

Research and development of risk prediction, prevention and control system for railway data center based on massive operation and maintenance data
-
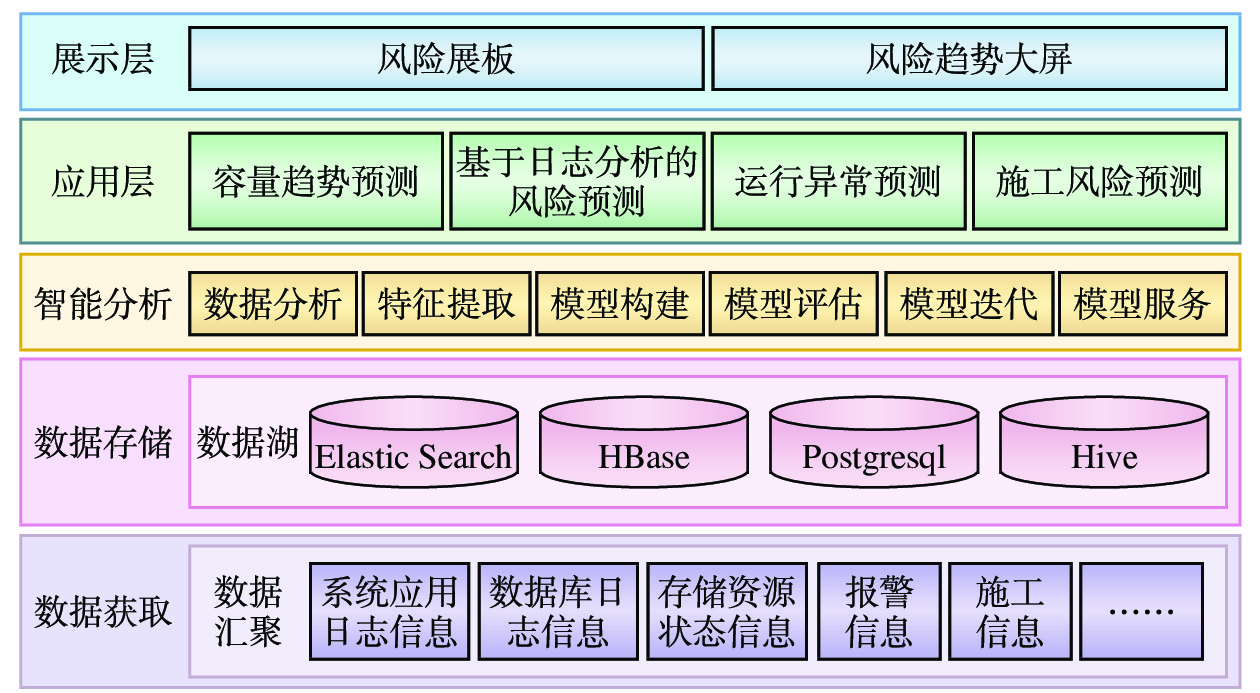
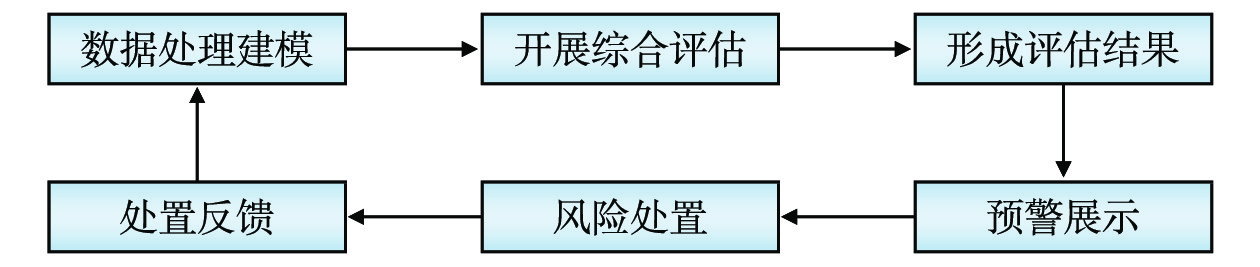
摘要: 基于海量运维数据的风险预测和风险防控是铁路数据中心实现智能运维的基础性工作。围绕铁路数据中心智能运维需求,研究智能分析方法,依托铁路数据服务平台的大数据存储和数据共享服务能力,使用平台提供的数据预处理及模型训练、模型部署等工具,建立容量趋势预测、基于日志分析的风险预测、运行异常预测、施工风险预测等不同运维场景风险预测模型,完成模型训练、调优和测试,最后将通过实验验证的模型进行发布和上线更新。建立基于海量运维数据的铁路数据中心风险预测与防控系统,可以通过运维经验积累来改进评估指标和预测模型,提高风险预测的准确性及风险处置的有效性,帮助运维人员快速聚焦主要问题,有利于保障铁路数据中心长期安全稳定运行,夯实铁路运输生产安全的基础。Abstract: Risk prediction, prevention and control based on massive operation and maintenance data is the basic task of the railway data center to realize artificial-intelligence-based operation and maintenance. Based on the requirements of intelligent operation and maintenance of the railway data center, four intelligent operation and maintenance data analysis methods are studied. Relying on the big data storage and data sharing service capability of railway data service