

An approach to select hardest sample set for intelligent detection in baggage security
-
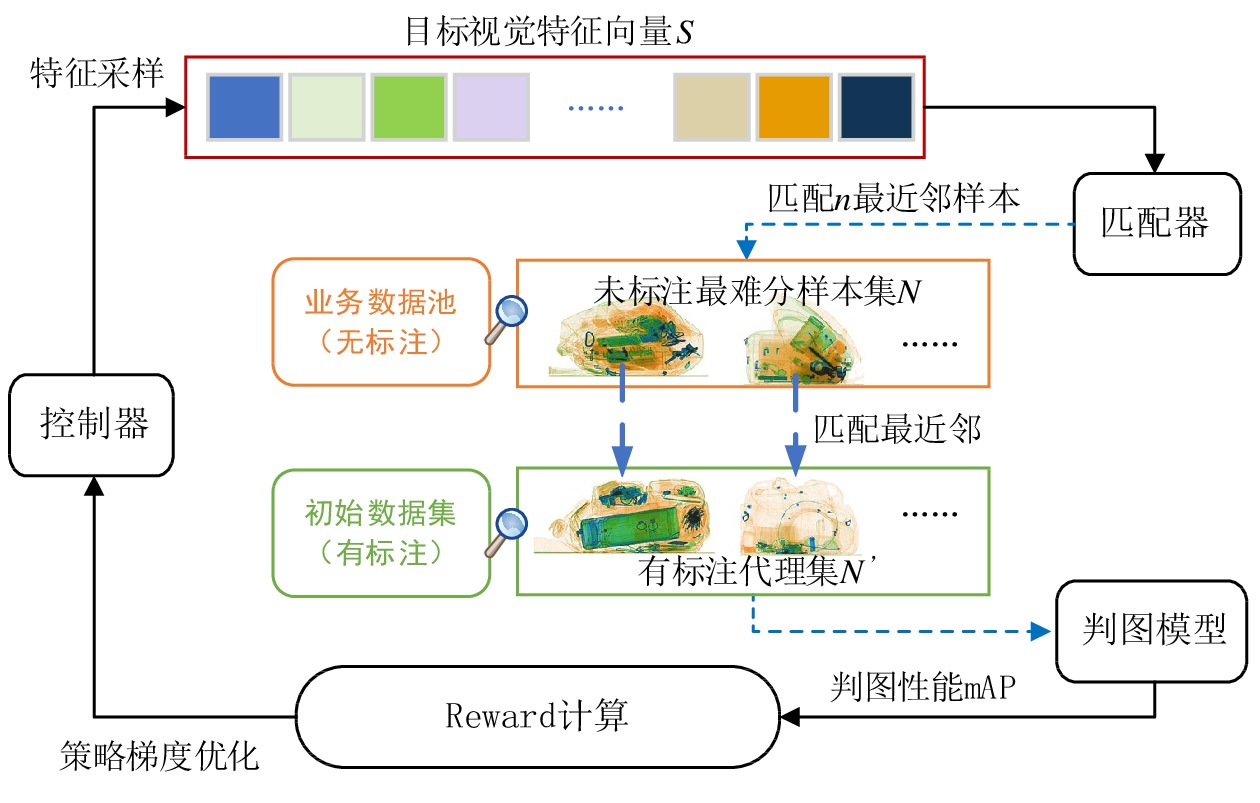
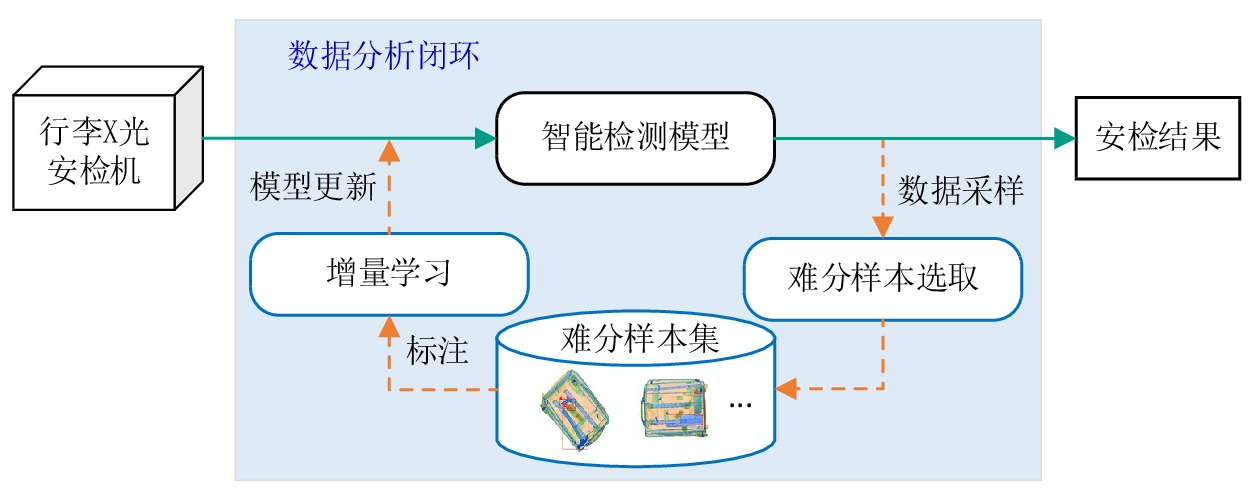
摘要: 研究表明,使业务模型性能变差的难分样本对系统边界决策能力增长有决定性影响。由于行李携带危险品的多样性及实物形态的不确定性,以及现场行李安检系统生成的行李X光图像数据呈现“长尾分布”特征,由有限次样本采集的数据集训练得到的智能检测模型,在应用于现场行李安检系统后,存在检测准确率不高的问题。文章针对行李安检智能检测数据分析闭环流程,提出最难分样本集的离散强化选取方法,可从现场行李安检系统运行过程中产生的危险品实例图像中选取最难分样本集,作为新增样本数据,用于智能检测模型的学习更新,实现安检智能检测软件性能的持续增强。Abstract: It is shown that hard samples worsening the performance of a system model has a decisive impact on the growth in the system's boundary decision capability. Due to the diversity of dangerous goods and the uncertainty of their instance forms as welll as the feature of "long-tail distribution" of the baggage X-ray image data generated by the on-site security system, the intelligent baggage detection model, which is trained based on the data set of finite sample collection, has the problem of low detection accuracy when applied to the on-site baggage security system. In this paper, we analyze the closed-loop data analysis process of the intelligent baggage security check, and propose a discrete reinforcement search method for selecting the hardest sample set from the X-ray images of dangerous goods instances generated during the operation of the baggage security system. Then, the hardest sample set is used as new training dataset to complete the learning update of the intelligent baggage detection model, thus realizing the continuous growth of the performance of the intelligent baggage security check software.
