

Method for locating and detecting railway locomotive number in unrestricted scenarios
-
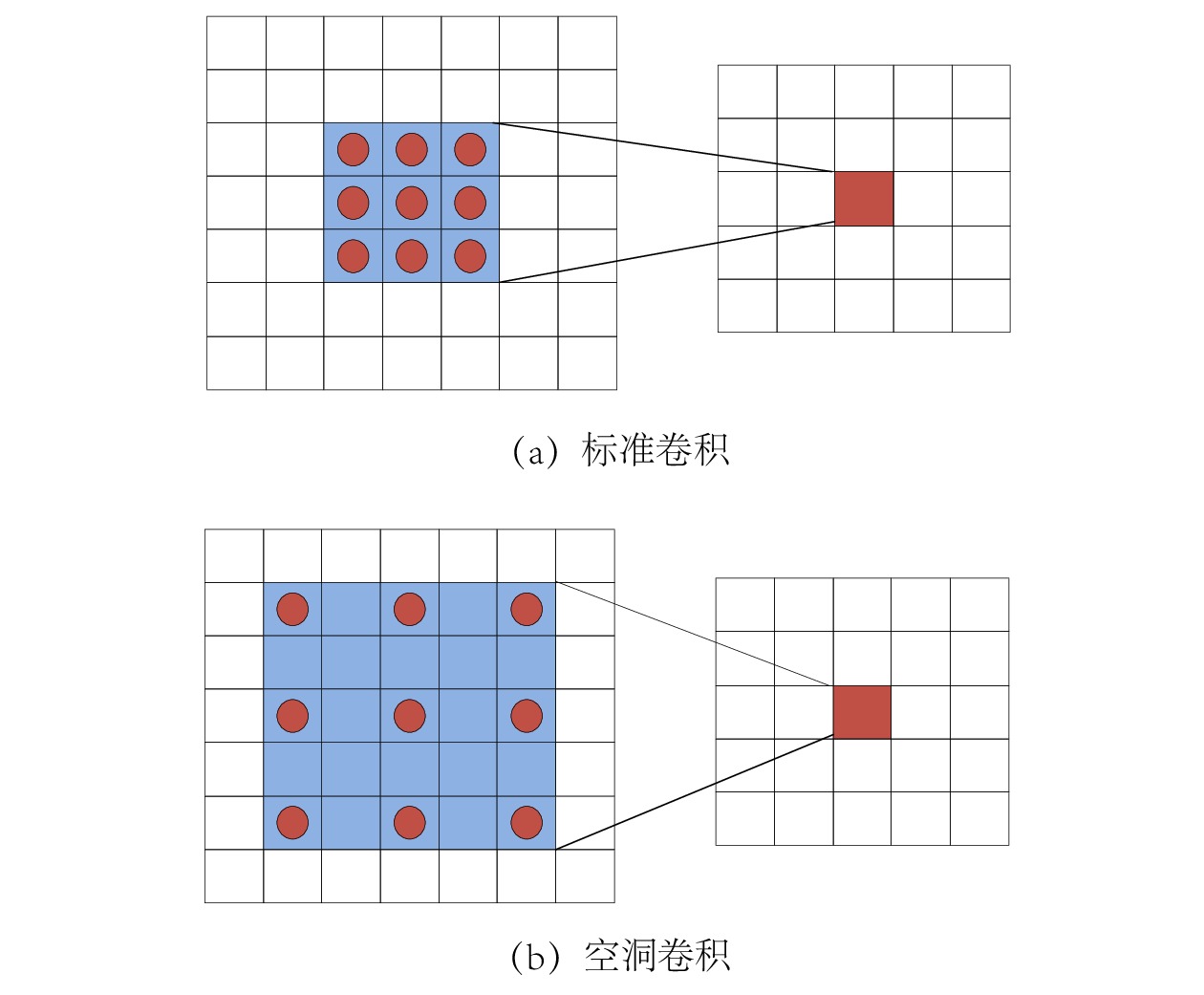
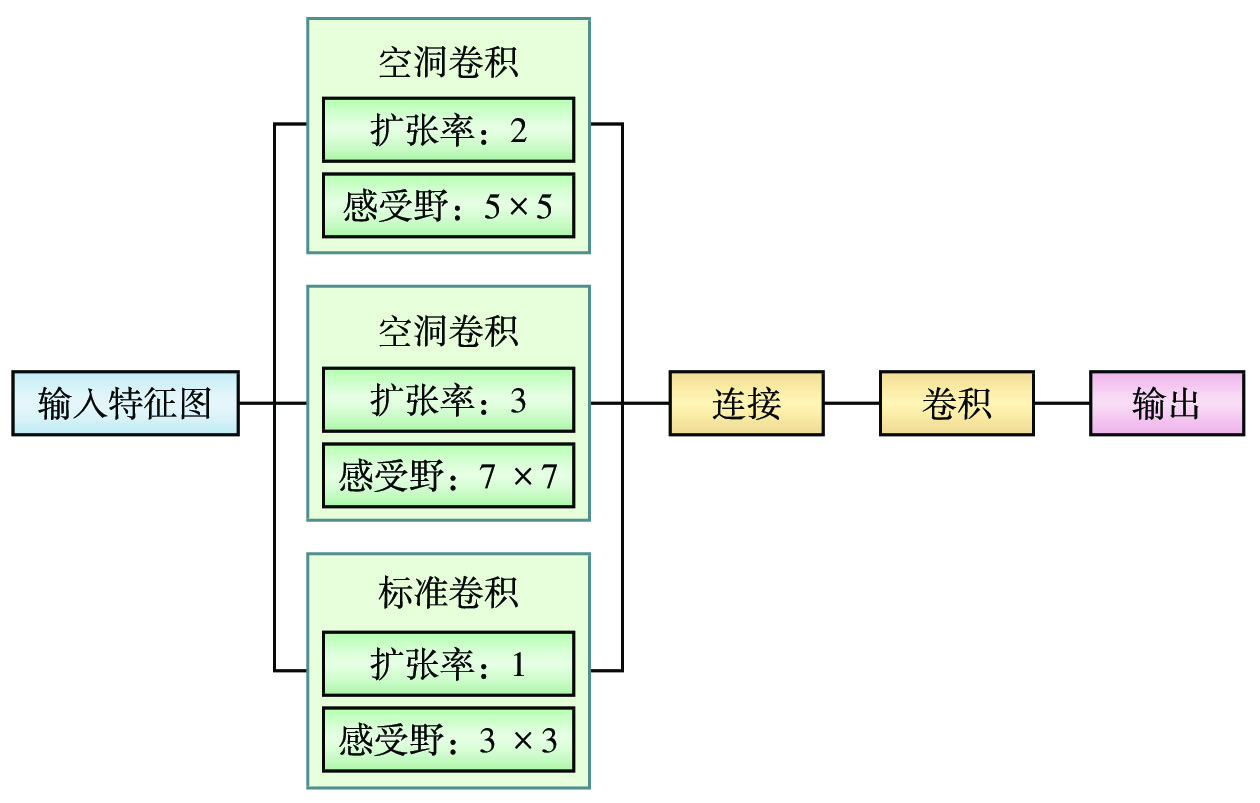
摘要: 针对传统铁路机车车号定位检测模型泛化性较低,不适用于多种检测应用场景等问题,提出一种适用于非限制场景、基于YOLO(You Only Look Once)v4-tiny模型的铁路机车车号定位检测方法。文章采用空洞卷积代替标准卷积,增大机车车号特征提取感受野,提升传统YOLOv4-tiny模型的检测精度;建立铁路机车车号数据集(RLND ,Railway Locomotive Number Dataset),用于模型训练,并对模型的检测效果进行验证。验证结果表明,该方法对铁路机车车号的定位检测精度为99.44%,检测速度为50 帧/s,能够应对非限制场景下的机车车号定位检测需求。
-
关键词:
- 图像识别 /
- 机车车号定位 /
- YOLOv4-tiny /
- 非限制场景 /
- 轻量化
Abstract: In response to the low generalization of traditional railway locomotive number localization and detection models and their inability to adapt to various detection application scenarios, this paper proposed a method for locating and detecting railway locomotive number in unrestricted scenarios based on YOLO (You Only Look Once) v4-tiny model. The paper used cavity convolution instead of standard convolution to increase the receptive field of locomotive number feature extraction, improve the detection accuracy of the traditional YOLOv4 tiny model, established the Railway Locomotive Number Data set (RLND) for model training, and verified the detection effect of the model. The validation results show that the positioning and detection accuracy of this method for railway locomotive numbers is 99.44%, with a detection speed of 50 frames/s. It can meet the needs of locomotive number positioning and detection in unrestricted scenarios. -