platform, using data analysis, model training, model deployment and other utilities provided by the platform, risk prediction models of several operation and maintenance scenarios such as capacity trend prediction, log analysis-based risk prediction, operation anomaly prediction and construction risk prediction are established, and model training, tuning and testing are also completed. Finally, the models verified via test are released and updated online. The establishment of the risk prediction, prevention and control system for railway data center based on massive operation and maintenance data can improve the evaluation index and prediction model through the accumulation of experiences in operation and maintenance, improve the accuracy of risk prediction and the effectiveness of risk disposal, and help operation and maintenance personnel quickly focus on major problems, thus guaranteeing the long-term safe and stable operation of the railway data center, and consolidating the foundation of railway transportation production safety.
-
随着我国高速铁路的快速发展,铁路网规模日益扩大、结构日益复杂,跨线列车不断增加,使列车开行密度不断增大,这对铁路运输部门在出现自然灾害或者设备故障等非正常情况下的应急处置能力提出了很高的要求。应急方法和手段得当,能够有效地降低非正常事件对铁路运输的影响,减少列车晚点,尽快恢复列车运行;应急处理不当,不仅会扩大非正常事件的影响程度,还可能会引发其他事故,造成更大负面影响。
国内外许多专家学者对列车运行调整领域进行了广泛而深入的研究。文献[1]基于替代图对列车运行调整问题进行建模;文献[2]针对单线铁路的列车运行调整问题提出了遗传算法和人工神经网络;文献[3]以所有列车总延误时间最少为目标,构建线性规划模型,通过对偶算法求得模型的解;文献[4]考虑突发事件持续时间的不确定性,以保证所有列车晚点时间之和的平均值最小为目标函数,构建了有路径选择约束的整数规划模型和无路径选择约束的整数规划模型;文献[5]以列车总晚点时间最小化为目标函数,并考虑了列车区间停站和返回车站停站的问题,构建出混合整数规划模型;文献[6]采用离散事件动态系统理论,将列车占用区间或车站作为离散事件,将由各种技术设备、信联闭设备组成的列车运行调整系统作为离散时间动态系统,建立了离散事件动态系统驱动的状态空间调整模型,并通过网络分层并行算法对问题进行求解;文献[7]通过蚁群算法,利用蚂蚁根据启发函数得到的各点选择概率,搜索图定节点的调整时刻;文献[8]通过遗传模拟退火算法对列车运行调整问题进行求解。
目前,高速铁路应急调整方面主要存在以下几方面问题:调整时间长;应急信息的收集、感知和利用不充分;考虑因素不全面;决策缺乏计算机技术支持等。
虽然关于列车运行调整的理论模型和方法较多,但在应用于实际列车调整过程中时,这些模型和方法仍有许多局限性。在正常调整过程中,调度员仍然发挥着举足轻重的作用,但鉴于应急调整中应急处理时间短、应急处置压力大等因素,调度员难以快速对列车运行图进行科学合理、全面有效的调整。因此,本文基于上述研究,结合高速铁路运行组织现状,考虑实际列车运行调整的原则和方法,研究面向复杂高速铁路网的列车运行计划应急调整方案。设计高速铁路列车应急调整流程,以及非正常事件下基于“一事一图”的高速铁路列车应急调整系统,以提高铁路应急处置能力。
1 高速铁路列车应急调整流程设计
