

Speech noise reduction model for railway passenger station scene
-
摘要: 为进一步提升铁路客运站嘈杂环境下的语音识别效果,文章提出一种基于Conformer的语音降噪模型ConformerGAN。其训练流程类似生成对抗网络,生成器采用Conformer进行语音特征提取,对特征建模;鉴别器使用代理评估函数对语音感知进行质量评价。为增强模型的泛化能力并提高模型对未知噪声的降噪能力,在噪声的叠加上采用随机截取片段融入的方式,并构建铁路客运站场景噪声数据集。与语音降噪相关模型效果对比的结果表明,ConformerGAN模型可将客观语音质量评估(PESQ,Perceptual Evaluation of Speech Quality)分数提高0.19,有效提高铁路客运站嘈杂环境下的语音识别准确率,改善铁路旅客语音交互体验。
-
关键词:
- 铁路客运站 /
- 语音降噪 /
- Conformer /
- 生成对抗网络(GAN) /
- 语音识别
Abstract: In order to further improve the speech recognition effect in the noisy environment of the station, this paper proposed a Conformer based generative adjunctive network Conformer Generative Adversarial Network (GAN) for speech noise reduction. Its training process was similar to GAN, generator used the Conformer to extract speech features and model them; discriminator constructed a proxy evaluation function to evaluate the perceptual quality of speech. In order to enhance the generalization ability of the model and improve the noise reduction ability of the model for unknown noise, the overlay of noise was incorporated by randomly intercepting fragments. The paper also built a station scene noise dataset. Compared with the effect of related models, the ConformierGAN model can improve the Perceptual Evaluation of Speech Quality (PESQ) score by 0.19, effectively improve the accuracy of voice recognition in the noisy environment of railway passenger stations, and improve the voice interaction experience of railway passengers. -