-
随着铁路信息化高速发展,大数据、云计算、虚拟化等技术广泛应用,铁路信息系统的规模和复杂度不断增长,运营维护(简称:运维)工作迫切需要从分散被动的传统运维向集中主动的智能运维转型[1-4]。配置管理数据库(CMDB ,Configuration Management Database)能够准确记录和描述组成生产系统的各个组件及其相互关系,是自动化、智能化运维体系的基石,可为全面掌握信息基础设施资源、实现运维操作自动化、异常告警精准化、变更风险管控、故障根本原因分析等提供基础数据支撑。
当前互联网、金融行业等已将CMDB定位为运维核心主数据,并围绕CMDB展开运维监控、服务管理、自动化运维等工作,积极推动运维数字化能力建设[5-7]。目前,铁路各运维单位配置管理水平参差不齐,大多数铁路局集团公司将配置管理数据作为静态数据管理,部分铁路局集团公司仍以手工录入和同步的方式来维护配置管理数据,导致配置数据较分散、数据标准不统一、自动化采集和路程关联能力不足等,难以为数字化运维提供有效支撑。
因此,亟需建设铁路配置管理系统,构建配置管理模型标准,建立中国国家铁路集团有限公司(简称:国铁集团)、铁路局集团公司两级信息系统配置库,实现全国铁路(简称:全路)信息技术基础设施、应用系统信息配置项及各配置项间关联关系的纳管,为信息基础设施的资源优化配置、实时运行监测、运维流程标准化、运维操作自动化提供技术支撑。
1 系统设计
1.1 总体架构
根据国铁集团、铁路局集团公司“两级管理、三级运维”的一体化运维体系架构,结合铁路信息系统运维工具现状[8-9],本文研究并设计了铁路配置管理系统总体架构,分为国铁集团级子系统和铁路局集团公司级子系统两个层级,可接收铁路大数据与人工智能平台的数据,并为运维调度和应急指挥中心及铁路短信平台等提供数据。铁路配置管理系统总体架构如图1所示。
(1)国铁集团级子系统汇总铁路局集团公司级配置数据和告警数据,基于配置库中台的权限服务和数据服务,提供模型管理、报表管理、告警管理等应用,实现全路物理资源、虚拟资源、软件资源及应用系统等对象的配置信息集中管理。同时,可对汇总数据进行统计分析,生成拓扑图和告警信息共享给国铁集团级运维调度和应急指挥中心,并通过铁路短信平台发送至应急调度和管理人员手机。
(2)铁路局集团公司级子系统基于配置库中台的集中采控、规则引擎、数据服务、流程规则等,提供模型管理、视图管理、关系管理、流程管理等配置库应用,对铁路局集团公司的物理资源、虚拟资源、软件资源及应用系统等对象的配置信息进行管理和分析,并将处理后的数据同步至国铁集团级子系统。同时,可通过大数据与人工智能平台,接入铁路信息装备资源管理系统等第三方系统的配置数据,将拓扑图和告警信息共享给铁路局集团公司级运维调度和应急指挥中心,并通过铁路短信平台发送至应急调度及管理人员手机。