当设备出现故障、发生自然灾害、天气不良等非正常事件造成高速铁路旅客列车大面积晚点时,铁路调度部门需要及时启动应急响应。由相关部门收集整理各类信息,调度员基于相关信息表达调整意图,借助计算机技术实现快速调整。具体应急调整业务流程如图1所示。
如图1 所示,调度部门基于相关信息确定调整方案,调用高速铁路列车应急调整系统(简称:应急调整系统)进行调整。应急调整系统根据调度员意图和相应规则,自动生成新的列车运行图。当调度员对调整结果不满意时或有新的意图表达时,可以重新进行调整。当调度员对调整结果满意时,调整后的列车运行图将提供给应急领导小组决策,若决策不通过,则可重新进行调整;若决策通过后,将由调度员按照调整后的列车运行图,发布调度命令,组织恢复列车运行秩序。在调度执行过程中,如涉及跨铁路局集团公司旅客列车停运、加开临客、启动热备车底、迂回径路运行等情况时,调度员需要及时向中国国家铁路集团有限公司(简称:国铁集团)请求调度命令。
2 系统架构
本文基于高速铁路列车应急调整流程制定非正常事件下的列车运行图,即“一事一图”运行图,设计应急调整系统架构。
应急调整是保障应急指挥安全、提高应急处置效率的核心,与目前的应急调整相比,应急调整系统可以全面收集信息,包括列车运行数据和运输组织数据,同时,支持根据调度员意图生成相应的优化方案,实现不同调整方案的对比分析。由于借助计算机系统,使应急调整系统的处理时间显著减少,可实现快速调整、快速决策,从而提高铁路调度应急处置能力和效率。
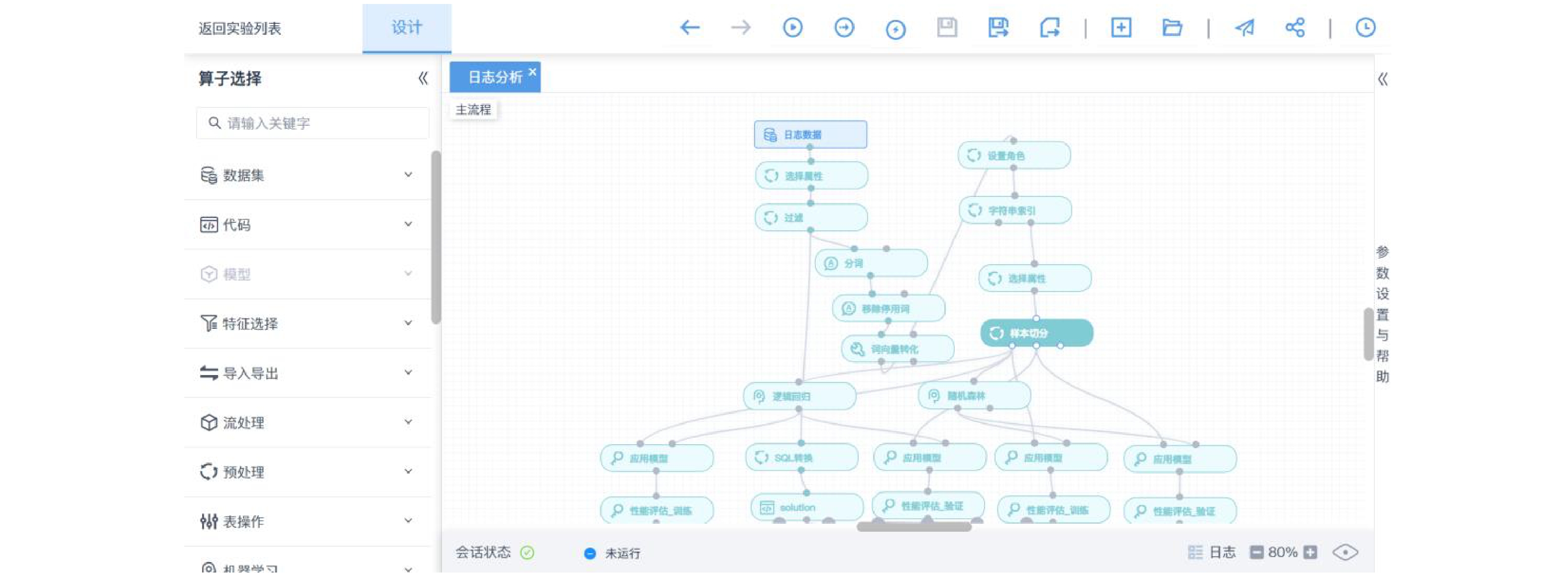
应急调整系统采用模块化设计,主要分为4个模块,其中,数据管理模块、列车调度员人机界面模块和计划下达模块可使用现有系统,列车运行调整求解引擎是独立的模块,现有各模块通过开放接口和数据实现快速集成。其架构如图2所示。
(1)数据管理模块主要实现路网基础数据、应急设备数据、列车动力学数据、客运数据、动车组交路数据、计划数据和运行图数据等的收集和整理;
(2)列车调度员人机界面模块主要实现调度员意图表达、调整计划显示、优化方案对比分析及计划下达等功能,在应急情况下,可以快速生成调整方案;
(3)计划下达模块主要实现将调整计划下达至车站和调度集中系统;
(4)列车运行调整求解引擎模块是应急调整系统的核心,它接受数据输入和调度员意图表达,在安全卡控的原则下,基于调整规则实现调度员的意图,并将调整结果和调整说明返回给列车调度员人机界面模块。