语音降噪是通过语音信号处理技术及相关算法,提高伴有背景噪声语音信号的可懂度或整体感知评价的一种技术,是语音识别、通信系统等语音交互领域的重要研究内容。早期主要通过数字信号分析的方法来实现语音降噪,如谱减法、滤波法等,以时域、频域或时频结合[1]的方式对语音信号进行分解,找到干净语音或噪声的特征,从而将二者分离,属于无监督方法;随着技术的演进,以深度学习为基础的有监督语音降噪方法倍受好评,深度学习算法以大量合成的实验语音为样本,通过时频掩蔽或频谱映射的方法,对神经网络进行训练,并得到干净语音的掩码或估测幅值,从而实现语音降噪[2-3]。
目前,应用于语音降噪的深度学习网络结构甚多,例如,多层感知机、卷积神经网络(CNN,Convolutional Neural Network)、循环神经网络(RNN ,Recurrent Neural Network)、生成对抗网络(GAN ,Generative Adversarial Network)等。多层感知机是最基本也最简单的语音降噪网络,其网络中的所有节点都是完全连接的[4]。Xu等人[5]于2014年提出包含3个隐藏层的多层感知机网络,使用对数功率谱作为输入、输出特征进行语音降噪,但由于模型结构过于复杂,导致计算量较大,使得处理时间和计算成本增加;CNN最初被广泛应用于图像相关任务[6],后有研究表明[7]CNN在语音处理中同样具有显著的效果;RNN擅长处理带有时序特征的任务[8],充分利用之前时刻与当前时刻语音帧之间的联系,但RNN在频率维度特征提取方面能力较弱,会导致降噪语音感知度较低;GAN可看作是生成器与鉴别器的博弈[9],在语音降噪中常用的目标函数仅是估计谱图和目标谱图之间的L1或L2正则化距离,然而,较短的正则化距离不代表更高的语音质量。为解决该问题,MetricGAN[10]采用直接优化评价指标分数的生成器,该分数是由鉴别器学习得到的;除此以外,许多降噪方法利用Transformer[11]来捕捉波形或频谱图中的长距离依赖性;最近,Conformer[12-13]被引入,作为Transformer的替代方案,发挥同时捕获局部特征和全局特征的能力。
受上述研究工作启发,在研究面向铁路客运站场景的语音降噪模型时,要选择合适的语音降噪模型进行优化改进,使其达到一个较好的降噪效果,并融入铁路客运站场景相关噪声,以增强模型的铁路领域特征。因此,本文研究基于Conformer关联度量(Metrics)的生成对抗网络ConformerGAN,改进语音降噪模型,完成铁路客运站等嘈杂交互场景下的语音降噪任务。
1 相关模型
1.1 MetricGAN+模型
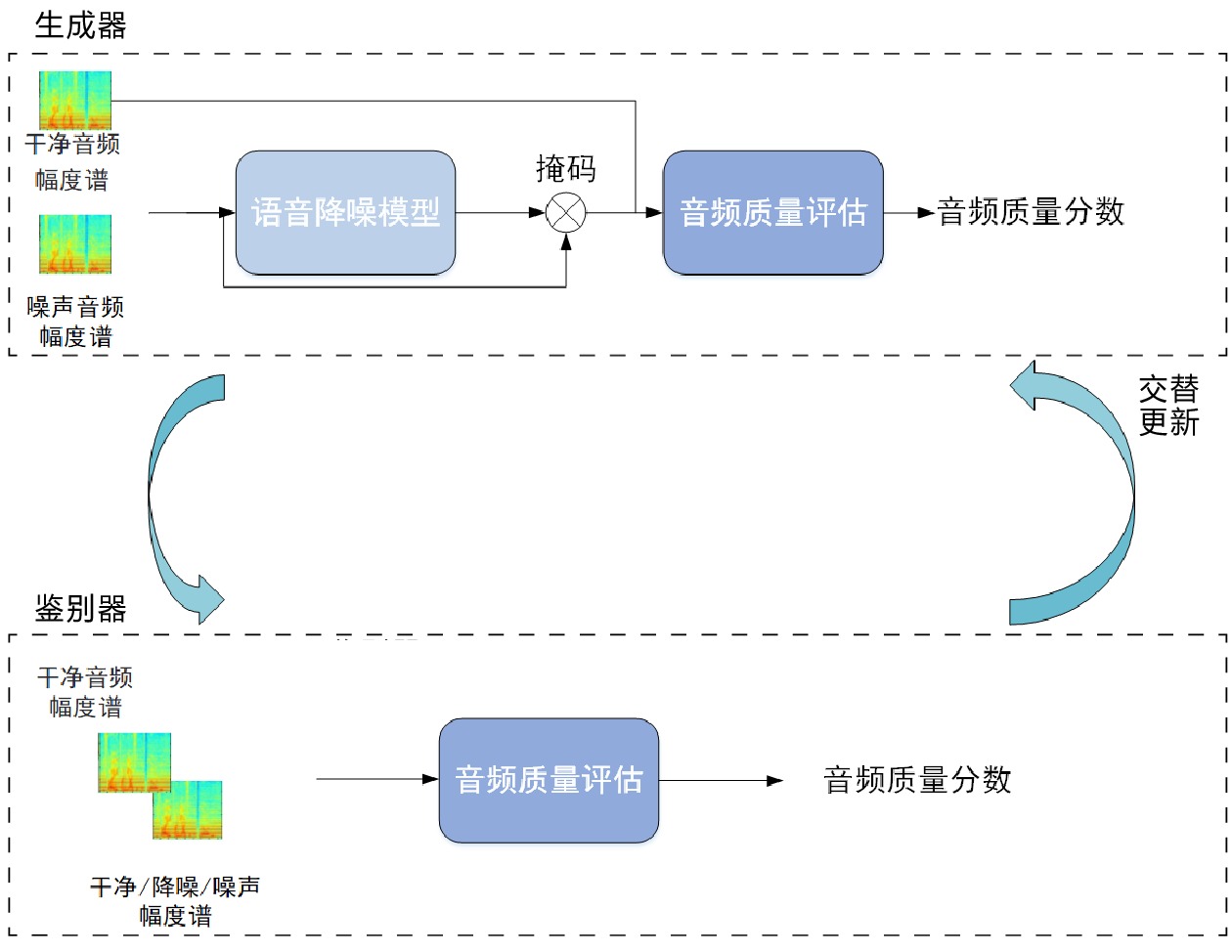
MetricGAN+[14]是一种用于优化语音质量的语音降噪模型。由于语音降噪模型的损失函数与人类听觉感知之间有差异,直接使用模型的损失函数去评估语音优化质量效果欠佳。MetricGAN+的训练流程类似于GAN,其目的是用神经网络模拟目标评估函数(例如客观语音质量评估(PESQ,Perceptual Evaluation of Speech Quality)函数)的行为。代理估计函数从原始分数中学习。该模型将目标评估函数视为黑盒,将代理估计函数用作语音增强模型的损失函数,训练模型时,交替更新代理估计部分的损失和神经网络部分的损失。
MetricGAN+模型将幅度谱图作为输入,生成器部分采用前向长短时记忆(LSTM,Long Short-term Memory)网络与后向LSTM相结合成的双向长短时记忆(BiLSTM[15])网络结构,之后是2个全连接层,第1层全连接层包含用于掩码估计的激活函数(LeakyReLU)节点,第2层全连接层包含可学习的激活函数(Sigmoid)节点。当掩码与输入的噪声幅度谱图相乘时,噪声分量被去除。鉴别器网络采用4个二维CNN,为处理可变长度的输入,添加了二维全局平均池化层,随后连接3个全连接层。