随着我国高速铁路的快速发展,铁路网规模日益扩大、结构日益复杂,跨线列车不断增加,使列车开行密度不断增大,这对铁路运输部门在出现自然灾害或者设备故障等非正常情况下的应急处置能力提出了很高的要求。应急方法和手段得当,能够有效地降低非正常事件对铁路运输的影响,减少列车晚点,尽快恢复列车运行;应急处理不当,不仅会扩大非正常事件的影响程度,还可能会引发其他事故,造成更大负面影响。
国内外许多专家学者对列车运行调整领域进行了广泛而深入的研究。文献[1]基于替代图对列车运行调整问题进行建模;文献[2]针对单线铁路的列车运行调整问题提出了遗传算法和人工神经网络;文献[3]以所有列车总延误时间最少为目标,构建线性规划模型,通过对偶算法求得模型的解;文献[4]考虑突发事件持续时间的不确定性,以保证所有列车晚点时间之和的平均值最小为目标函数,构建了有路径选择约束的整数规划模型和无路径选择约束的整数规划模型;文献[5]以列车总晚点时间最小化为目标函数,并考虑了列车区间停站和返回车站停站的问题,构建出混合整数规划模型;文献[6]采用离散事件动态系统理论,将列车占用区间或车站作为离散事件,将由各种技术设备、信联闭设备组成的列车运行调整系统作为离散时间动态系统,建立了离散事件动态系统驱动的状态空间调整模型,并通过网络分层并行算法对问题进行求解;文献[7]通过蚁群算法,利用蚂蚁根据启发函数得到的各点选择概率,搜索图定节点的调整时刻;文献[8]通过遗传模拟退火算法对列车运行调整问题进行求解。
目前,高速铁路应急调整方面主要存在以下几方面问题:调整时间长;应急信息的收集、感知和利用不充分;考虑因素不全面;决策缺乏计算机技术支持等。
虽然关于列车运行调整的理论模型和方法较多,但在应用于实际列车调整过程中时,这些模型和方法仍有许多局限性。在正常调整过程中,调度员仍然发挥着举足轻重的作用,但鉴于应急调整中应急处理时间短、应急处置压力大等因素,调度员难以快速对列车运行图进行科学合理、全面有效的调整。因此,本文基于上述研究,结合高速铁路运行组织现状,考虑实际列车运行调整的原则和方法,研究面向复杂高速铁路网的列车运行计划应急调整方案。设计高速铁路列车应急调整流程,以及非正常事件下基于“一事一图”的高速铁路列车应急调整系统,以提高铁路应急处置能力。
1 高速铁路列车应急调整流程设计
当设备出现故障、发生自然灾害、天气不良等非正常事件造成高速铁路旅客列车大面积晚点时,铁路调度部门需要及时启动应急响应。由相关部门收集整理各类信息,调度员基于相关信息表达调整意图,借助计算机技术实现快速调整。具体应急调整业务流程如图1所示。
如图1 所示,调度部门基于相关信息确定调整方案,调用高速铁路列车应急调整系统(简称:应急调整系统)进行调整。应急调整系统根据调度员意图和相应规则,自动生成新的列车运行图。当调度员对调整结果不满意时或有新的意图表达时,可以重新进行调整。当调度员对调整结果满意时,调整后的列车运行图将提供给应急领导小组决策,若决策不通过,则可重新进行调整;若决策通过后,将由调度员按照调整后的列车运行图,发布调度命令,组织恢复列车运行秩序。在调度执行过程中,如涉及跨铁路局集团公司旅客列车停运、加开临客、启动热备车底、迂回径路运行等情况时,调度员需要及时向中国国家铁路集团有限公司(简称:国铁集团)请求调度命令。
2 系统架构
本文基于高速铁路列车应急调整流程制定非正常事件下的列车运行图,即“一事一图”运行图,设计应急调整系统架构。
应急调整是保障应急指挥安全、提高应急处置效率的核心,与目前的应急调整相比,应急调整系统可以全面收集信息,包括列车运行数据和运输组织数据,同时,支持根据调度员意图生成相应的优化方案,实现不同调整方案的对比分析。由于借助计算机系统,使应急调整系统的处理时间显著减少,可实现快速调整、快速决策,从而提高铁路调度应急处置能力和效率。