应急调整系统实现了数据管理与方案生成、计划执行之间的闭环管理;在安全方面,实现了计算机和人工双重卡控,提高了应急调整系统的效率和安全性,保证了调整方案的可行性。与现有系统相比,模块化的设计在系统集成、数据管理等方面均有很大优势。
3 系统功能
当突发事件导致高速铁路旅客列车大面积晚点时,铁路部门需要快速响应,基于应急指挥中心成立列车运行调整应急小组,根据列车晚点、车底接续、乘务安排等编制“一事一图”行车组织调整方案。本文设计的应急调整系统主要支持以下功能。
3.1 设置封锁
通过数据管理模块实现铁路网基础数据、应急设备数据(热备车、热备乘务组等)、列车运行数据、扰动数据等的收集和整理;调度员根据系统所收集的信息,结合现场处置情况,研判故障处置时间,设置封锁或限速;随后调用列车运行调整求解引擎,实现应急调整。
3.2 自动生成“一事一图”运行图
列车运行调整求解引擎在安全卡控的原则下,基于调度员意图和调整规则,实现非正常事件下“一事一图”的行车组织调整方案。应急调整系统在生成“一事一图” 行车组织调整方案时,将根据预先定义的调整规则或措施实现,具体调整规则如下:(1)“由近及远”扣停列车;(2)股道的精细化使用;(3)改变列车运行时间;(4)减少车站组织变化;(5)保证动车组接续关系。
3.3 调整计划的修改和下达
在生成调整计划后,调度员可以通过人机界面实现对调整方案的更改、再优化和下达等。当调度员制定了新的调整意图时,可以通过人机界面基于新的调整意图重新优化。同时,调度员对多个意图下的调整方案进行对比分析,选择合适的方案,通过计划下达模块下达给车站和调度集中系统,指导车站客运组织工作和列车运行工作。
4 关键技术
4.1 时空网络模型
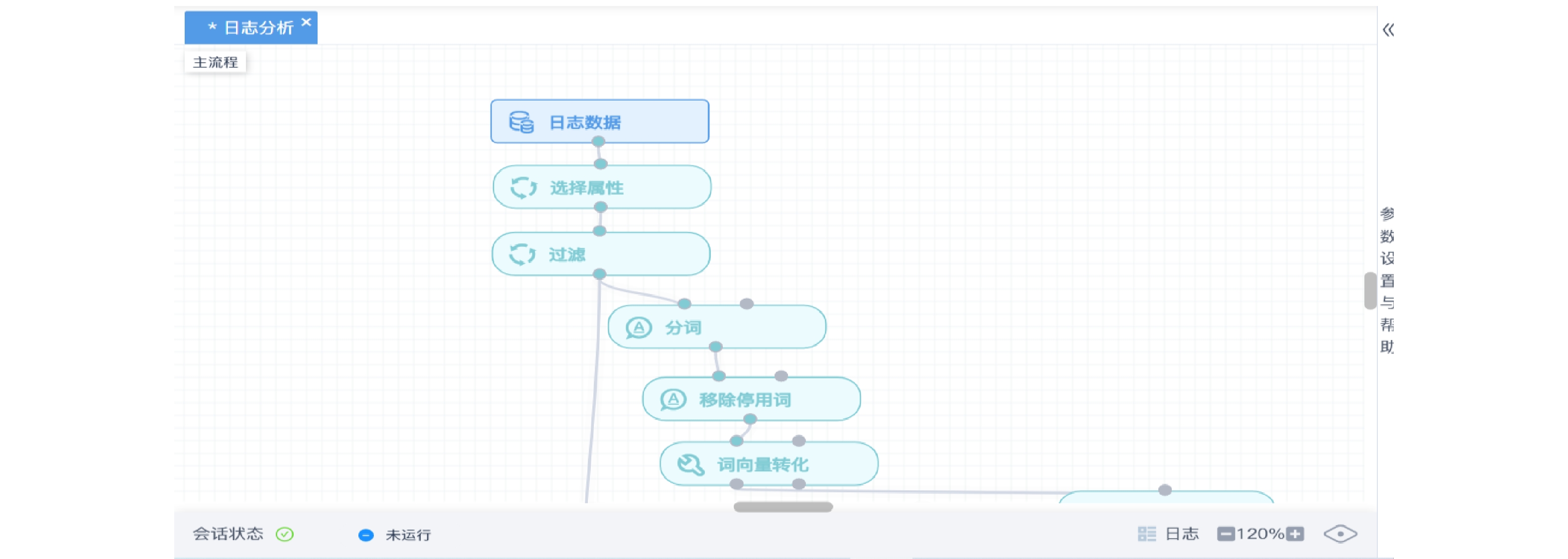
近年来,基于时空网络的建模方法广泛应用于解决列车运行图编制问题,而铁路列车运行调整问题可以看作是列车运行图的再编制过程,其本质是列车在时间和空间上的资源分配问题,因此可将该问题抽象为时空网络模型。网络包含3个要素,分别是网络节点、网络弧和列车时空路径。网络节点用于表示列车在该时间点的空间位置,即列车状态,对应的有虚拟起点、虚拟终点、列车到达节点和列车出发节点。网络弧由节点的连线组成,表示列车的运行状态,包括虚拟起始弧、区间运行弧、车站停站(通过)弧、以及虚拟终止弧。节点和弧共同组成了列车时空路径[9]。其时空网络示意如图3所示。