MetricGAN+模型的训练流程,如图1所示,上半部分为生成器、下半部分为鉴别器,在训练过程中两部分交替更新。语音降噪模型采用神经网络结构;音频质量评估表示与神经网络关联得到的目标评估函数,如PESQ函数;掩码用于去除噪声分量。
1.2 Conformer模型
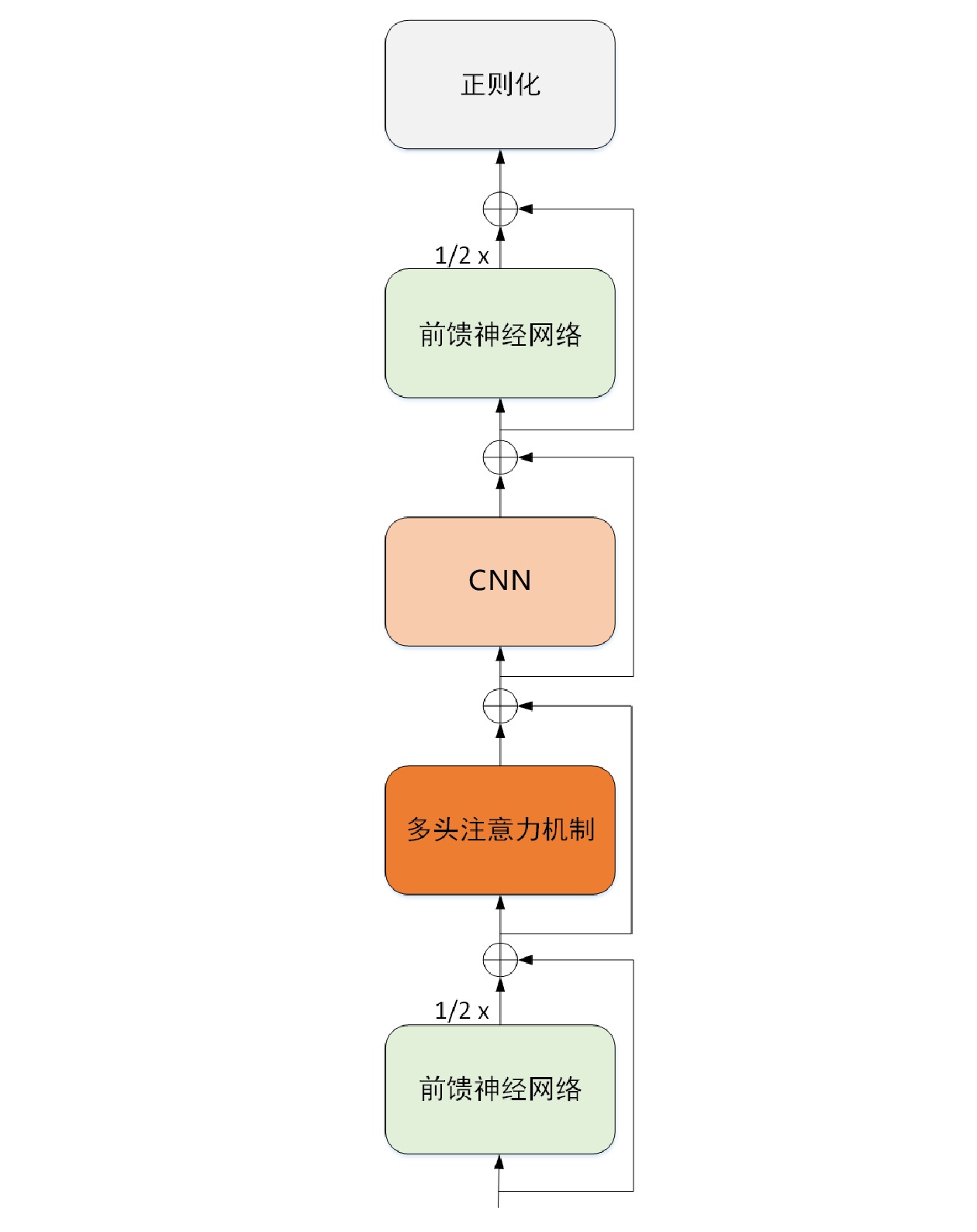
Conformer模型被称作基于卷积增强的Transformer模型,是CNN和Transformer结合构成的模型,由前馈神经网络、多头注意力机制和CNN组成,Conformer 结构,如图2所示。
其中,2个前馈神经网络模块输出结果都乘以了1/2。实验验证表明[12],与只取单个前馈神经网络模块结构的全部输出相比,各取2个前馈神经网络模块一半的输出,可使模型整体上表现出更为优异的性能。Conformer 计算流程如公式(1)~(4)所示。
˜xi=xi+12FFN(xi) (1) x′i=˜xi+MHSA(˜xi) (2) xi″ (3) {y_i} = Layernorm({x''_i} + \frac{1}{2}FFN({x''_i})) (4) 其中,
FFN 、MHSA 、Conv 、L{\text{a}}yernorm 分别为前馈神经网络、多头注意力机制、卷积神经网络、归一化。{x_i} 表示Conformer的输入;{\tilde x_i} 表示前馈网络的输出;{x'_i} 表示多头注意力机制的输出;{x''_i} 表示卷积模块的输出;{y_i} 表示Conformer的输出结果。2 语音降噪模型结构
2.1 设计方法
深度学习语音降噪大致分为2个方向:(1)时域端到端方法,可从噪声中直接估计除去噪声的语音波形;(2)用短时傅里叶变换计算基于时频的算法,基于时频算法进一步可分为基于掩码的估计和基于映射的估计,基于掩码估计的方法从噪声的声学特征中估计出掩盖噪声值,将掩盖噪声值与噪声幅度谱相乘,得到除去噪声的语音信号,基于映射的估计从噪声中直接估计干净的幅度谱。
MetricGAN+模型采用基于掩码估计的方法,在构建的领域数据集上可取得较好效果,PESQ分数为3.10。受相关模型结构的启发,本文提出一种基于Conformer的语音降噪模型ConformerGAN,其训练流程与MetricGAN+模型相同,类似于GAN。
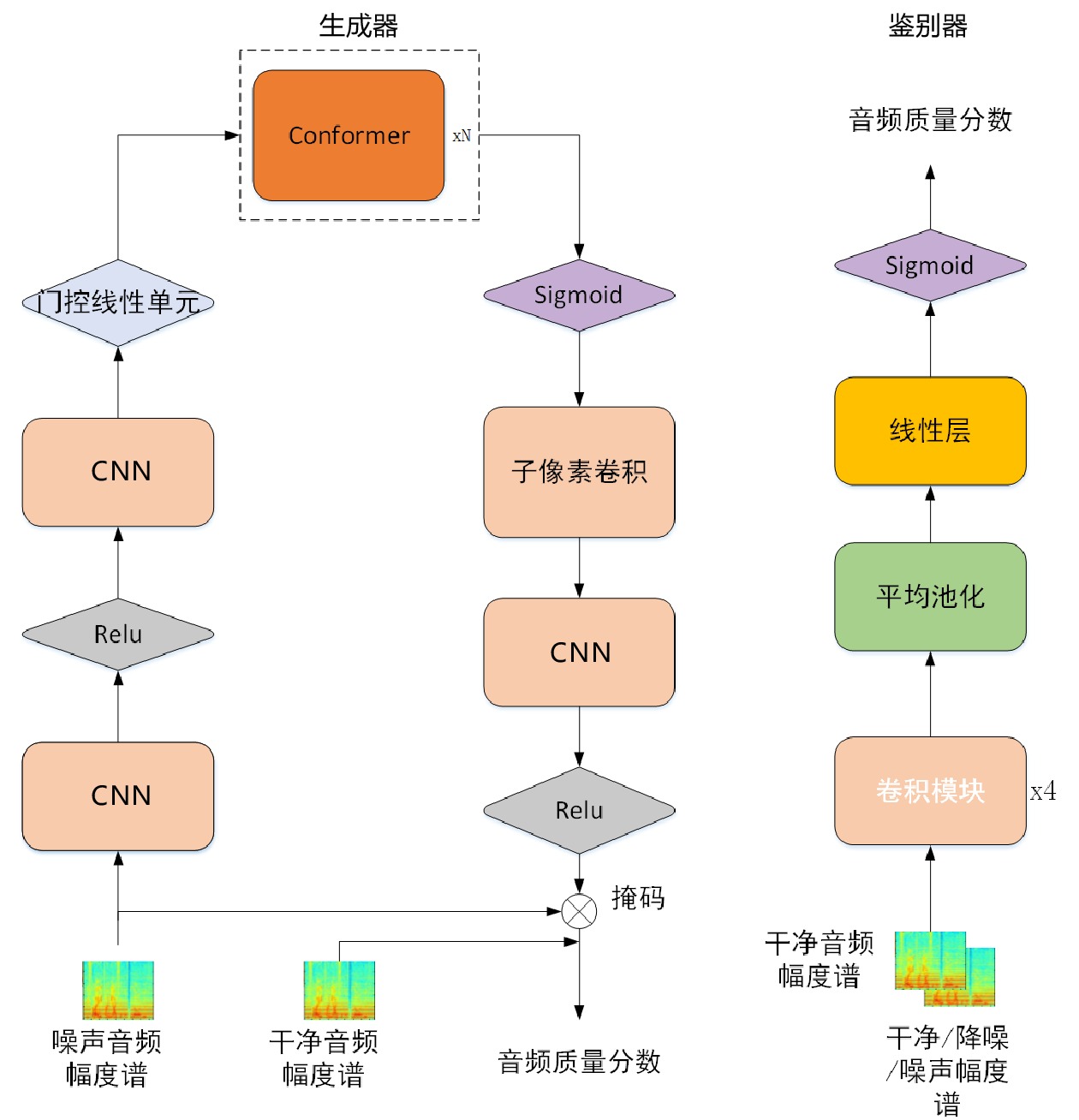
在铁路客运站服务场景下,存在背景噪声过大、多噪声类型混合的情况,同时需要考虑帧与帧之间的关联性,因而在生成器中引入语音特征提取能力更好的Conformer编码器结构。ConformerGAN生成器由CNN、Conformer、子像素卷积(Sub-pixel Convolution)、激活函数Relu和门控线性单元构成。鉴别器由CNN、平均池化(Avg.Pooling)、线性层(Linear Layer)和激活函数Sigmod构成。ConformerGAN的模型结构,如图3所示。
2.2 训练流程
输入一条嘈杂的语音后,由于语音信号具有短时平稳特性,不利于进行傅里叶分析,需要对语音进行加窗分帧,然后再进行傅里叶变换,转换为语音复数向量
