
1.2 U-Net
FCN是由卷积神经网络(CNN,Convolutional Neural Network)发展与延伸而来的。相较于CNN,FCN中输入的图像可为任意大小,且可确定图像每个像素的所属类别,实现了像素级的分类。
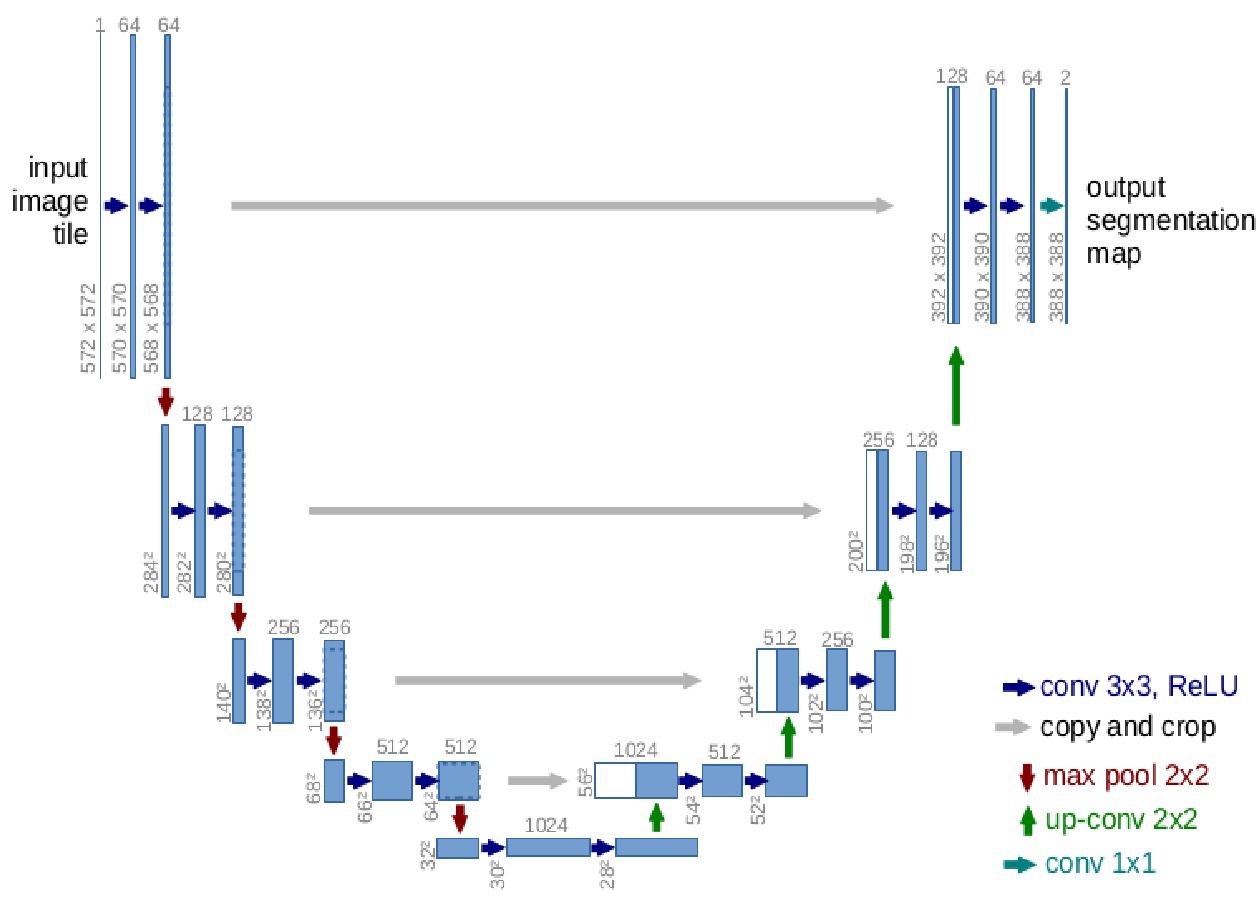
U-Net是一种基于FCN的“编码–解码”网络[2],它对FCN进行了改进,具有更好的识别效果,且仅需要更少的标注数据。U-Net结构如图2所示,其外形呈现一个U形,包括左边的编码部分即“下采样阶段”和右边的解码部分即“上采样阶段”。
U-Net的编码部分对输入的图像进行特征提取,获取抽象的语义特征。编码部分共有4个下采样模块,每个下采样模块都由2个卷积层及1个最大池化层组成,其中卷积层包括1个
3×3 的卷积核、BN(Batch Normalization)层及ReLU激活函数。U-Net的解码部分对提取的特征进行加强,解码部分包括4个上采样模块,每个上采样模块都由1个
2×2 转置卷积及2个3×3 的卷积层组成。经过4个上采样模块,最终得到一个融合所有特征的有效特征层。2 轨道区域分割模型
本文将RGBD融合图像输入到改进的U-net中,建立轨道区域分割模型,该模型采用改进的U-Net,基于输入的RGBD融合图像进行轨道区域分割。
2.1 改进的U-Net
图3为传感器采集到的不同类型的轨道图片。不同类型的轨道,其大小及表现形式都有所不同,即目标分割的对象是多尺度的。在对轨道上某像素点进行预测时,需要聚合其周围的像素信息,提高预测的准确性。
为让U-Net更加关注输入RGBD融合图像中的轨道区域信息,抑制深度图像背景区域产生的干扰,同时,保证不同尺度的输入图像都可检测到相同的关键点,本文对U-Net进行了改进,包括引入注意力机制模块和空洞空间金字塔池化模块。
