

Detection method of passenger flow density in train carriage based on improved YOLOv5s
-
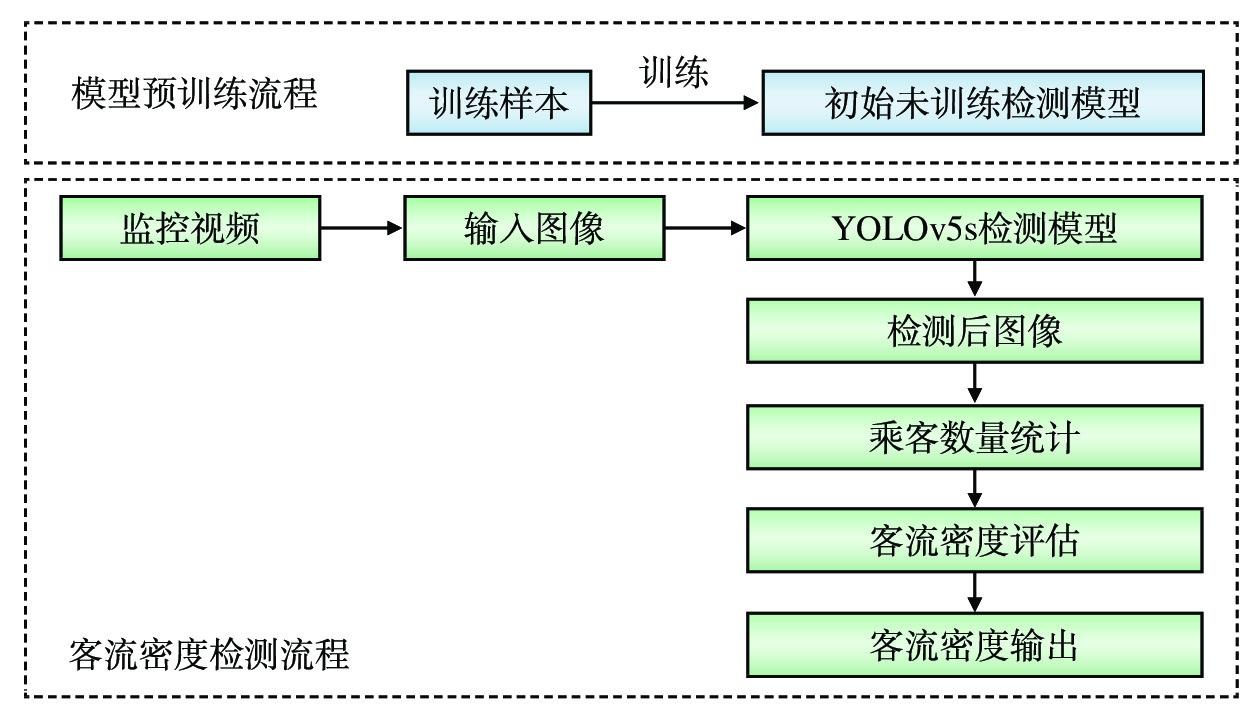
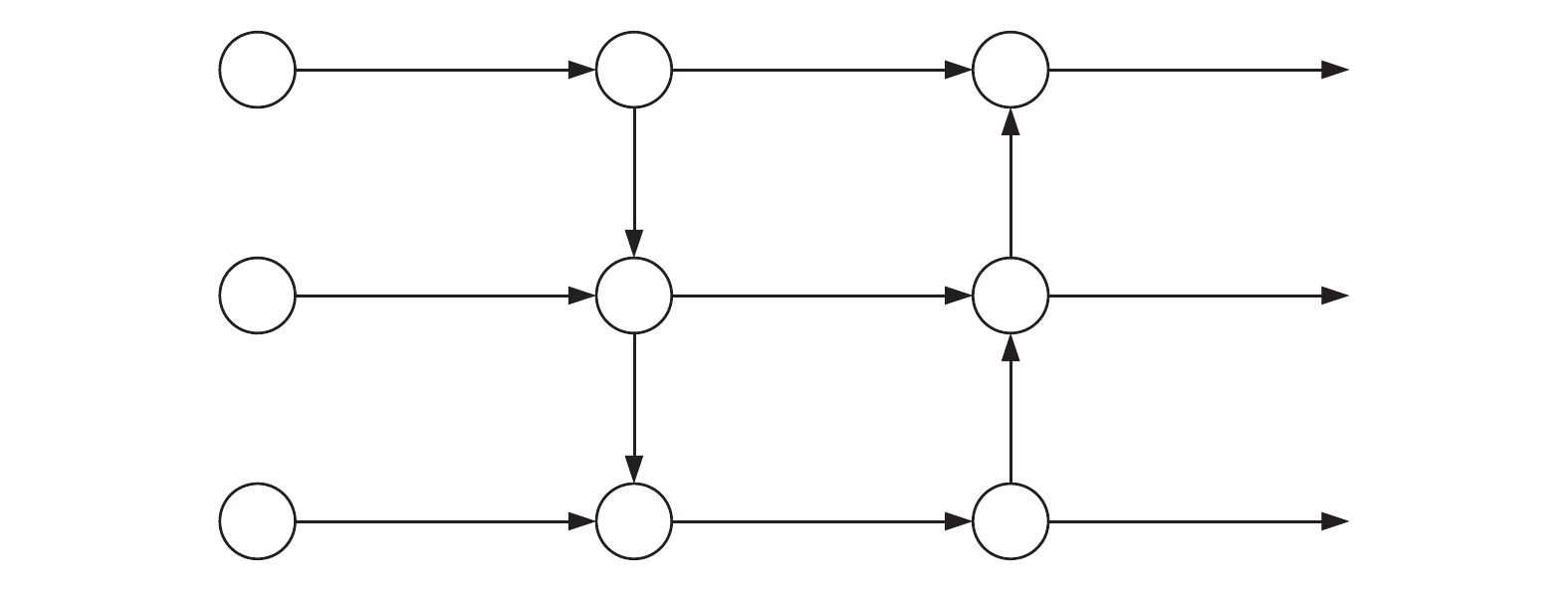
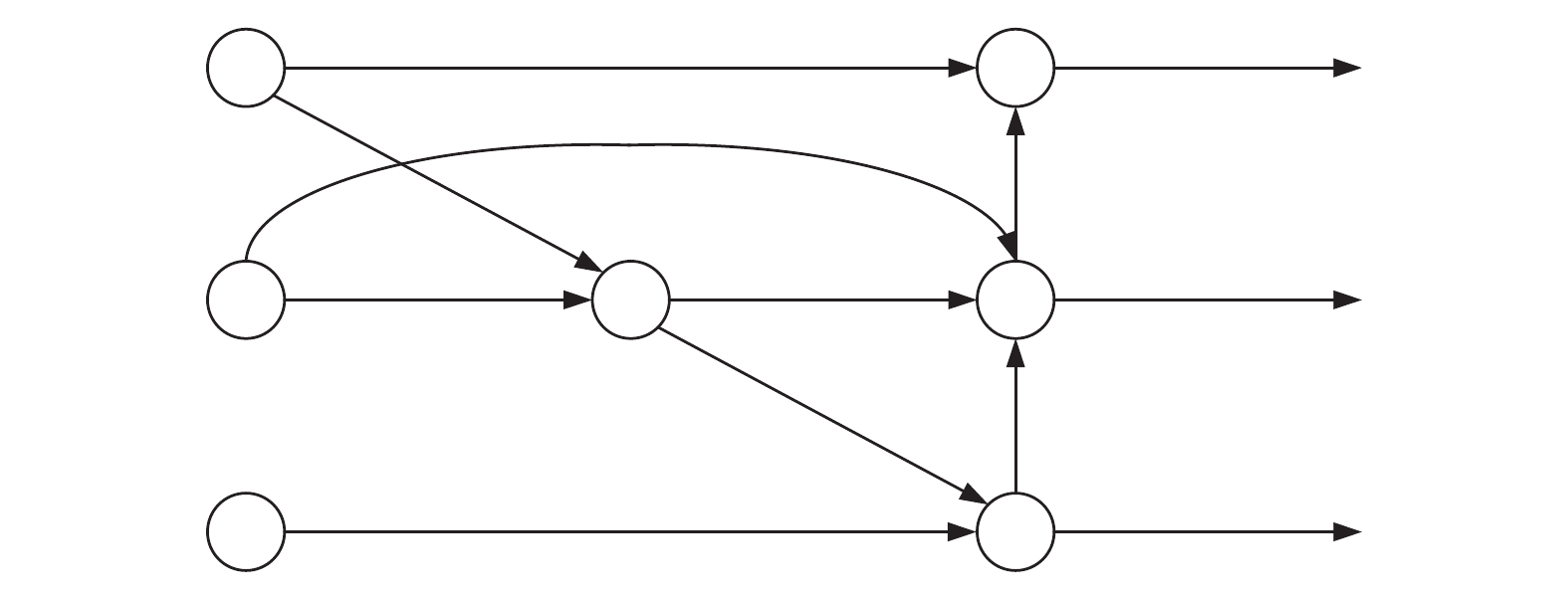
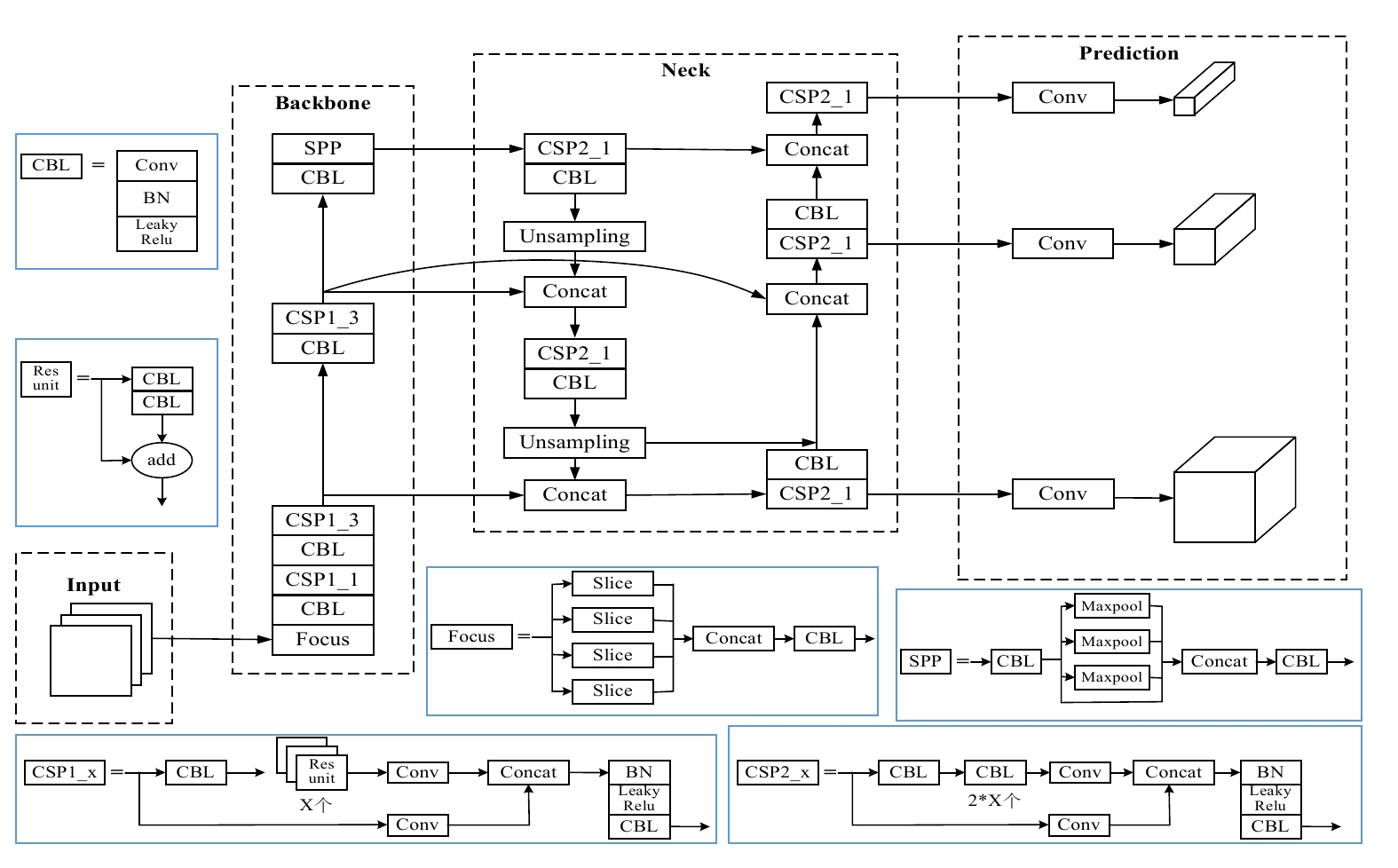
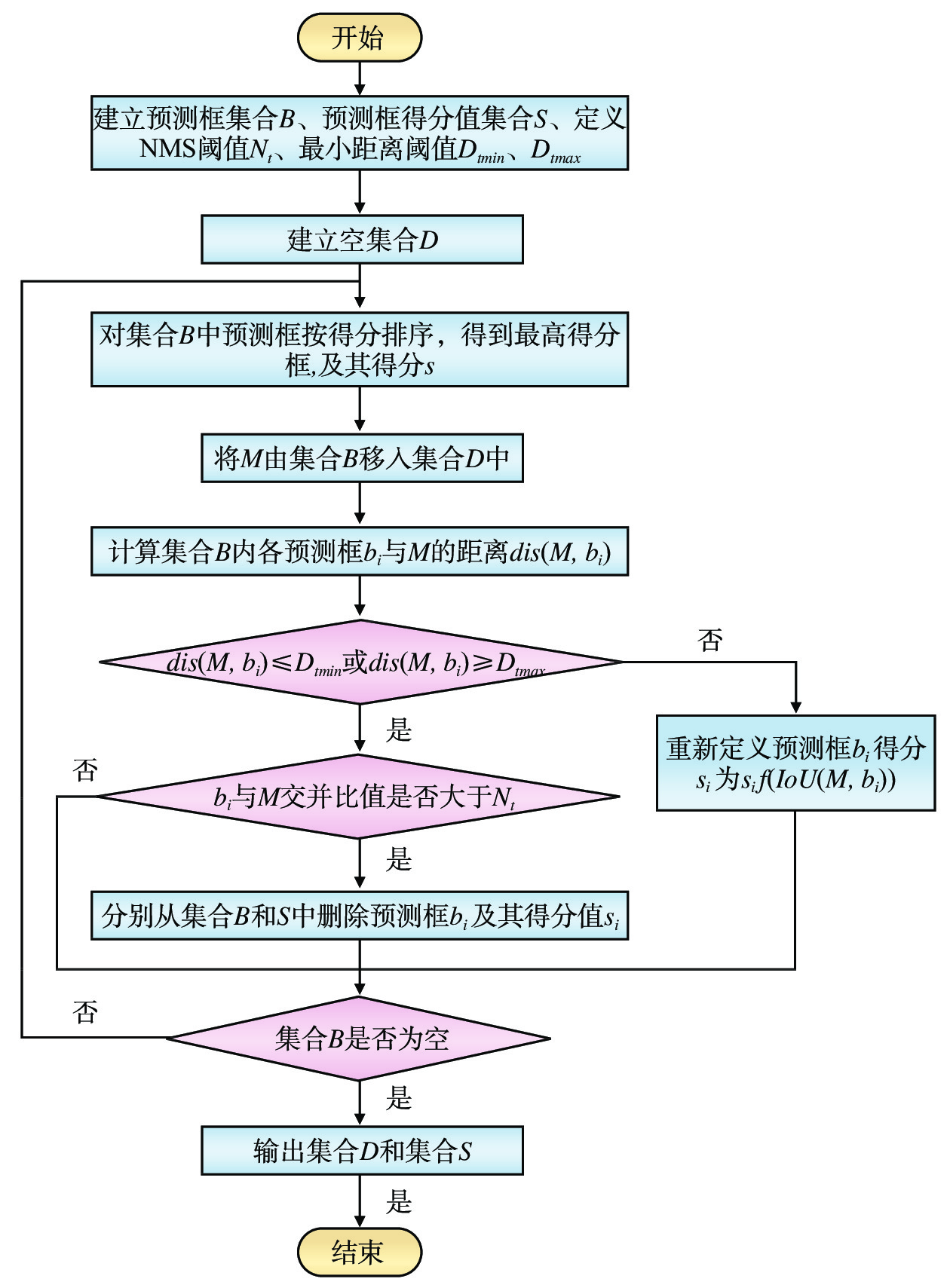