{Y_0} ,将复数向量{Y_0} 进行幂律压缩得到频谱图Y ,频谱图表示信号频率与能量的关系。{Y_m} 表示幅度;c 表示压缩系数,取值在0到1之间;{{j}} 表示虚数;{Y_p} 表示相位。语音信号处理过程如公式(5)所示。Y=\left|Y_0\right|^c e^{j Y_p}=Y_m e^{j Y_p} (5) 生成器流程:(1)将幅度
{Y_m} 作为生成器的输入,经过2个二维卷积神经网络,降低特征维度的同时还可学习到潜在的特征表示;(2)将提取到的潜在特征表示放入Conformer模块,并使用激活函数Sigmod平滑Conformer模块的输出;(3)获取到输出后,使用子像素卷积层来提升特征维度;(4)使用卷积层加激活函数Relu来预测掩码,将噪声幅度谱图与掩码相乘,理论上会得到降噪后的语音。生成器的训练目的是生成与干净语音相似的降噪语音。鉴别器流程:(1)经过4个相同的卷积模块,每个卷积模块包括卷积神经网络、归一化、LeakyReLU激活。CNN利用时间和空间上的平移不变性,克服语音信号本身的多样性;归一化保证训练过程中数据的有效性;LeakyReLU激活函数可使网络引入非线性因素。(2)在卷积模块后连接一个平均池化层、一个线性层和一个Sigmoid激活函数。当输入是一对干净的语音和降噪语音及这对语音对应的PESQ标签时,可用来估计降噪后的PESQ得分。
ConformerGAN的损失优化过程与GAN相同,即训练是对生成器损失
{L_G} 和相应的鉴别器损失{L_D} 的最小优化任务。损失计算公式为{L_G} = {E_{x,y}}[{(D(x,y) - 1)^2}] (6) {L_D} = {E_x}[{(D(y,y) - 1)^2}] + {E_{x,y}}[{(D(x,y) - {Q_{PES Q}})^2}] (7) 其中,
G 表示生成器;D 表示鉴别器;x 表示干净语音;y 表示经过降噪的语音;{Q_{PES Q}} 表示归一化的PESQ得分;{E_x} 表示对干净语音做极大似然估计;{E_{x,y}} 表示对干净和降噪后的语音做极大似然估计。3 改进模型语音降噪效果分析
3.1 数据集构建及训练参数设置
在数据集构造方面,相比于使用相同的噪声片段,从每类噪声中随机选取叠加所需的噪声片段,可增强模型的泛化能力,提高模型对未知噪声的降噪能力。
为加强语音降噪模型的铁路客运站场景领域特征,需构建适用于铁路客运站场景的语音服务数据集。干净语音数据集一部分来源于铁路12306互联网售票系统人工客服对话语音数据,对人工客服语音数据进行拆分和人工校验;另一部分是组织专人录制的旅客常见问题的语音数据。干净语音平均时长5~7 s,共12000条有效语音片段。噪声数据集引入铁路客运站广播录音、铁路客运站大厅环境录音、检票口人工播报录音、人工服务台环境录音等,每条录音选取约5 min作为背景噪声。在训练集中,随机从干净语音片段中选择11000条,并与铁路客运站录音噪声随机生成的与干净语音等长的噪声片段进行叠加,混合信噪比分别为0、5 dB、10 dB、15 dB。在测试集中,将剩余的1000条干净语音与未见噪声以同样随机生成噪声片段的方式进行叠加,混合信噪比分别为2.5 dB、7.5 dB、12.5 dB、17.5 dB。
语音特征提取需要对语音进行加窗分帧并进行傅里叶变换,实验所有语音均为单声道,采样率设为16 kHz,语音帧长设为16 ms,帧移设为8 ms。幂律压缩系数c设为0.7,Conformer模块数量N分别设为2、4、12,训练的batch size设为16。模型的生成器和鉴别器均采用Adam优化器,训练最大迭代设为100。
3.2 实验环境配置