2.1.1 注意力机制模块
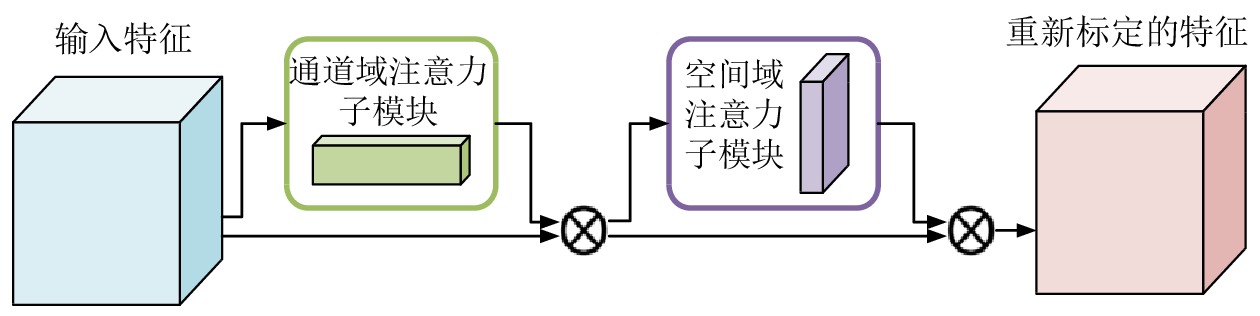
混合域注意力(HA ,Hybird-domain Attention)机制是软注意力机制的一个类别。HA机制的代表模块有注意力机制模块(CBAM,Convolutional Block Attention Module)和SA-Net[5-6]。CBMA包含2个注意力子模块:(1)通道域注意力子模块(CAM, Channel Attention Module),负责在通道域上处理输入的特征图张量;(2)空间域注意力子模块(SAM ,Spatial Attention Module),负责在空间域上处理CAM输出的特征图张量。CBAM将2个子模块串行连接,模块结构如图4所示。
2.1.2 空洞空间金字塔池化模块
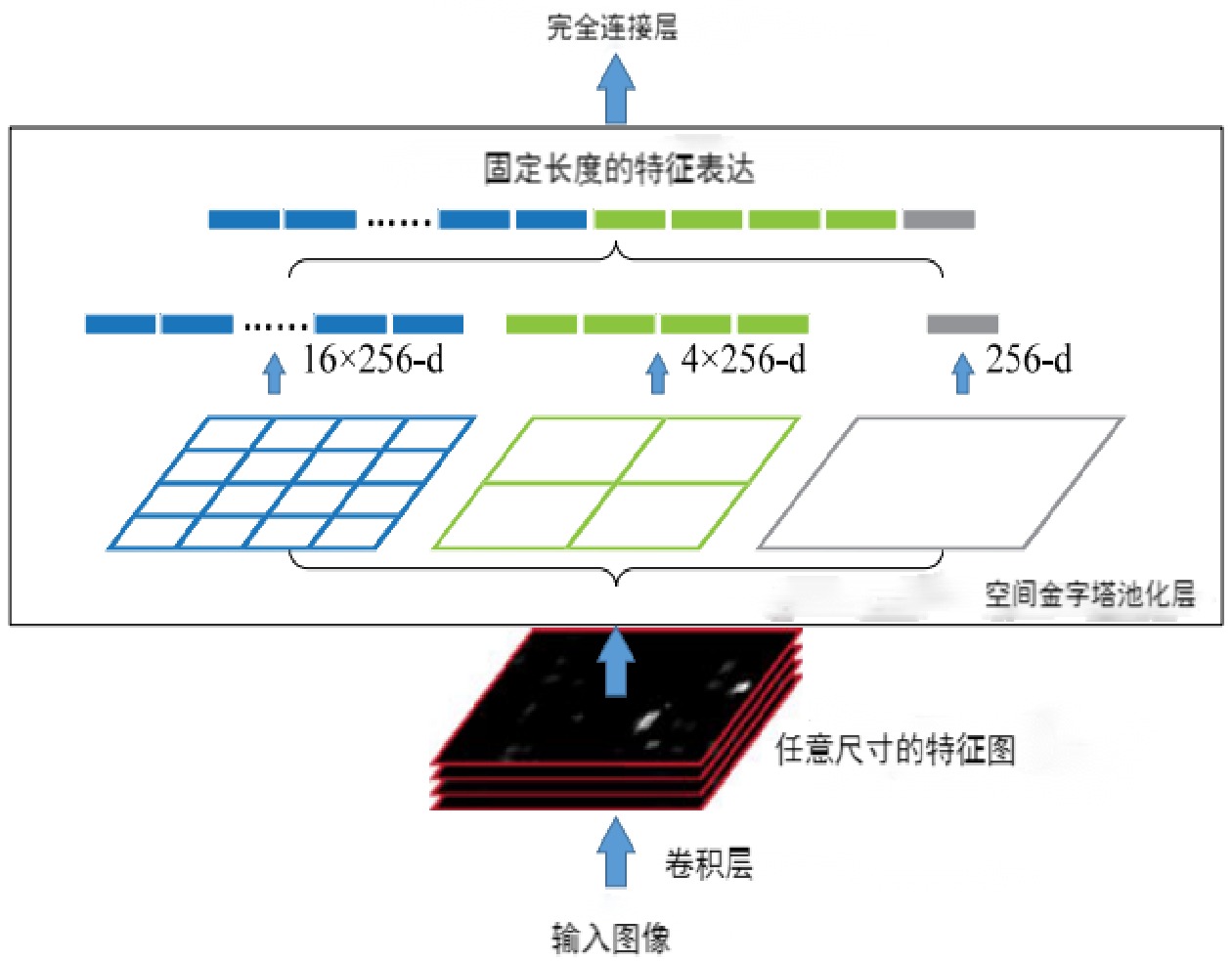
空间金字塔池化(SPP ,Spatial Pyramid Pooling)模块[7],将特征图划分为多个不同尺寸的网格,再在每个网格内都进行最大池化操作,从而让其后的全连接层得到固定大小的特征向量,且不限制输入图像的尺寸,SPP模块结构如图5所示,在U-Net中使用SPP模块可提高图像尺度不变性,在一定程度上避免网络训练过程中出现过拟合现象。
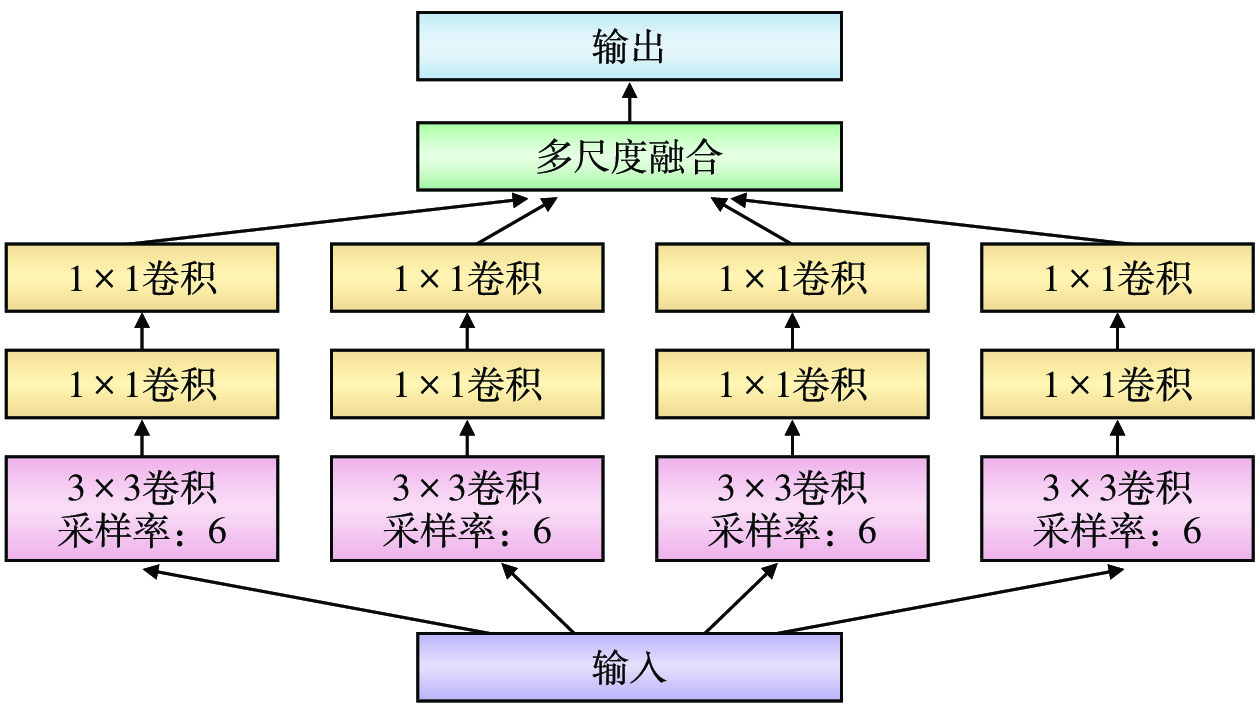
空洞卷积使用填0的方式扩大卷积核,得到不同尺度的卷积核,从而获得更大的感受野,且没有引入额外的训练参数。将空洞卷积应用于SPP模块中,即可得到空洞空间金字塔池化(ASPP ,Atrous Spatial Pyramid Pooling)模块[8]。ASPP模块同时具有SPP模块和空洞卷积的优点,可提取图像的多尺度信息,具有更强的鲁棒性。ASPP模块结构如图6所示。