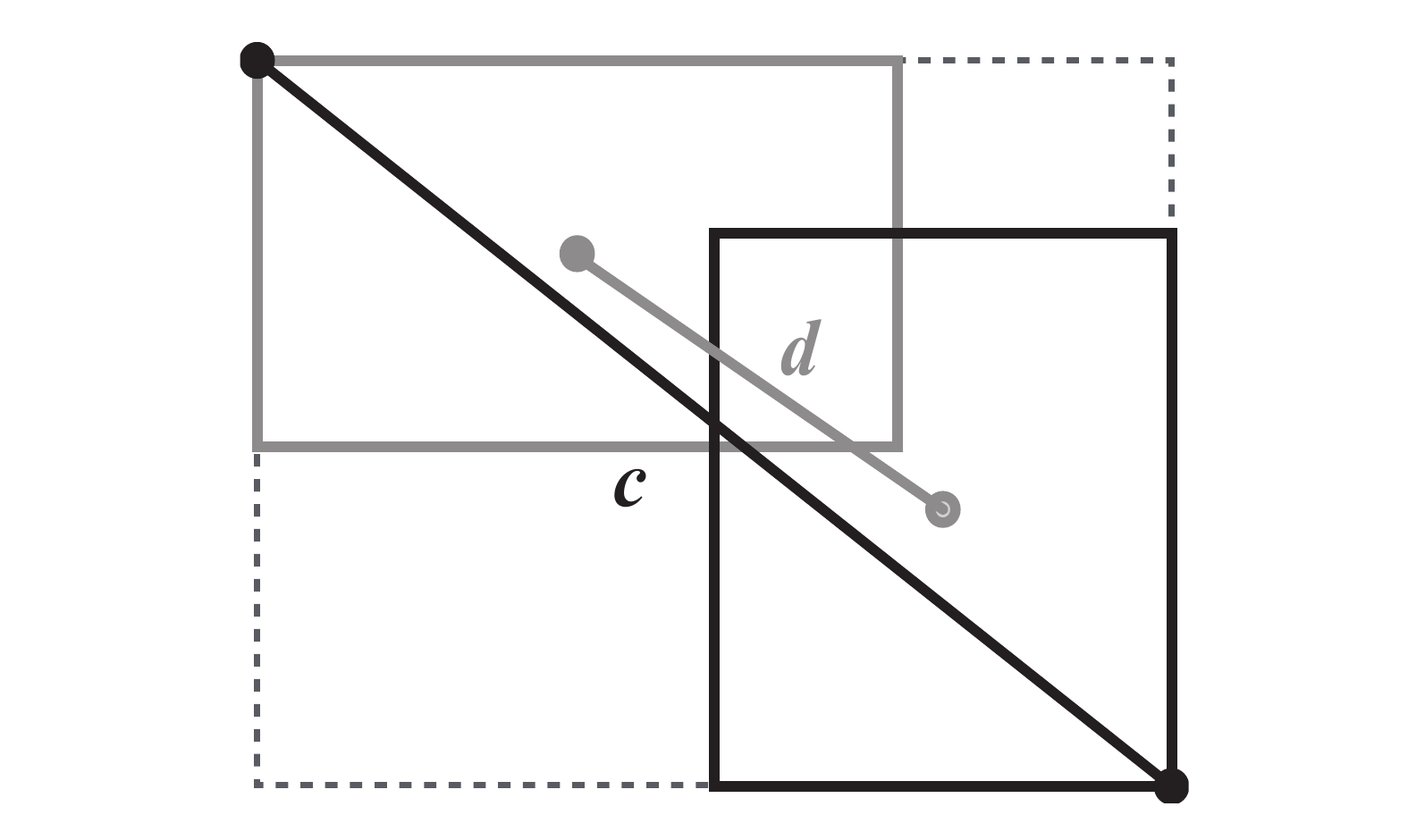
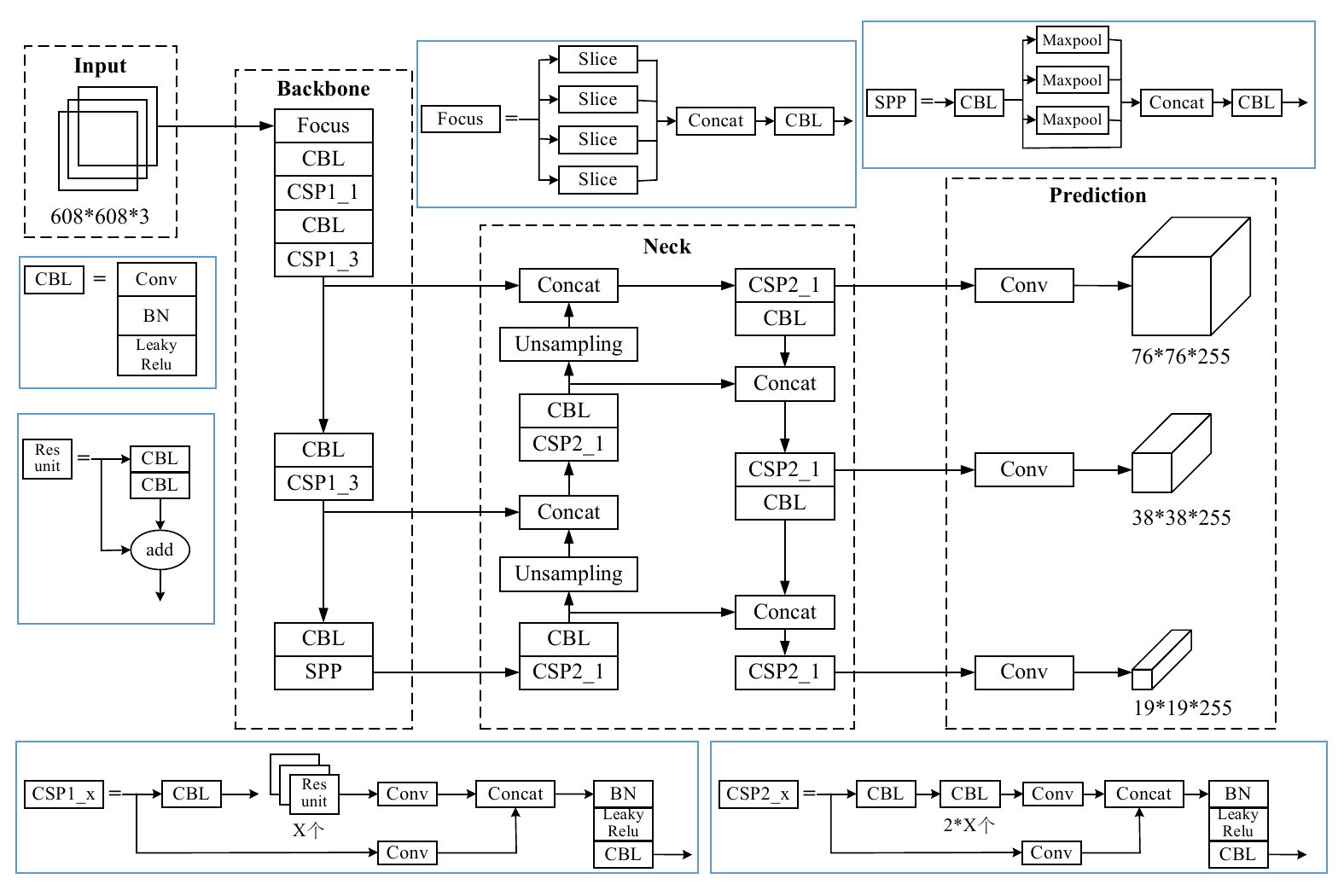
摘要: 针对城市轨道交通(简称:城轨)列车车厢客流密度检测过程中人群密集、乘客间相互遮挡的问题,文章提出一种基于改进YOLOv5s模型的列车车厢客流密度检测方法。设计了基于车载闭路电视监控(CCTV,Closed-Circuit Television)系统监控进行实时目标检测的列车车厢客流密度检测模型;为解决人群密集及遮挡问题,对YOLOv5s进行优化,采用了双向特征金字塔网络(BiFPN ,Bi-directional Feature Pyramid Network)结构加强网络特征融合,设计了一种损失函数计算方法,改进了非极大值抑制(NMS,Non-Maximum Suppression)方法,避免候选框误删除的情况。在标准行人检测数据集和自制地铁车厢乘客数据集上进行实验,结果表明,在两类数据集上,改进模型的检测精度均较原模型有所提升。Abstract: Aiming at the problem of crowded and serious mutual occlusion among passengers in the process of passenger flow density detection of urban rail transit train carriage, this paper proposed a passenger flow density detection method of train carriage based on improved YOLOv5s model, designed a detection model of passenger flow density in the train compartment based on CCTV (Closed Circuit Television) system monitoring for real-time target detection. In order to solve the problem of crowd density and occlusion, the paper optimized YOLOv5s, used BiFPN (Bi directional Feature Pyramid Network) structure to strengthen network feature fusion, designed a loss function calculation method, and improved NMS (Non Maximum Suppression) method to avoid the false deletion of candidate boxes. The paper conducted experiments on the standard pedestrian detection dataset and the self-made subway carriage passenger data set. The results show that the detection accuracy of the improved model is improved compared with the original model on the two types of datasets.