1.2 技术架构
铁路配置管理系统遵循分布式、实时性、高并发、高可用和容灾能力强等原则,采用微服务架构,支持主流操作系统和国产化操作系统基础环境,支持系统快速弹性伸缩,避免传统架构造成的扩展局限。铁路配置管理系统技术架构如图2所示。
1.2.1 被管资源层
该层主要包含发现插件、采集插件和操作插件。发现插件能够对网域中的设备进行自动发现;采集插件用于采集设备的监控信息和其他信息等;操作插件负责对宿主机进行指定操作。
1.2.2 数据接入层
该层采用Nginx作为数据服务网关,对来自被管资源层的数据进行整合;使用Kafka作为数据缓存队列,处理高吞吐量的监控、告警、指标和事件数据流,构建实时数据通道和流应用。
1.2.3 数据服务层
该层使用ElasticSearch存储索引数据;使用非关系型数据库存储配置数据、拓扑数据、模型数据、标签数据、报表数据、关系数据、监控数据等;使用关系型数据库存储用户数据、日志数据、流程数据等;使用Redis存储热点数据,如CMDB目录缓存等;使用Spark对配置库系统中的大规模数据进行处理和分析;使用Mlib实现Spark上的机器学习算法处理大规模的数据集。
1.2.4 组件服务层
该层使用Esper作为规则引擎,实时分析高吞吐量的数据流,识别出特定的事件模式、关联、序列或统计异常等复杂事件,并进行处理;利用Activiti使流程能够被建模、自动化和监控,可通过图形化的流程设计工具定义流程;使用Echarts对配置数据进行可视化展示。
1.2.5 应用层
系统采用前后端分离的整体架构,前端页面采用React框架解耦前端对后端功能接口的依赖,保持页面整体良好的安全性;后端采用微服务的架构风格,基于Java语言,使用Spring Boot框架,各服务间通过RESTful API进行通信。
2 系统功能
根据铁路信息系统配置管理和运维管理要求,设计铁路配置管理系统功能,主要包括配置资源纳管、配置资源仓库、配置资源拓扑、配置资源运用、配置管理和系统管理等,实现对全路物理资源、虚拟资源、软件资源及应用系统等配置信息的集中管理。铁路配置管理系统功能架构如图3所示。
2.1 配置资源纳管
2.1.1 信息采集监测
该功能主要包括配置信息自动采集、数据信息实时监测,可自动扫描网络设备信息,跟踪数据变化情况,实现纳管资源的自动新增和实时更新等。支持按照不同类型的配置模型标准获取配置数据信息、资源使用状态信息和资源告警信息等,同时,支持以列表的形式展示全部纳管资源。
2.1.2 配置监测管理
支持监测对象模板设置和监测策略设置,可设置监测对象、监控指标和告警阈值规则,针对不同类型的资源对象,进行监测策略关联配置,对纳管资源进行本地、远程监测。
2.2 配置资源仓库管理
2.2.1 资源仓库管理
包括当前所有配置数据,支持对各类型配置数据信息进行汇总和分类管理,主要包括资源清单、关联关系、模板清单、类型属性等内容。支持配置数据的录入、导入、查询、修改、删除等操作,并通过树形目录分层显示当前配置列表。
2.2.2 应用资源管理