2.2 轨道区域分割模型结构
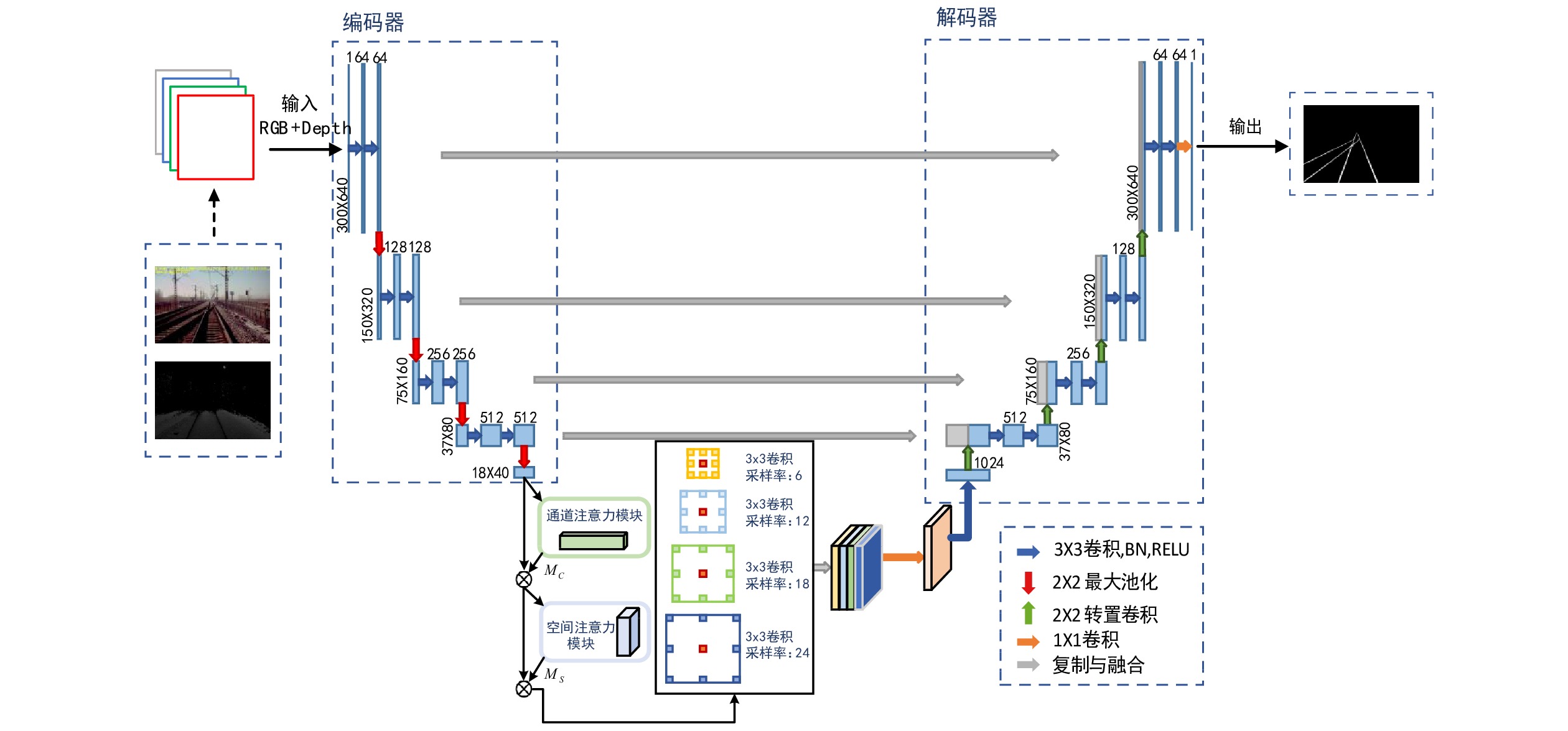
轨道区域分割模型将深度图像作为附加的空间信息,把原始RGB图像与对应的深度图像融合后获得的RGBD图像,以串联的方式并接为4通道,同时输入改进后的U-Net。轨道区域分割模型结构如图7所示。
轨道区域分割模型将最底层的普通卷积替换为CBAM与ASPP模块的串联组合,可加强卷积对局部特征的提取。利用全局信息,感知各通道特征图之间的相互依赖性,实现局部信息与全局信息的整合。并且,使用CBAM可有效节省计算资源。
3 实验与分析
3.1 图像数据采集与制作
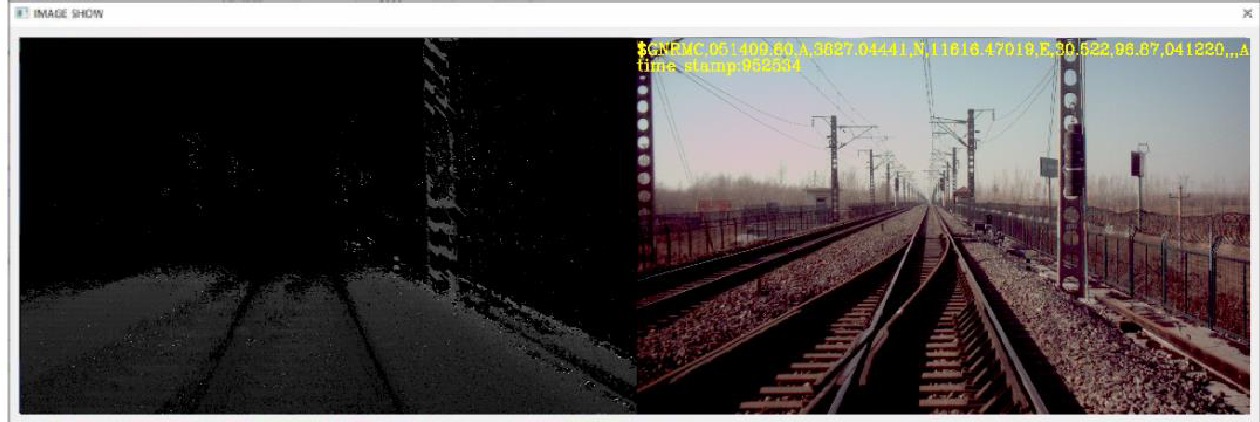
利用RS-LD1605M成像式激光雷达传感器,采集朔黄(朔州—黄骅)铁路某处的实际轨道线路数据。现场采集图像如图8所示,采集图像的右半部分为RGB图像,左半部分为对应的深度图像。
成像式激光雷达采集到的连续数据中包含夜晚和白天等不同线路场景图像,不同光照下轨道线路RGB图像如图9所示。
使用labelme图像标注工具对筛选出的图像进行标注。该数据集中共有440张RGB图像及对应的深度图像,包含不同光线条件下的轨道。使用labelme对RGB图像进行手工标注,随机抽选出40张RGB图像及对应的深度图像作为测试集,其他400张RGB图像及其对应的深度图像作为训练集。
3.2 参数设置及模型训练