图3刻画了3列车的时空路径,起终点为网络中的虚拟节点,不同颜色和线型对应不同的弧,由节点和弧共同构成了列车时空路径。
4.2 拉格朗日松弛算法
基于时空网络构建整数规划模型,描述列车运行调整问题。模型求解时采用拉格朗日松弛算法,其核心思想是将模型中复杂的约束松弛,并将其作为惩罚项加入到目标函数中,从而转化为拉格朗日对偶问题,降低模型求解难度的同时提高求解效率[10]。
5 实例分析
以京沪(北京—上海)高速铁路北京局管内线路为例,如图4所示。北京南站高速场共有11条股道供京沪高铁使用,同时作为京沪高铁的尽头站,其上下行股道可混用;德州东站为北京局集团有限公司和济南局集团有限公司的分界口车站,有3条上行到发线,2条下行到发线;京津(北京—天津)线路所接入天津西—北京南方向的列车,津沪(天津—上海)线路所接入天津西—上海虹桥方向的列车。本文以某日接触网挂网引发沧州西—天津南上行区间封锁为例,封锁时间为08:00—10:30,如图4所示。通过应急调整系统得到的调整结果如图5所示。
由图5可知,在封锁结束4 h后,上行列车晚点时间和数量都显著减少,到14:20,上行列车晚点基本消除,与实际调整结果相符。
6 结束语
应急调整系统作为应急处置工作的重要工具,辅助调度员安全、快速、科学、合理制定应急列车运行图,对恢复列车运行秩序、提高铁路系统的应急处置能力至关重要。本文基于列车应急调整流程,设计了应急场景下的调度调整系统,以京沪高铁某日接触网挂网导致线路中断为例,进行了分析。本系统已部署到中国铁路北京局集团有限公司应急指挥中心,在应用中效果良好,提高了铁路应急处置能力,为铁路调度应急指挥提供了辅助决策支持。
-
表 1 风险识别及评估指标
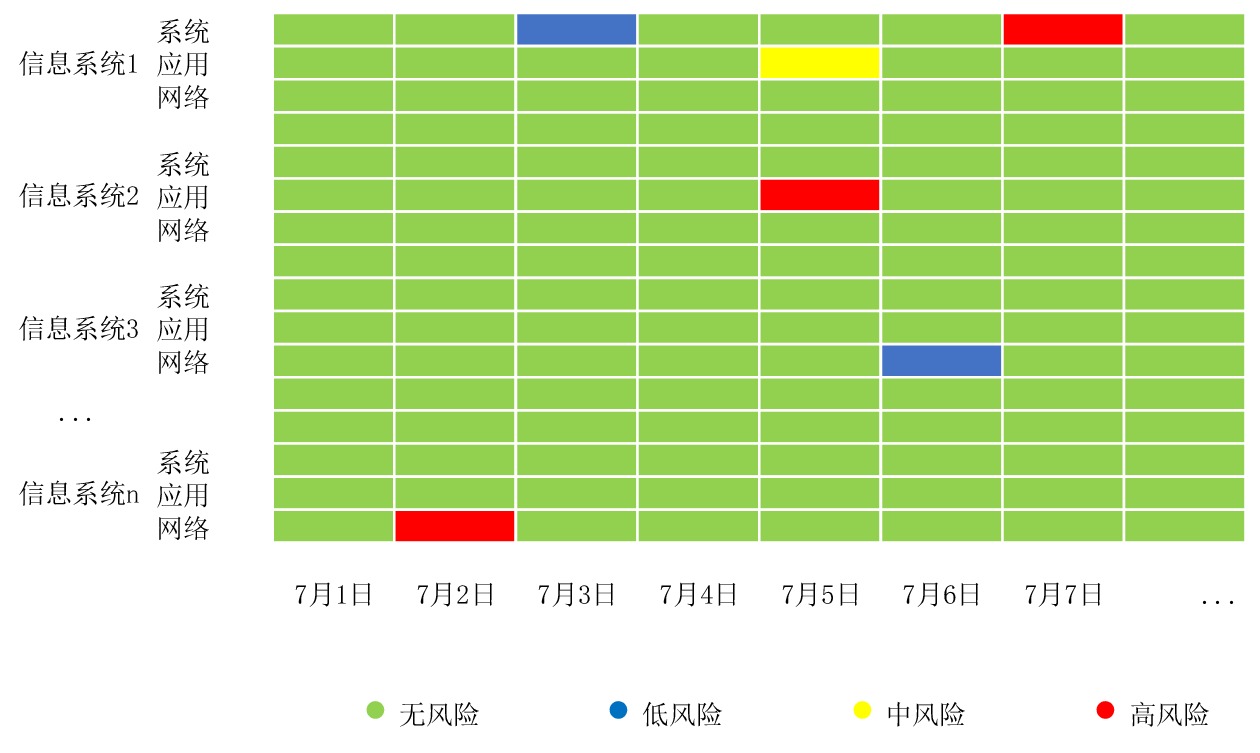
运维对象类别 风险点 级别 建议采取措施 出现频次/日 持续时间 备注 数据库 sjk-12516 高 立即联系项目组***处理 >0 1 min 应用 YY-0009 低 注意观察 =1 60 min 应用 YY-0009 中 提醒项目组***处理 >1 30 min 应用 YY-0019 高 提醒项目组***处理 >1 5 min 网络 WL-0001 高 立即联系项目组***处理 >0 5 min 系统-磁盘 Sys-xxx1 高 立即联系项目组***处理 >0 15 min … …  下载: 导出CSV
