

Multi-label image classification model for identification of prohibited items in luggage security check
-
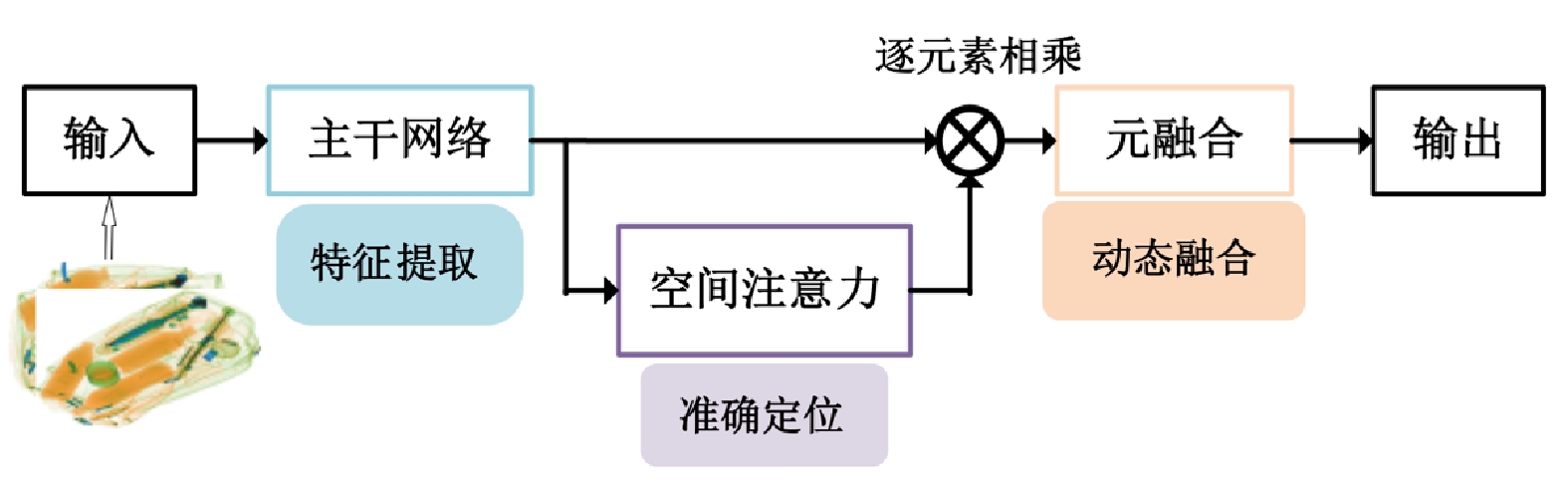
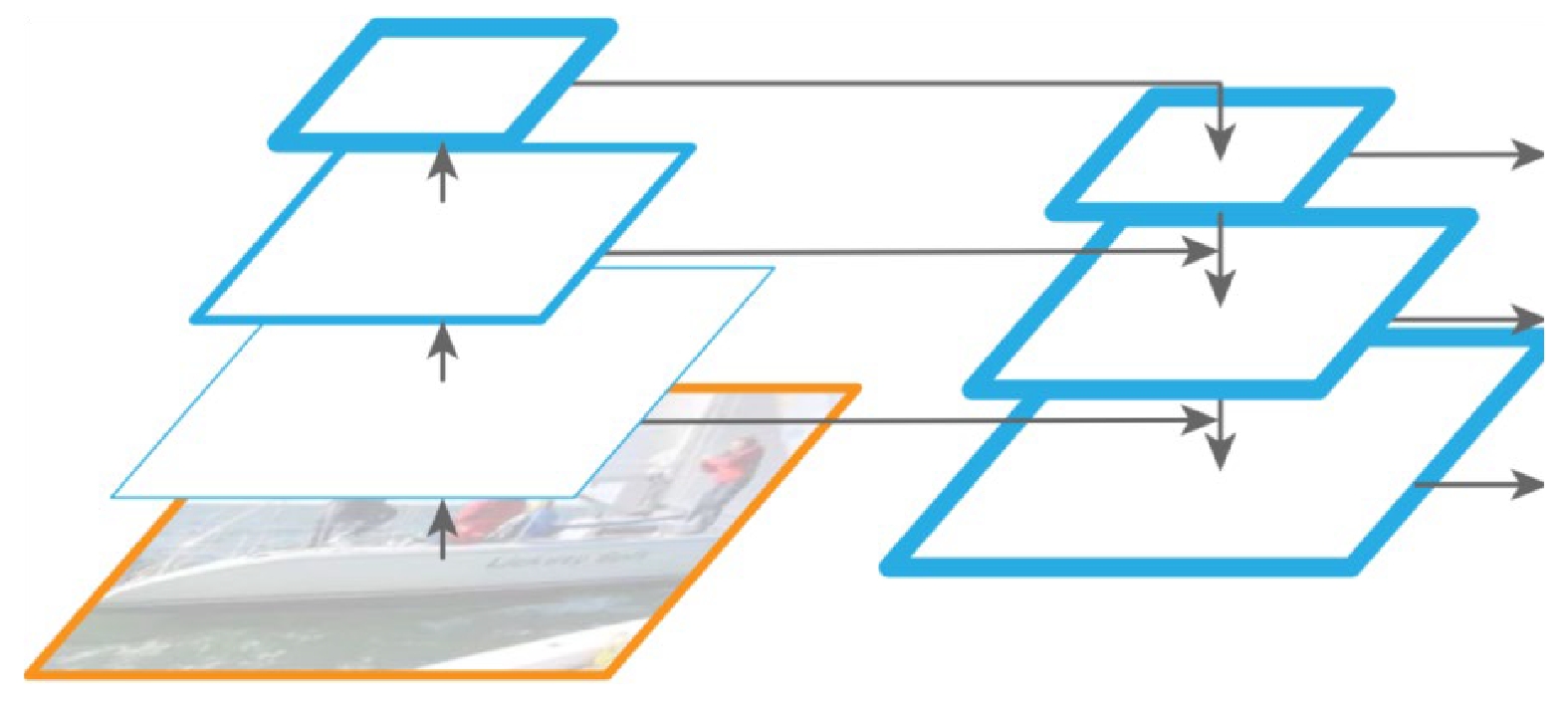
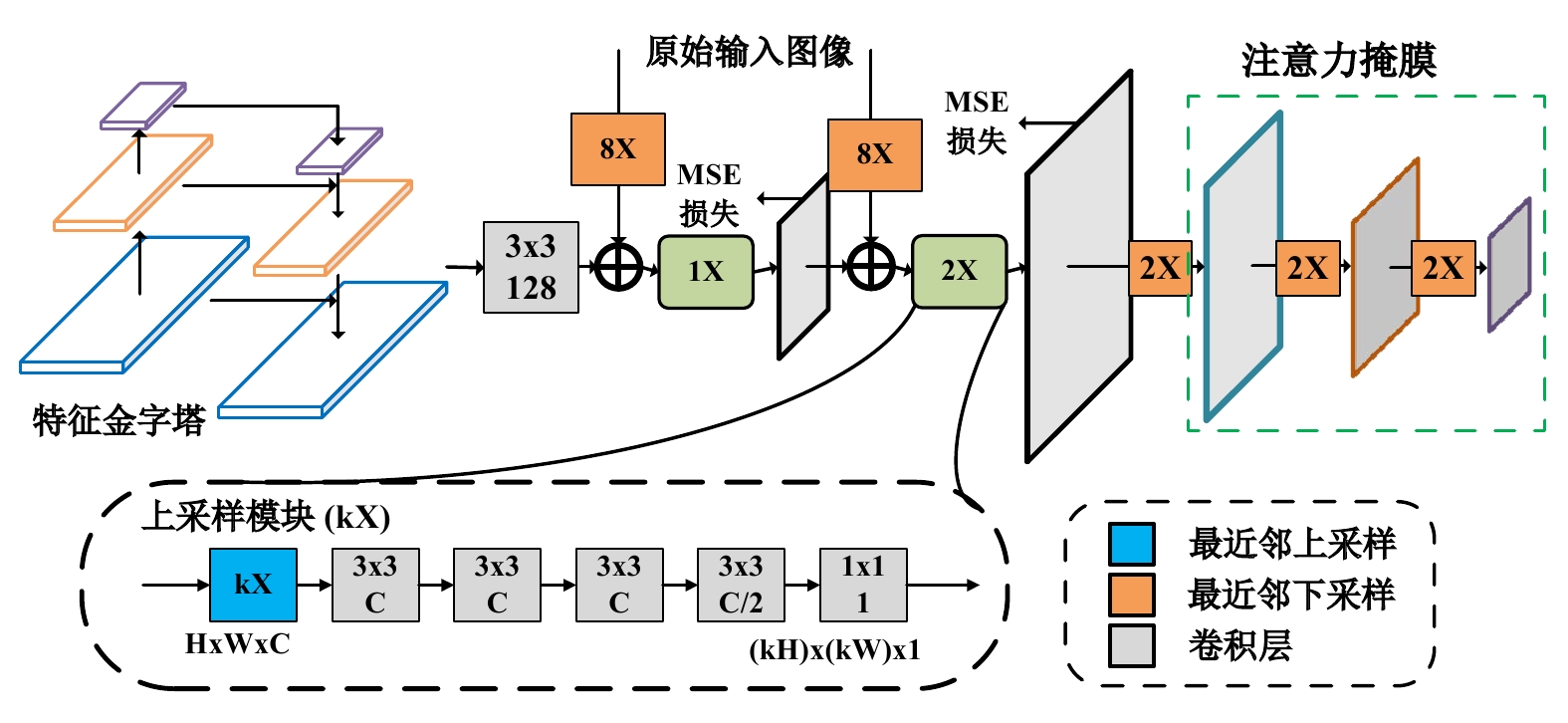
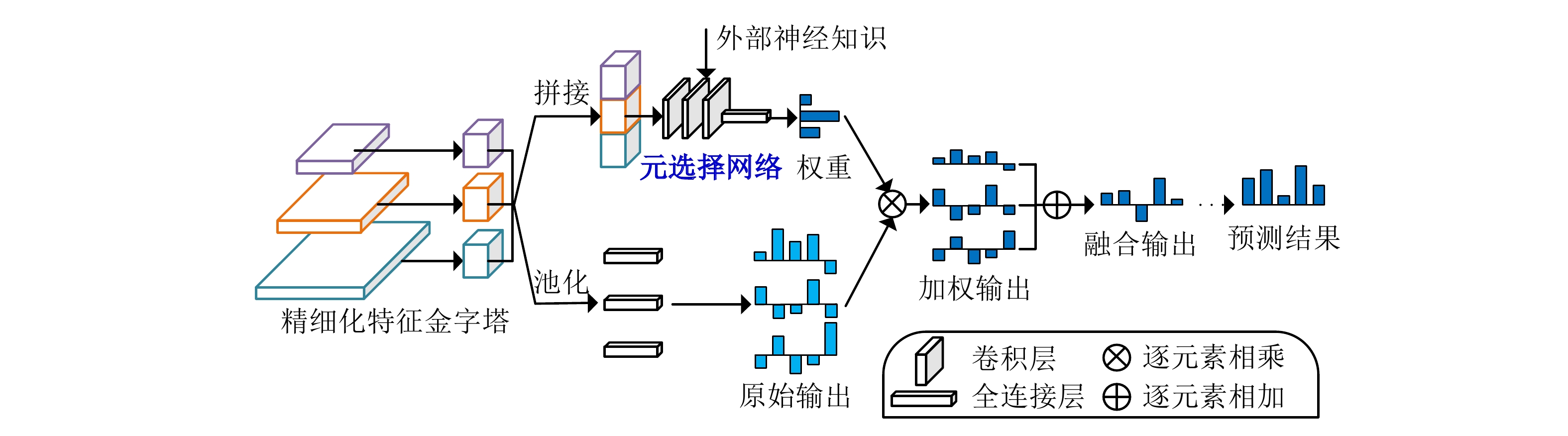
摘要: 有效识别禁限带物品的智能识别算法有助于降低安检人员劳动强度,提升旅客行李安检作业效率。文章采用图像多标签分类的深度卷积神经网络,通过引入图像注意力机制与动态元融合,能够在卷积前向传递过程中补充低层图像视觉线索,有效应对行李X光图像中物品影像混叠干扰及低分辨率特征混淆的问题,增强对细粒度特征的识别能力;同时,引入外部神经知识的元选择网络,实现网络多阶段预测的自适应融合,以避免权重偏置现象。实验结果表明,文章算法能够克服行李X光图像中影像混叠和物品尺度变化带来的禁限带物品识别困难,有效提高识别准确率。Abstract: An intelligent identification algorithm for effective identification of prohibited items can help reduce the labor intensity of security personnel and improve the efficiency of passenger luggage security. We propose