表 1 硬件环境配置信息名称 配置信息 处理器CPU Intel(R) Core(TM) i7-11700 内存 32 GB 显卡 NVIDIA GTX 1080 显存 8 GB 表 2 软件环境配置信息名称 配置信息 操作系统 Windows10 编译器 Python 3.7 框架 Pytorch 1.10 运算平台 CUDA 11.4 使用随机初始化与BN层结合的方式对参数进行初始化。根据经验值,将学习率设置为0.001,并采用了0.9的动量加速收敛,神经网络每层都设置了BN层对数据进行正则化处理,缓解过拟合情况,并采用早停法来获取最优训练结果。如果训练过程中损失不变,学习率将会减小。整个训练过程经过70个周期。
3.3 评价指标
本文基于像素准确率(PA,Pixel Accuracy)、平均交并比(MIoU ,Mean Intersection over Union)及F1 值等3个指标对轨道区域分割模型进行评价。该模型为二分类模型,包含轨道和背景2个类别。其中,轨道为正样本,背景为负样本,用
Pij 表示属于 i 类的像素点被预测为 j 类的像素值,轨道区域分类结果混淆矩阵如表3所示。表 3 轨道区域分类结果混淆矩阵真实情况 预测结果 轨道 背景 轨道 P00 P01 背景 P10 P11 根据上述定义的参数,对轨道分割网络的评价指标进行定义。
(1)PA可表示为测试集中预测类别正确的像素值占总像素值的比例,公式为
EPA=P00+P11P00+P01+P10+P11 (2) (2)MIoU为每一类预测像素点与标注像素点的交集与并集的比值,求和再平均的结果,公式为
EMIoU=12(P00P00+P10+P01+P11P11+P01+P10) (3) (3)F1 值为精确率与召回率的调和均值,是用来衡量二分类模型精确度的一种指标,公式为
EF1=12(11precision+1recall)=12(P00P00+P10+P00P00+P01) (4) 式中,precision表示准确率;recall表示召回率。
3.4 实验结果分析