应用资源对铁路车务、机务、工务、电务、供电等领域、多个一级系统、铁路局集团公司其他系统进行汇总和分类管理,主要包括系统名称、编号和类型,以及各类型资源关联关系等。支持创建、编辑、删除应用和应用详情查看,支持应用关联拓扑绘制和创建部署图。
2.2.3 资源地图展示
资源地图用于汇总配置管理库中核心配置模板的关系,按业务应用层、平台资源层、虚拟资源层、物理资源层、基础设施层从上至下对各配置项间的模板关系进行分层展示,可对展示模板进行添加和删除。支持全局搜索配置资源,建立快捷入口,方便下次查询相同的资源。
2.3 配置资源拓扑管理
2.3.1 我的拓扑管理
资源拓扑以应用为视角,用图形化界面呈现应用系统关联配置信息,主要包括服务器、网络设备、应用程序、服务依赖关系等。支持用户新建应用拓扑图,挖掘资源仓库中配置项关系,实现拓扑图自动绘制,并以列表形式展示拓扑名称、创建时间、更新时间、创建者、拓扑类型(自由架构或关系拓扑)、状态和操作等信息。
2.3.2 资源拓扑展示
拓扑广场用于展示其他用户发布的应用拓扑信息,支持以列表的形式展示已发布的应用拓扑图,用户可查看拓扑结构,查询应用的设备信息和设备间关系。同时,支持预定义的布局和元素拓扑模板,用户可快速绘制拓扑图。
2.4 配置资源运用
2.4.1 资源统计展示
主要对纳管的配置数据进行全方位、多维度的统计和展示,包括配置仓库当前配置总数、数据变化、配置自动化覆盖率、配置入库和分派的情况、配置资源使用情况、配置类型和关系等。
2.4.2 配置资源总览
应用全景图以列表或图形的方式展示各重要应用和各应用详情。主要包括应用的主机数、数据库数量、中间件数量、应用模块数量和告警数量等。支持查看应用在各铁路局集团公司的部署情况、设备和告警概览等信息,并可通过地图形式展示。同时,支持以图形化和报表的形式展示各铁路局集团公司的配置信息,汇总应用数量、拓扑总量、主机总量、中间件总量和数据库总量等信息,实现配置资源统计、配置完整性情况统计和资源统计排名等功能。
2.5 资源管理
2.5.1 模型管理
用于设计、构建、维护和优化CMDB中的配置项模型,支持自定义模型结构、属性、类型和各类型模型间的关系,并可以图形化的方式展示各配置类型之间的关系。
2.5.2 资源组管理
资源组基本信息主要包括名称、配置项维护人、配置项查看人、配置认领信息、自动认领的时间周期和认领规则等。该功能支持资源组分类管理,以及资源组创建、编辑、删除和详情查看等。
2.6 系统管理
系统管理功能包括用户管理、权限管理和日志管理等,为铁路配置管理系统的运行和管理提供辅助支撑。
3 关键技术
3.1 配置模型设计
配置模型设计是铁路配置管理系统的核心,可保障配置项的标准化、一致性和可追溯性。文本采用“面向应用”的分层设计思想,将配置模型划分为业务应用层、平台资源层、虚拟资源层、物理资源层和基础设施层。其中,业务应用层包含业务应用系统、规划目录、业务领域等;平台资源层包含操作系统、数据库、中间件等;虚拟资源层包含虚拟机和云平台等;物理资源层包含计算设备、网络设备、存储设备等;基础设施层包含不间断电源(UPS,Uninterruptible Power Supply)、配电柜、机柜和机房等。配置模型层次架构和关联关系如图4所示。