为保证实验环境配置的处理能力满足算法模型训练需要,本文采用的配置如表1所示。
表 1 实验环境配置实验环境 配置 操作系统 Linux CPU型号 Inter® Xeon®CPU E5-2698 v4 @2.20 GHz GPU型号 Tesla V100 运行内存 251 GB 编程语言 Python 算法框架 Pytorch 3.3 评估指标和实验结果
实验选用4种评价指标来评估降噪后的语音质量,分别是PESQ、CSIG、CBAK、COVL。其中,PESQ量化语音信号的感知质量,CSIG、CBAK和COVL分别代表相同尺度下语音信号的信号失真、背景干扰和整体质量的平均主观意见评分。平均主观意见评分的范围在1~ 5之间,值越高表示性能越好。
以MetricGAN+模型作为基线模型,在数据集上对改进前后的模型进行对比测试,基线模型和改进后模型的测评结果,如表2所示。
表 2 模型测评结果模型 PESQ CSIG CBAK COVL MetricGAN+ 3.10 4.02 3.11 3.43 ConformerGAN(N=2) 3.21 4.30 3.36 3.71 ConformerGAN(N=4) 3.29 4.55 3.57 3.81 ConformerGAN(N=12) 3.28 4.40 3.55 3.78 从实验结果可看出,本文提出的模型在所有的评价指标上都优于基线模型。考虑到网络层数(参数规模)会对模型的评价标准有影响,在实验中将网络层数N分别设置为2层、4层、12层进行对比。结果表明,与基线模型相比,ConformerGAN(N=2)模型的PESQ提升0.11、CSIG提升0.28、CBAK提升0.25、COVL提升0.28;ConformerGAN(N=4)模型的PESQ提升0.19、CSIG提升0.53、CBAK提升0.46、COVL提升0.38。当尝试进一步提高网络层数时,各项指标并未如期增长,结果与ConformerGAN(N=4)模型基本相当,甚至略微下降,这可能是因为随着模型深度的增加导致某些浅层的学习能力有所下降。另外,文献[14]表明基线模型在公开数据集VoiceBank-DEMAND上指标PESQ、CSIG、CBAK、COVL分别为3.15、4.14、3.16、3.64。可看出各项指标均优于在铁路客运站语音服务数据集上的结果,这可能是因为相比公开数据集,自建数据集场景噪声的影响因素更加复杂多变。
4 车站智能服务机器人语音降噪应用实例
在铁路客运站应用场景下,由于站内广播声音过大,会在旅客与车站智能服务机器人交互过程中产生负面影响。为解决该问题,将本文提出的语音降噪模型ConformerGAN与语音识别服务相结合,应用到车站智能服务机器人中。在铁路客运站内多个子场景下,分别对比200条语音数据,平均音频时长3 s。语音质量及对语音识别字错率(CER ,Character Error Rate)的影响,如表3所示。
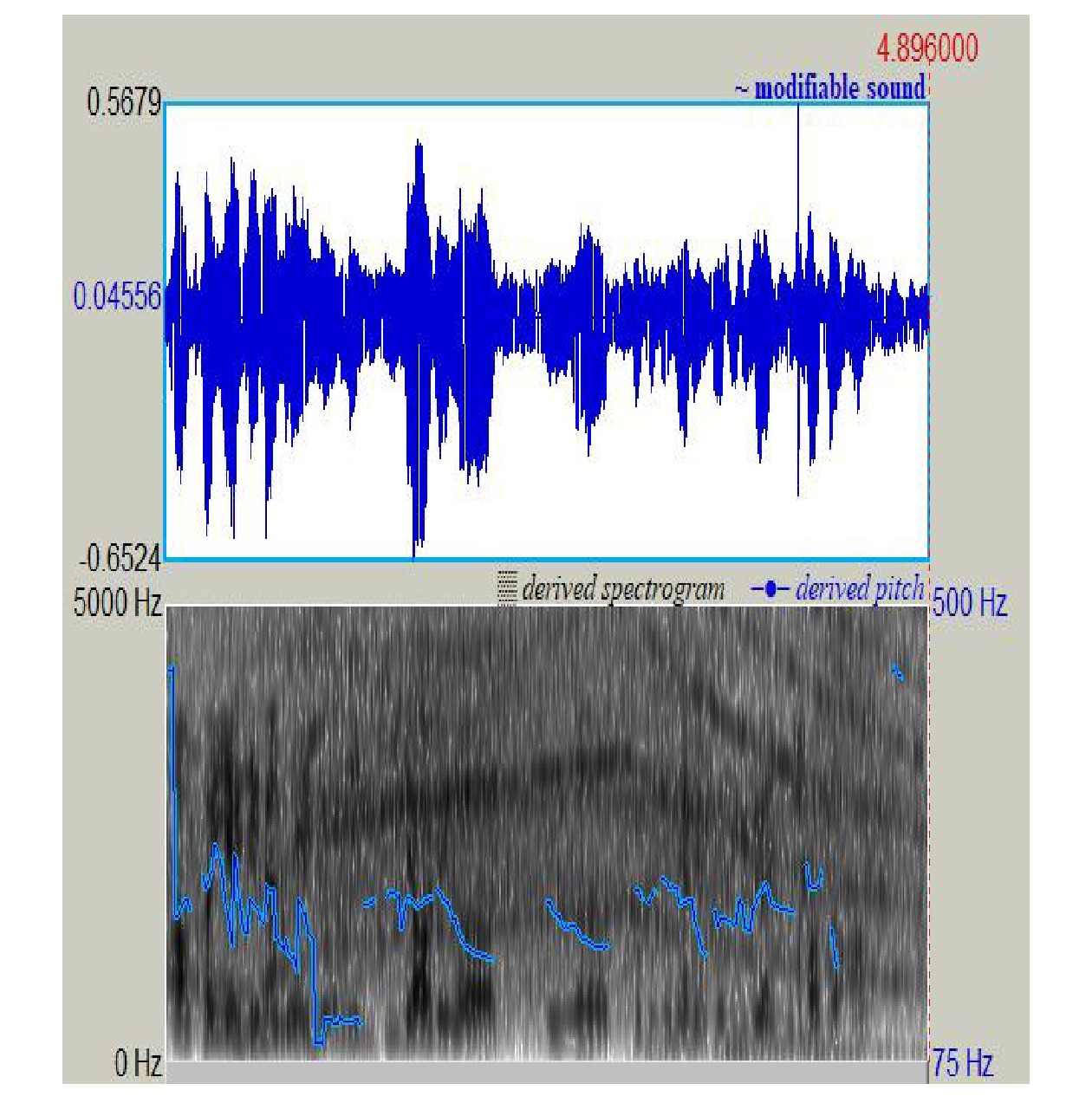
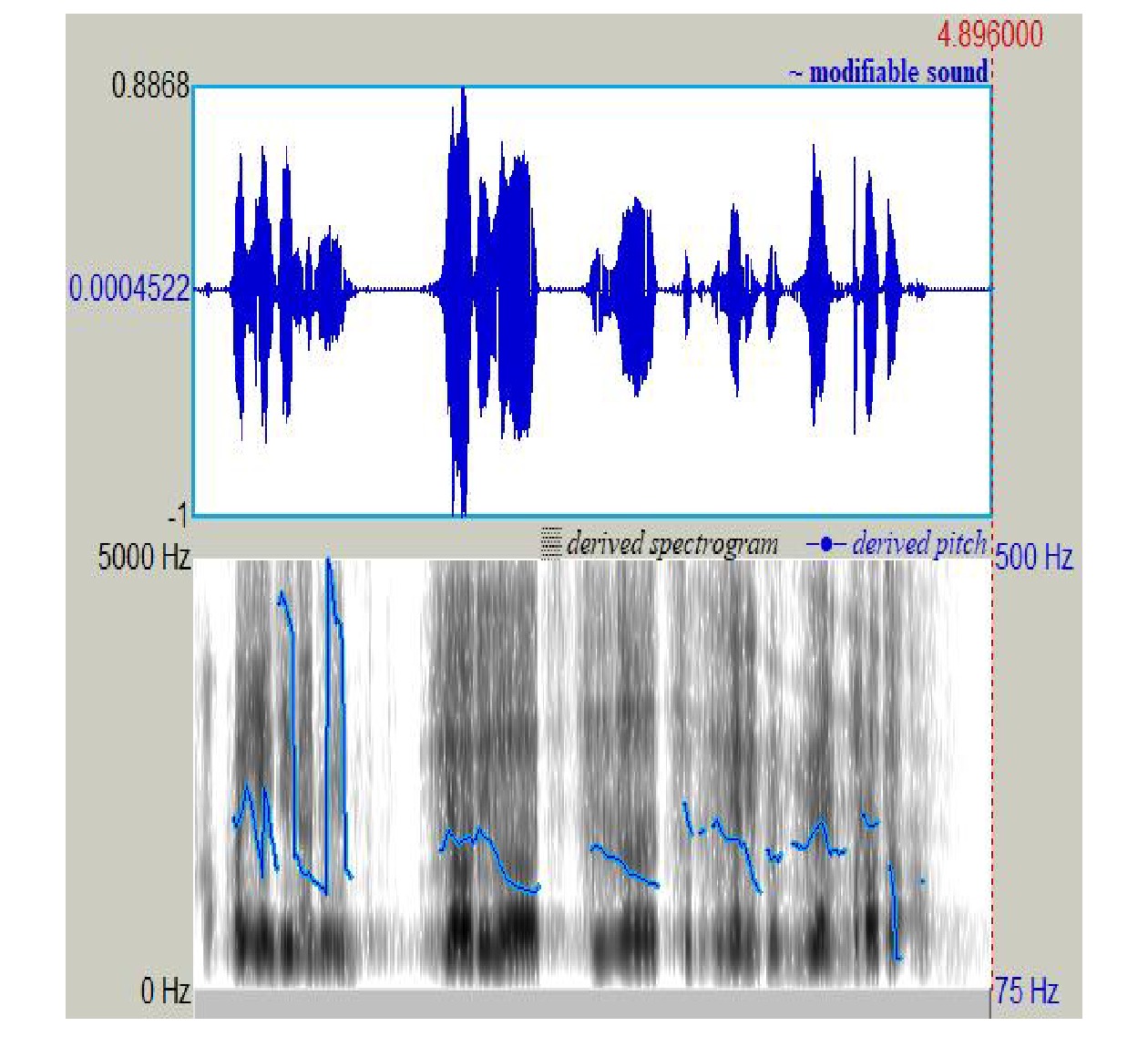
表 3 车站智能服务机器人语音降噪效果语音背景噪声类型 PESQ CER(降噪前) CER(降噪后) 站内广播 3.10 15.67 10.35 人工服务台 3.20 14.32 10.27 检票口 3.22 11.68 9.44 结果显示,在铁路客运站多个子场景下,使用本文的语音降噪模型均能够提升语音质量,图4为降噪前的音频语图,图5为降噪后的音频语图。音频语图的上、下分别表示语音波形图和语谱图。音频语图横坐标表示时间(单位:ms),语音波形图部分纵向表示幅度,语谱图部分纵向表示频率(单位:Hz)。将本文研究的降噪模型与车站智能服务机器人结合后,能够有效降低车站嘈杂背景对语音识别准确率的影响,提升用户的交互体验。