为验证轨道区域分割模型即本文模型的有效性,将其与其他4种模型的性能进行对比,其他4种模型分别为:(1)输入数据为RGB图像的原始U-Net区域分割模型M1;(2)输入数据为RGBD图像的原始U-Net区域分割模型M2;(3)输入数据为RGBD图像的添加CBAM的U-Net区域分割模型M3;(4)输入数据为RGBD图像的添加ASPP模块的U-Net区域分割模型M4。实验结果如表4所示。
表 4 实验结果模型 F1值 PA MIoU M1 0.2537 0.9813 0.6003 M2 0.3130 0.9817 0.6232 M3 0.5216 0.9837 0.6931 M4 0.5210 0.9836 0.6921 本文模型 0.5389 0.9839 0.7011 由表4可看出,与模型M1相比,模型M2的F1 值和MIoU均有显著提升,PA也有所提升。而模型M3、M4和本文模型则在此基础上进一步提高了网络分割精度。与模型M2相比,基于改进后的U-Net的模型,各项评价指标均有所提升,添加了两项改进模块的本文模型评价指标提升最为显著。与原始模型M1相比,本文模型F1值提升了0.28,MIoU提升了0.1,PA提升了0.0026。由评价指标可知,通过引入CBAM和ASPP模块,本文模型更加关注轨道特征,多尺度地提取轨道特征,从而提高了模型的整体性能。
不同模型的轨道区域分割结果如图10所示。为直观对比模型的分割效果,用白色表示轨道区域,背景部分不予显示。
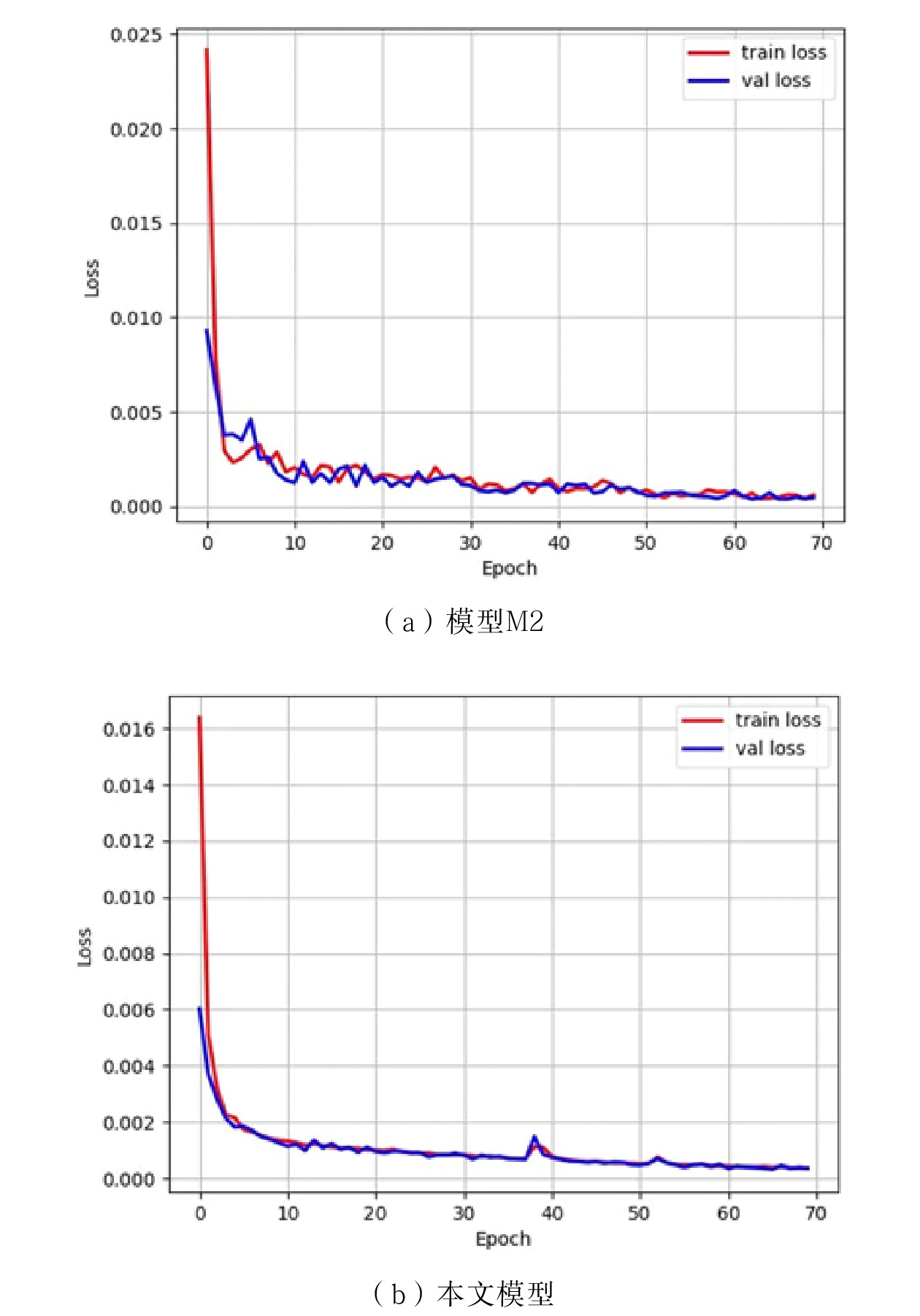
模型 M2与本文模型的损失函数曲线对比如图11所示。从图11(a)中可看出,模型M2经过70次迭代后,损失稳定在0.001左右,整个训练过程趋于收敛;由图11(b)可知,本文模型经过70次迭代后,损失稳定在0.0005左右。由二者的对比可看出,本文模型整体的损失比模型M2低,其网络性能表现更优。