下载: 导出CSV
表 2 风险等级控制(示例)
风险类别 风险点 风险级别 建议采取措施 处置反馈 数据库 sjk-12516 高 立即联系项目组***处理 第一时间联系项目***进行处置,*时*分预警已恢复 应用 yy-0009 低 注意观察 持续观察60 min,风险无明显提升,已关闭 系统 Xt-1024 中 请联系项目组***及时处置。 已联系项目***进行处置,反馈为预警为运维操作引起,待运维结束后,预警恢复。*时*分预警已恢复
下载: 导出CSV
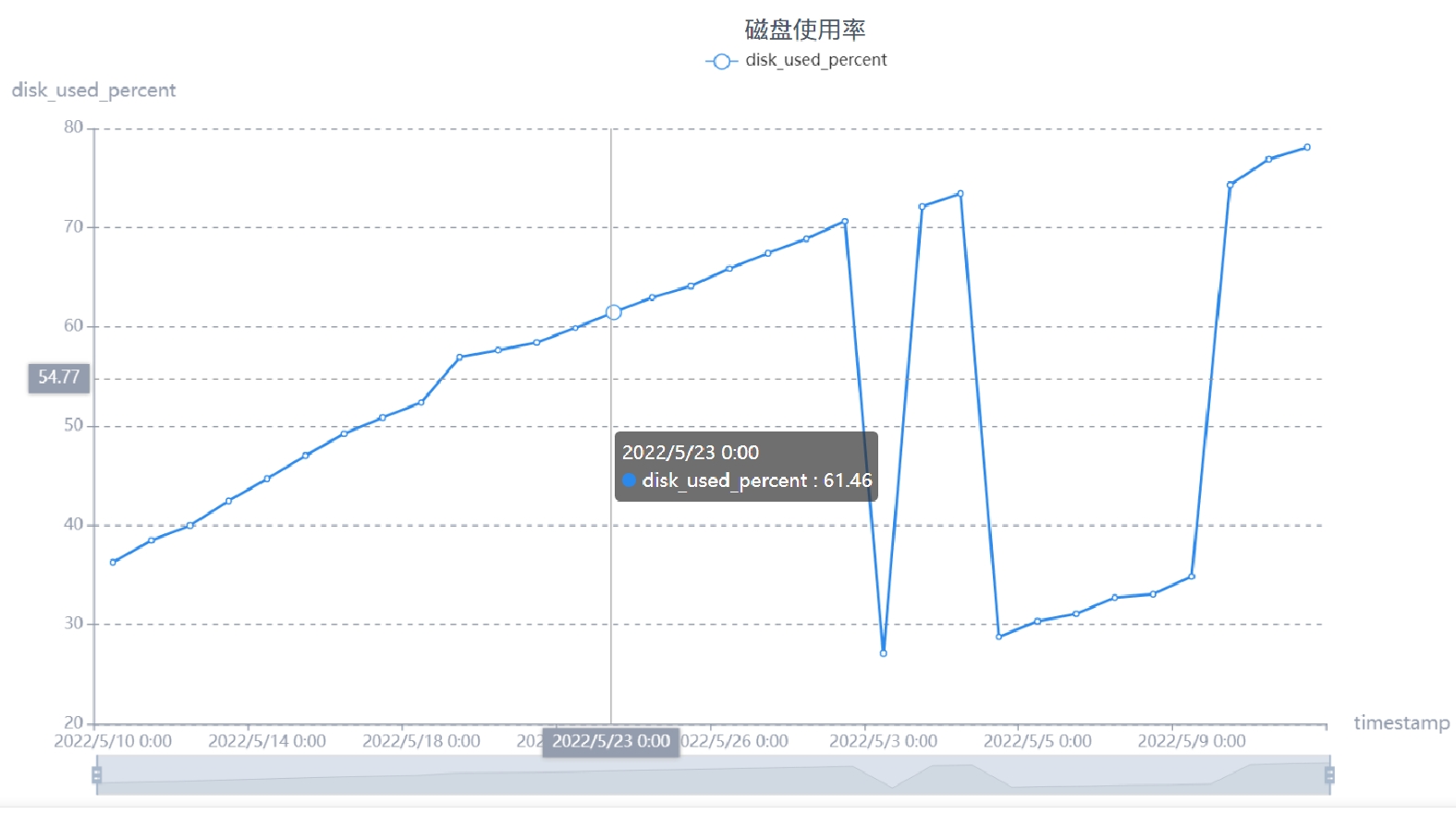
表 3 服务器集群磁盘使用情况记录
序号 字段名 字段含义 字段类型 1 disk_total 磁盘总量 数值型 2 disk_free 磁盘余量 数值型 3 disk_used 磁盘使用量 数值型 4 disk_used_percent 磁盘使用百分比 数值型 5 measurement_name 指标名称 字符型 6 timestamp 时间 字符型 7 tag_mode 磁盘模式 字符型 8 tag_host 磁盘所属主机host 字符型 9 tag_ip 磁盘所属主机ip 字符型 10 tag_device 磁盘所属设备编号 字符型 11 tag_path 磁盘所属路径 字符型
下载: 导出CSV
表 4 服务器集群磁盘使用率等级
序号 规则 等级 颜色标识 1 0≤ disk_used_percent <65 信息(Info) 绿 2 65≤ disk_used_percent <85 告警(Warn) 黄 3 85≤ disk_used_percent ≤100 错误(Error) 红
下载: 导出CSV
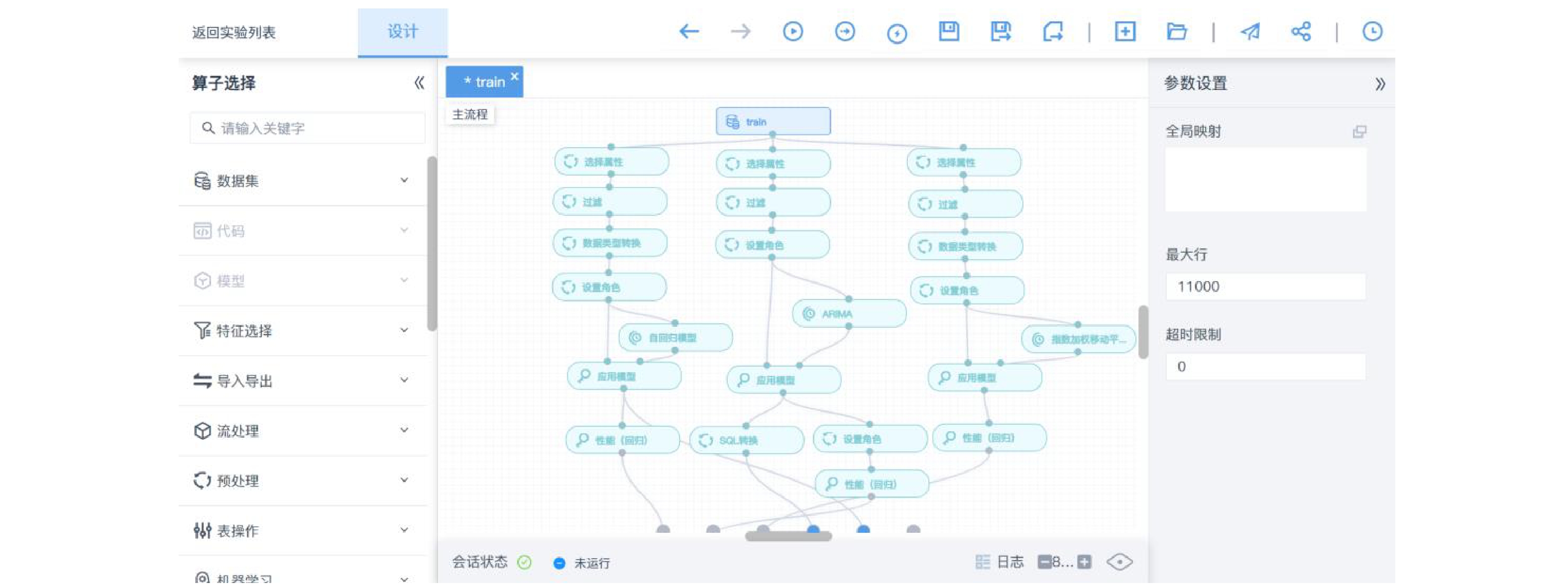
表 5 3种预测模型的MAE值对照
序号 模型名称 MAE 1 自回归模型 1.4604445235290773 2 ARIMA模型 0.4940755669450921 3 指数加权移动平均模型 0.6212854858662921
下载: 导出CSV
表 7 风险矩阵
时间 风险点 级别 建议采取措施 出现频次/日 持续时间 202206010923 sjk-xxxx1 高 立即联系项目组***处理 >0 5 min 202206091301 sjk-xxx10 中 提醒项目组***处理 >1 30 min …