5 结束语
本文提出一种铁路客运站场景下的语音降噪模型ConformerGAN,考虑到Conformer更加适用于序列建模的特性,同时在鉴别器中使用代理评估函数,解决评估度量不匹配问题。实验和模型落地应用的结果均表明,所提出的模型在铁路客运站场景下能够取得较好的降噪效果,并提升客运站场景下语音识别的准确率。下一步,本文的语音降噪服务将逐渐扩展到铁路出行服务的多个应用场景。因此,如何使语音降噪模型在更多的应用场景下达到较好的降噪效果,将是下一阶段的研究重点。
-
表 1 实验环境配置
实验环境 配置 操作系统 Linux CPU型号 Inter® Xeon®CPU E5-2698 v4 @2.20 GHz GPU型号 Tesla V100 运行内存 251 GB 编程语言 Python 算法框架 Pytorch  下载: 导出CSV
下载: 导出CSV
表 2 模型测评结果
模型 PESQ CSIG CBAK COVL MetricGAN+ 3.10 4.02 3.11 3.43 ConformerGAN(N=2) 3.21 4.30 3.36 3.71 ConformerGAN(N=4) 3.29 4.55 3.57 3.81 ConformerGAN(N=12) 3.28 4.40 3.55 3.78
下载: 导出CSV
表 3 车站智能服务机器人语音降噪效果
语音背景噪声类型 PESQ CER(降噪前) CER(降噪后) 站内广播 3.10 15.67 10.35 人工服务台 3.20 14.32 10.27 检票口 3.22 11.68 9.44
下载: 导出CSV
-
[1] 王 芳,刘祖润,吴海辉. 基于软硬阈值折中的小波包语音增强算法的研究 [J]. 铁路计算机应用,2010,19(7):8-10. DOI: 10.3969/j.issn.1005-8451.2010.07.003 [2] 闫昭宇,王 晶. 结合深度卷积循环网络和时频注意力机制的单通道语音增强算法 [J]. 信号处理,2020,36(6):863-870. DOI: 10.16798/j.issn.1003-0530.2020.06.007 [3] 袁文浩,胡少东,时云龙,等. 一种用于语音增强的卷积门控循环网络 [J]. 电子学报,2020,48(7):1276-1283. DOI: 10.3969/j.issn.0372-2112.2020.07.005 [4] Riedmiller M. Advanced supervised learning in multi-layer perceptrons—from backpropagation to adaptive learning algorithms [J]. Computer Standards & Interfaces, 1994, 16(3): 265-278.
[5] Xu Y, Du J, Dai L R, et al. A regression approach to speech enhancement based on deep neural networks [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(1): 7-19. DOI: 10.1109/TASLP.2014.2364452