4 结束语
本文设计并实现了一种基于RGBD融合图像及改进U-net的轨道区域分割模型。引入了CBAM和ASPP模块,从而提升轨道区域分割的精度。基于4种模型进行了对比实验,结果表明,本文设计的轨道区域分割模型显著提高了轨道区域分割精度。对比仅输入RGB图像的原始U-Net模型,本文模型 F1 值提升了约0.28,MIoU提升了约0.1,PA提升了0.0026,可有效提升轨道区域分割的准确性,具有参考价值。
-
表 4 实验结果
模型 F1值 PA MIoU M1 0.2537 0.9813 0.6003 M2 0.3130 0.9817 0.6232 M3 0.5216 0.9837 0.6931 M4 0.5210 0.9836 0.6921 本文模型 0.5389 0.9839 0.7011  下载: 导出CSV
下载: 导出CSV
-
[1] Shelhamer E, Long J, Darrell T. Fully convolutional networks for semantic segmentation [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 640-651. DOI: 10.1109/TPAMI.2016.2572683
[2] Ronneberger O, Fischer P, Brox T. U-Net: Convolutional networks for biomedical image segmentation[C]//18th International Conference on Medical Image Computing and Computer-Assisted Intervention, 5-9 October, 2015, Munich, Germany. Cham: Springer, 2015.