下载: 导出CSV
-
[1] 马建军,李 平,马小宁,等. 铁路一体化信息集成平台总体架构及关键技术研究 [J]. 中国铁道科学,2020,41(5):153-161. [2] 湛林福,杨澎涛,范永合,等. 一种基于日志分析的智能告警技术 [J]. 信息技术与信息化,2020(9):208-210. [3] 吴佳清,姚文伟. 大数据分析技术在高校人才质量评价中的应用 [J]. 科技传播,2019,11(11):118-119. DOI: 10.3969/j.issn.1674-6708.2019.11.075 [4] 武 威,马小宁,刘彦军,等. 铁路数据服务平台安全策略研究 [J]. 中国铁路,2019(8):63-68. DOI: 10.19549/j.issn.1001-683x.2019.08.063 [5] 田绵石. 新一代数据中心架构及其智能监控系统的研究与探讨 [J]. 铁路计算机应用,2014,23(7):34-38. DOI: 10.3969/j.issn.1005-8451.2014.07.010 [6] Miloslavskaya N, Tolstoy A. Big data, fast data and data lake concepts [J]. Procedia Computer Science, 2016, 88: 300-305. DOI: 10.1016/j.procs.2016.07.439
[7] 郭文惠. 数据湖——一种更好的大数据存储架构 [J]. 电脑知识与技术,2016,12(30):4-6. [8] 王 喆,马小宁,邹 丹,等. 基于铁路数据服务平台的铁路数据资产管理研究 [J]. 铁路计算机应用,2021,30(3):23-26. [9] 马小宁. 铁路大数据应用实践及展望 [J]. 铁路计算机应用,2019,28(4):8-13. DOI: 10.3969/j.issn.1005-8451.2019.04.003 -
期刊类型引用(1)
1. 杨文成,霍磊,郑玢,赵鹏,乔俊飞,张小虎. 基于IFC标准和数据库技术的铁路站场自动化BIM建模方法. 铁道标准设计. 2023(10): 78-85 .  百度学术
百度学术
其他类型引用(0)





计量
- 文章访问数: 122
- HTML全文浏览量: 110
- PDF下载量: 46
- 被引次数: 1