a deep convolutional neural network with multi-label image classification in which attention mechanism and dynamic meta-fusion architecture are adopted to complement low-level image cues during the forward progression of the convolution computing and can effectively cope with the interference of pixel aliasing and the confusion of low-resolution features in fine-grained X-ray image, thus enhancing the ability to recognize fine-grained features. Besides, the meta selection network guided by external neural knowledge is also adopted to achieve adaptive fusion of multi-stage prediction without weight bias. The experimental results show that the proposed algorithm can overcome the difficulty of identification of prohibited items caused by image aliasing and item scale variation in X-ray baggage images, and effectively improve the recognition accuracy.
-
-
表 1 多标签分类算法识别准确率对比
ResNet50 Res50-FPN CHR 本文算法 SIXray
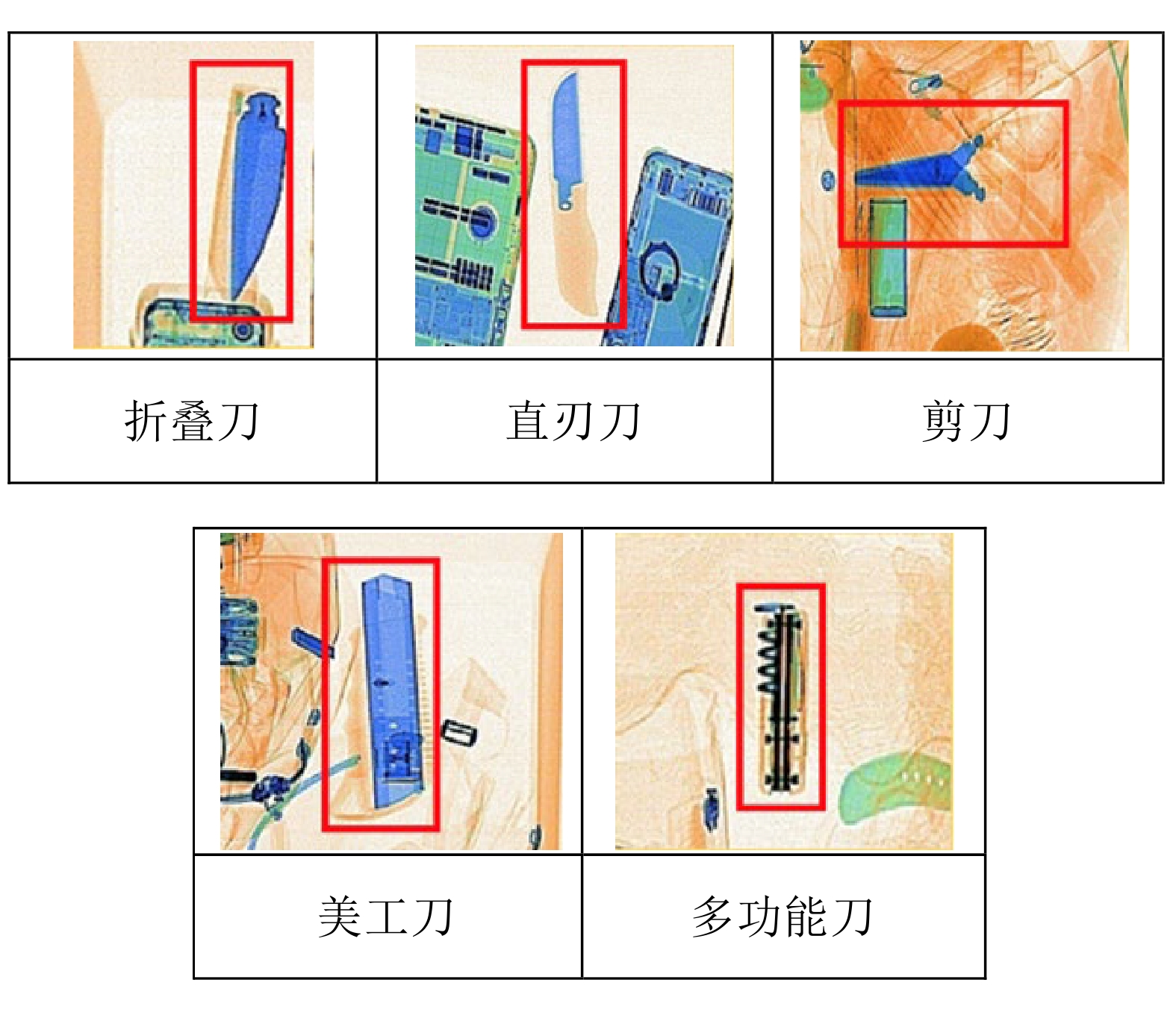
数据集枪械 98.70 98.23 98.29 98.84 刀具 92.59 93.45 94.87 95.22 钳子 96.41 96.66 96.40 98.33 剪刀 91.09 92.30 91.75 96.11 扳手 86.74 88.66 88.51 95.38 mAP 93.36 93.86 93.96 96.78 OPIXray刀具数据集 折叠刀 92.93 93.92 94.62 96.11 直刃刀 65.40 64.76 67.42 75.37 剪刀 99.05 99.18 98.93 99.34 美工刀 78.25 78.83 80.39 84.32 多功能刀 96.15 96.20 97.28 97.69 mAP 86.35 86.58 87.73 90.83  下载: 导出CSV
下载: 导出CSV
表 3 不同融合策略的消融实验结果
融合策略 SIXray OPIXray 无 95.91 88.32 门控融合Gated Fusion 96.15 90.67 直觉元融合MF-I 96.33 90.36 神经元融合MF-N 96.78 90.83
下载: 导出CSV
-