[3] Badrinarayanan V, Kendall A, Cipolla R. SegNet: a deep convolutional encoder-decoder architecture for image segmentation [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481-2495. DOI: 10.1109/TPAMI.2016.2644615
[4] 唐霖峰,张 浩,徐 涵,等. 基于深度学习的图像融合方法综述 [J]. 中国图象图形学报,2023,28(1):3-36. [5] Woo S, Park J, Lee J Y, et al. CBAM: convolutional block attention module[C]//15th European Conference on Computer Vision, 8-14 September, 2018, Munich, Germany. Cham: Springer, 2018.
[6] Yang Y B.SA-Net: Shuffle Attention for Deep Convolutional Neural Networks [EB/OL]. [2023-02-10]. http://arxiv.org/pdf/2102.00240.pdf.
[7] Chen L C, Papandreou G, Kokkinos I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs [J]. Computer Science, 2014(4): 357-361.
[8] Chen L C, Papandreou G, Kokkinos I, et al. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848. DOI: 10.1109/TPAMI.2017.2699184
-
期刊类型引用(3)
1. 吴志伟. 基于重要性评估的铁路货车终到站停留时间压缩策略研究. 铁道货运. 2024(09): 56-64+72 .  百度学术
百度学术
2. 吴志伟. 铁路货运站场车辆终到停留时间预测模型研究. 铁路计算机应用. 2024(09): 12-16 . 本站查看
3. 吴志伟,李楠,高达,王小朋,黄永亮. 基于铁路货运生产作业与管控平台的货运与车务作业综合协同研究. 铁道货运. 2023(08): 1-6+19 . 百度学术
其他类型引用(2)
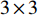
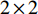
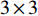


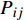
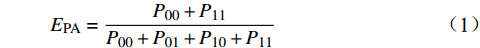
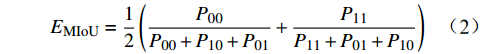
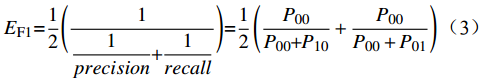


计量
- 文章访问数: 169
- HTML全文浏览量: 45
- PDF下载量: 48
- 被引次数: 5