应急调整系统采用模块化设计,主要分为4个模块,其中,数据管理模块、列车调度员人机界面模块和计划下达模块可使用现有系统,列车运行调整求解引擎是独立的模块,现有各模块通过开放接口和数据实现快速集成。其架构如图2所示。
(1)数据管理模块主要实现路网基础数据、应急设备数据、列车动力学数据、客运数据、动车组交路数据、计划数据和运行图数据等的收集和整理;
(2)列车调度员人机界面模块主要实现调度员意图表达、调整计划显示、优化方案对比分析及计划下达等功能,在应急情况下,可以快速生成调整方案;
(3)计划下达模块主要实现将调整计划下达至车站和调度集中系统;
(4)列车运行调整求解引擎模块是应急调整系统的核心,它接受数据输入和调度员意图表达,在安全卡控的原则下,基于调整规则实现调度员的意图,并将调整结果和调整说明返回给列车调度员人机界面模块。
应急调整系统实现了数据管理与方案生成、计划执行之间的闭环管理;在安全方面,实现了计算机和人工双重卡控,提高了应急调整系统的效率和安全性,保证了调整方案的可行性。与现有系统相比,模块化的设计在系统集成、数据管理等方面均有很大优势。
3 系统功能
当突发事件导致高速铁路旅客列车大面积晚点时,铁路部门需要快速响应,基于应急指挥中心成立列车运行调整应急小组,根据列车晚点、车底接续、乘务安排等编制“一事一图”行车组织调整方案。本文设计的应急调整系统主要支持以下功能。
3.1 设置封锁
通过数据管理模块实现铁路网基础数据、应急设备数据(热备车、热备乘务组等)、列车运行数据、扰动数据等的收集和整理;调度员根据系统所收集的信息,结合现场处置情况,研判故障处置时间,设置封锁或限速;随后调用列车运行调整求解引擎,实现应急调整。
3.2 自动生成“一事一图”运行图
列车运行调整求解引擎在安全卡控的原则下,基于调度员意图和调整规则,实现非正常事件下“一事一图”的行车组织调整方案。应急调整系统在生成“一事一图” 行车组织调整方案时,将根据预先定义的调整规则或措施实现,具体调整规则如下:(1)“由近及远”扣停列车;(2)股道的精细化使用;(3)改变列车运行时间;(4)减少车站组织变化;(5)保证动车组接续关系。
3.3 调整计划的修改和下达
在生成调整计划后,调度员可以通过人机界面实现对调整方案的更改、再优化和下达等。当调度员制定了新的调整意图时,可以通过人机界面基于新的调整意图重新优化。同时,调度员对多个意图下的调整方案进行对比分析,选择合适的方案,通过计划下达模块下达给车站和调度集中系统,指导车站客运组织工作和列车运行工作。
4 关键技术
4.1 时空网络模型
近年来,基于时空网络的建模方法广泛应用于解决列车运行图编制问题,而铁路列车运行调整问题可以看作是列车运行图的再编制过程,其本质是列车在时间和空间上的资源分配问题,因此可将该问题抽象为时空网络模型。网络包含3个要素,分别是网络节点、网络弧和列车时空路径。网络节点用于表示列车在该时间点的空间位置,即列车状态,对应的有虚拟起点、虚拟终点、列车到达节点和列车出发节点。网络弧由节点的连线组成,表示列车的运行状态,包括虚拟起始弧、区间运行弧、车站停站(通过)弧、以及虚拟终止弧。节点和弧共同组成了列车时空路径[9]。其时空网络示意如图3所示。
图3刻画了3列车的时空路径,起终点为网络中的虚拟节点,不同颜色和线型对应不同的弧,由节点和弧共同构成了列车时空路径。
4.2 拉格朗日松弛算法
基于时空网络构建整数规划模型,描述列车运行调整问题。模型求解时采用拉格朗日松弛算法,其核心思想是将模型中复杂的约束松弛,并将其作为惩罚项加入到目标函数中,从而转化为拉格朗日对偶问题,降低模型求解难度的同时提高求解效率[10]。