-
-
表 1 改进模型与原模型在CVC05数据集上的检测性能对比
模型 P R F1-Score AP50 AP50:5:95 原YOLOv5s 0.933 0.791 0.856 0.864 0.567 改进的YOLOv5s 0.930 0.802 0.861 0.892 0.614  下载: 导出CSV
下载: 导出CSV
表 2 改进模型与原模型在自制数据集上的检测性能对比
模型 P R F1-Score AP50 AP50:5:95 原YOLOV5s 0.965 0.951 0.958 0.967 0.468 改进的YOLOv5s 0.965 0.961 0.963 0.976 0.531
下载: 导出CSV
-
[1] 陈 影. 基于YOLOv5算法的道路场景目标检测应用研究 [J]. 现代计算机,2021,27(26):55-61. DOI: 10.3969/j.issn.1007-1423.2021.26.010 [2] 徐 静,邱慧芳,李庆来. 上海国家会展中心设施管理中的大数据分析探讨 [J]. 绿色建筑,2017,9(5):18-19, 22. DOI: 10.3969/j.issn.1004-1672.2017.05.007 [3] 孙乾宇,张振东. 基于YOLOv3增强模型融合的人流密度估计 [J]. 计算机系统应用,2021,30(4):271-276. DOI: 10.15888/j.cnki.csa.007915 [4] S. Ren, K. He, R. Girshick, et al. Faster r-cnn: towards real-time object detection with region proposal networks [J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137-1149.
[5] Liu Jiang, Gao Chenqiang, Meng Deyu, et al. DecideNet: Counting Varying Density Crowds Through Attention Guided Detection and Density Estimation.[C]// 2018 IEEE Conference on Computer Vision and Pattern Recognition, June 18-22, 2018, Salt Lake City, Utah, USA. New York, USA: IEEE, 2018, 5197-5206.
[6] T. Mingxing, P. Ruoming, L. Quoc. EfficientDet: scalable and efficient object detection[C]// 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 14-19, 2020. Seattle, WA, USA. New York, USA: IEEE, 2020: 10778-10787.
[7] W. Xinlong, T. Xiao, Y. Jiang, et al. Repulsion loss: detecting pedestrians in a crowd[C]// 2018 IEEE Conference on Computer Vision and Pattern Recognition, June 18-22, 2018, Salt Lake City, Utah, USA. New York, USA: IEEE, 2018, 7774-7783.
[8] B. Navaneeth, B. Singh, R. Chellappa, et al. Soft-NMS: Improving object detection with one line of code[C]// 2017 IEEE International Conference on Computer Vision (ICCV), October 24-27, 2017, Venice, Italy. New York, USA: IEEE, 2017: 5562-5570.
-
期刊类型引用(1)
1. 吕占民,李士达,戴琳琳,宋春晓,董兴芝. 基于AR智能眼镜的免打扰列车验票应用研究. 铁路计算机应用. 2023(05): 64-67 .  本站查看
本站查看
其他类型引用(0)


计量
- 文章访问数: 96
- HTML全文浏览量: 175
- PDF下载量: 38
- 被引次数: 1