在资源层的基础上,对现有铁路信息系统资源进行分类整理,梳理资源关注的配置项,形成配置项层级分类表、配置项名称命名规则、关联关系及状态定义、配置项关联关系矩阵、各分类属性详情表等,构建全路配置模型标准23类180个。
3.2 配置数据自动化采集
为主动发现各类信息系统资源的配置信息与关系,自动化跟踪变更前后数据,本文通过网络资源扫描、配置深度发现等自动化采集技术对信息系统环境进行全面扫描,识别硬件、软件和相关文档,形成配置项信息,分配唯一标识符,创建配置项关联关系,自动化跟踪变更前后数据变化,保障数据鲜活度。同时,采用Agent和Agentless两种发现方式,实现纵向和横向的双向扩展识别[10-11]。
此外,文本研究了基于OpenTelemetry技术的分布式应用链路配置关系自动发现方法,通过在被管微服务应用的各个节点部署探针,采用自动插桩实现的方式自动发现服务间的调用关系[12-13],并对日志信息进行解析,快速生成应用配置关系,实现分布式应用链路配置的关系自动发现。
3.3 配置数据处理
配置数据处理包括数据清洗、数据集成、数据挖掘等。本文通过插值法、哈希函数、Isolation Forest等方法处理数据缺失、数据重复、数据异常等问题,实现对配置数据的清洗;采用ETL技术从不同数据源提取数据,进行格式转换并加载到目标数据仓库中,实现多个数据源的数据集成;通过K-means聚类分析、Apriori关联规则分析实现配置数据整合和关联关系处理。
此外,本文通过统计分析算法、时间序列分析算法、机器学习算法等,对配置项数量、类型分布、更新频率进行统计分析,帮助运维人员掌握系统配置的整体情况和变化趋势;通过监测CPU、内存、磁盘等资源的使用情况,结合配置项间的依赖关系,分析系统运行状态和资源使用情况,为资源配置优化和故障隐患排查提供支撑和帮助。
4 系统应用
本文基于B/S架构和当前主流的前后端分离开发框架,采用瀑布及Scurm的混合开发模式,以及分布式部署模式进行研发,在国铁集团和中国铁路西安、沈阳、太原等6个铁路局集团公司进行两级部署验证。铁路配置管理系统的应用,帮助国铁集团和各铁路局集团公司全面掌握信息系统资源信息,快速了解应用部署和资源关联关系,同时为日常监控告警处置、故障排查定位、配置变更及风险分析、资源统一调度和统一指挥等提供完整的数据支撑。该系统应用效果如图5所示。
5 结束语
本文针对铁路信息系统配置数据分散、标准不统一等问题,设计了铁路配置管理系统,开展配置模型设计,研究配置数据采集和配置数据处理等技术,实现了配置资源纳管、统计展示和挂图作战,并在国铁集团和试点铁路局集团公司部署验证,应用效果良好。下一步,将深入开展配置数据的综合运用和基础数据融合等研究,进一步优化完善铁路配置管理系统功能,积极开展全路推广应用,不断提升铁路信息系统运维的智能化水平。
-
表 1 测试数据集各类危险品数目
(单位:张) 类别 电池 瓶子 锤斧 刀 剪刀 样本总体 初始训练集 530 4157 1346 5437 3301 6819 测试集A 130 1090 342 1365 834 1704 测试集B 369 450 1702 2008 1020 1704  下载: 导出CSV
下载: 导出CSV
-





计量
- 文章访问数: 149
- HTML全文浏览量: 90
- PDF下载量: 36