5 实例分析
以京沪(北京—上海)高速铁路北京局管内线路为例,如图4所示。北京南站高速场共有11条股道供京沪高铁使用,同时作为京沪高铁的尽头站,其上下行股道可混用;德州东站为北京局集团有限公司和济南局集团有限公司的分界口车站,有3条上行到发线,2条下行到发线;京津(北京—天津)线路所接入天津西—北京南方向的列车,津沪(天津—上海)线路所接入天津西—上海虹桥方向的列车。本文以某日接触网挂网引发沧州西—天津南上行区间封锁为例,封锁时间为08:00—10:30,如图4所示。通过应急调整系统得到的调整结果如图5所示。
由图5可知,在封锁结束4 h后,上行列车晚点时间和数量都显著减少,到14:20,上行列车晚点基本消除,与实际调整结果相符。
6 结束语
应急调整系统作为应急处置工作的重要工具,辅助调度员安全、快速、科学、合理制定应急列车运行图,对恢复列车运行秩序、提高铁路系统的应急处置能力至关重要。本文基于列车应急调整流程,设计了应急场景下的调度调整系统,以京沪高铁某日接触网挂网导致线路中断为例,进行了分析。本系统已部署到中国铁路北京局集团有限公司应急指挥中心,在应用中效果良好,提高了铁路应急处置能力,为铁路调度应急指挥提供了辅助决策支持。
-
[1] 中国国家铁路集团有限公司.中国国家铁路集团有限公司2021年统计公报[N]. 人民铁道, 2022-03-01(002). [2] 马巧梅,王明俊,梁昊然. 复杂场景下基于改进YOLOv3的车牌定位检测算法 [J]. 计算机工程与应用,2021,57(7):198-208. DOI: 10.3778/j.issn.1002-8331.2008-0137 [3] Felzenszwalb P F, Girshick R B, McAllester D, et al. Object detection with discriminatively trained part-based models [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9): 1627-1645. DOI: 10.1109/TPAMI.2009.167
[4] Girshick R. Fast R-CNN[C]//Proceedings of the IEEE International Conference on Computer Vision, 07-13 December, 2015, Santiago, Chile. New York, USA: IEEE, 2015: 1440-1448.
[5] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. DOI: 10.1109/TPAMI.2016.2577031
[6] He K M, Gkioxari G, Dollár P, et al. Mask R-CNN[C]//IEEE International Conference on Computer Vision (ICCV), 22-29 October, 2017, Venice, Italy. New York, USA: IEEE, 2017: 2980-2988.
[7] Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection[C]//Proceedings of International Conference on Computer Vision and Pattern Recognition, 27-30 June, 2016, Las Vegas, NV, USA. New York, USA: IEEE, 2016: 779-788.