[6] Albawi S, Mohammed T A, Al-Zawi S. Understanding of a convolutional neural network[C]//2017 international conference on engineering and technology (ICET), 21-23 August, 2017, Antalya, Turkey. New York, USA: IEEE, 2017: 1-6.
[7] Deng L, Yu D. Deep learning: methods and applications [J]. Foundations and Trends® in Signal Processing, 2014, 7(3-4): 197-387.
[8] Sun L, Du J, Dai L R, et al. Multiple-target deep learning for LSTM-RNN based speech enhancement[C]//2017 Hands-free Speech Communications and Microphone Arrays, 1-3 March, 2017, San Francisco, CA, USA. New York: IEEE, 2017: 136-140.
[9] Goodfellow I J, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//Proceedings of the 27th International Conference on Neural Information Processing Systems, 8-13 December, 2014, Montreal Canada. Cambridge, USA: MIT Press, 2014: 2672-2680.
[10] Fu S W, Liao C F, Tsao Y, et al. MetricGAN: generative adversarial networks based black-box metric scores optimization for speech enhancement[C]//Proceedings of the 36th International Conference on Machine Learning, 9-15 June, 2019, Long Beach, USA. PMLR, 2019: 2031-2041.
[11] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems, 4-9 December, 2017, Long Beach, USA. Red Hook: Curran Associates Inc. , 2017: 6000-6010.
[12] Gulati A, Qin J, Chiu C C, et al. Conformer: convolution-augmented transformer for speech recognition[C]//Proceedings of the 21st Annual Conference of the International Speech Communication Association, 25-29 October, 2020, Shanghai, China. ISCA, 2020: 5036-5040.
[13] Chen S Y, Wu Y, Chen Z, et al. Continuous speech separation with conformer[C]//ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 6-11 June, 2021, Toronto, ON, Canada. New York, USA: IEEE, 2021: 5749-5753.
[14] Fu S W, Yu C, Hsieh T A, et al. MetricGAN+: an improved version of metricGAN for speech enhancement[C]//Proceedings of the 22nd Annual Conference of the International Speech Communication Association, 30 August - 3 September, 2021, Brno, Czechia. ISCA, 2021: 201-205.
[15] Shi X J, Chen Z R, Wang H, et al. Convolutional LSTM network: a machine learning approach for precipitation nowcasting[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems, 7-12 December, 2015, Montreal, Canada. Cambridge, USA: MIT Press, 2015: 802-810.
-
期刊类型引用(1)
1. 胡必波,刘红英,王传传,甄雅迪. 基于Transformer-LSTM架构的语音去噪方法研究. 信息记录材料. 2025(04): 49-51 .  百度学术
百度学术
其他类型引用(1)









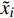



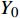
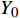
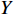
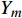
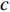
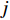
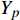

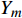
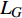
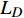


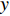
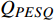
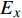
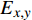
计量
- 文章访问数: 155
- HTML全文浏览量: 86
- PDF下载量: 31
- 被引次数: 2