[1] 国家铁路局. “十四五”铁路科技创新规划[Z]. 北京: 国家铁路局, 2021. [2] Cao Sisi, Liu Yuehu, Song Wenwen, et al. Toward human-in-the-loop prohibited item detection in X-ray baggage images[C]// November 22-24, 2019, Hangzhou, China. Beijing, China: Chinese Automation Congress (CAC), 2019: 4360-4364.
[3] Miao C, Xie L, Wan F, et al. Sixray: A large-scale security inspection x-ray benchmark for prohibited item discovery in overlapping images[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. June 16-20, 2019, Long Beach, California, USA. New York , USA: IEEE,2019: 2119-2128.
[4] Lin T. Y, Dollar P, Girshick R, et al. Feature pyramid networks for object detection[C]// Proceedings of the IEEE conference on computer vision and pattern recognition, July 22-25, 2017, Honolulu, USA. New York, USA: IEEE, 2017: 2117–2125.
[5] Gaus Y F A, Bhowmik N, Akcay S, et al. Evaluating the Transferability and Adversarial Discrimination of Convolutional Neural Networks for Threat Object Detection and Classification within X-Ray Security Imagery[C]// 18th International Conference On Machine Learning And Applications, December 16-19, 2019, Florida, USA. New York, USA: IEEE, 2019: 420-425.
[6] Wei Y, Tao R, Wu Z, et al. Occluded prohibited items detection: An x-ray security inspection benchmark and de-occlusion attention module[C]// Proceedings of the 28th ACM International Conference on Multimedia. October 12-16, 2020, Seattle, USA. New York , USA: ACM, 2020: 138-146.
-
期刊类型引用(0)
其他类型引用(1)



计量
- 文章访问数: 154
- HTML全文浏览量: 34
- PDF下载量: 38
- 被引次数: 1