[8] Redmon J, Farhadi A. YOLO9000: better, faster, stronger[C]//Proceedings of IEEE Conference on Computer Vision & Pattern Recognition, 21-26 July, 2017, Honolulu, HI, USA. New York, USA: IEEE, 2017: 6517-6525.
[9] Redmon J, Farhadi A. YOLOv3: an incremental improvement [J]. arXiv e-prints, 2018. DOI: 10.48550/arXiv.1804.02767
[10] Liu W, Anguelov D, Erhan D, et al. SSD: single shot MultiBox detector[C]//Proceedings of the 14th European Conference on Computer Vision, 11-14 October, 2016, Amsterdam, The Netherlands. Cham: Springer, 2016: 21-37.
[11] Jamtsho Y, Riyamongkol P, Waranusast R. Real-time Bhutanese license plate localization using YOLO [J]. ICT Express, 2020, 6(2): 121-124. DOI: 10.1016/j.icte.2019.11.001
[12] 赵 伟,鞠美玉,邓 艳. 复杂环境下的车牌定位方法 [J]. 计算机工程与设计,2016,37(4):982-987. DOI: 10.16208/j.issn1000-7024.2016.04.027 [13] 艾 曼. 基于Faster-RCNN的车牌检测 [J]. 计算机与数字工程,2020,48(1):174-177. DOI: 10.3969/j.issn.1672-9722.2020.01.033 [14] Jiang Z , Zhao L , Li S , et al. Real-time object detection method based on improved YOLOv4-tiny [J]. arXiv e-prints, 2020. DOI: 10.48550/arXiv.2011.04244
[15] Yu F, Koltun V, Funkhouser T. Dilated residual networks[C]//IEEE Conference on Computer Vision and Pattern Recognition, 21-26 July, 2017, Honolulu, HI, USA. New York, USA: IEEE, 2017: 636-644.
-
期刊类型引用(1)
1. 杨文成,霍磊,郑玢,赵鹏,乔俊飞,张小虎. 基于IFC标准和数据库技术的铁路站场自动化BIM建模方法. 铁道标准设计. 2023(10): 78-85 .  百度学术
百度学术
其他类型引用(0)

 下载:
下载:








计量
- 文章访问数: 113
- HTML全文浏览量: 28
- PDF下载量: 16
- 被引次数: 1
