

Application failure prediction method of cloud data center based on GRU Recurrent Neural Network
-
摘要: 云数据中心的分布式应用故障具有复杂性、随机性等特点,导致应用的运行与维护(简称:运维)管理任务难度大、效率低。为此,提出一种云数据中心应用故障预测方法,构建基于门控循环单元(GRU,Gated Recurrent Unit)循环神经网络(RNN,Recurrent Neural Network)的云数据中心应用故障预测模型,对云数据中心的应用监控数据进行分析处理并预测将要出现的应用故障。试验结果表明,本方法预测精确率满足应用运维管理中故障提前发现和处理的相关要求,在降低应用运维管理难度和提升运维效率方面具有一定的实用价值。
-
关键词:
- 云数据中心 /
- 循环神经网络(RNN) /
- 特征工程 /
- 门控循环单元(GRU) /
- 故障预测 /
- 单层感知器(SLP)
Abstract: Distributed application failures in cloud data centers have the characteristics of complexity, randomness, which make applications operation and maintenance tasks difficult and inefficient. Therefore, this paper proposed an application failure prediction method for cloud data center, built an application fault prediction model of a cloud data center based on GRU (Gated Recurrent Unit) Recurrent Neural Network (RNN), analyzed and processed the application monitoring data of the cloud data center and predicted the application failures that will occur. The test results showed that the prediction accuracy of this method meets the relevant requirements of failure early detection and treatment in application operation and maintenance management, and has certain practical value in reducing the difficulty of application operation and maintenance management and improving operation and maintenance efficiency. -
中国国家铁路集团有限公司(简称:国铁集团)在2018年建成铁路主数据中心并投入使用。该中心支撑的应用超过350项,采用新一代云架构体系,容纳服务器设备数量达数万台。因此,对铁路主数据中心运维管理工作提出了更高的要求。铁路主数据中心运行与维护(简称:运维)管理工作是该中心各项业务应用平稳可靠、安全高效的重要支撑[1]。传统的应用故障监控方式只能在故障发生后,由运维人员根据故障现象逐层溯源排查,难以在短时间内精准定位故障,导致故障修复时间较长、影响范围和程度不能及时有效控制 [2]。在云架构体系下,如果仍旧依靠传统的运维方式,将使运维成本大幅增加,但运维效果却难达预期,如果能提前预测未来可能发生的故障,运维人员就可在故障发生前进行定点排查,提前采取应对措施,避免故障发生后导致的损失,因此推动铁路主数据中心智能化运维已成为必然趋势[3],运维结合人工智能和深度学习技术,能有效提升云数据中心智能化水平和运维效率 [4]。
近年来,不少学者针对数据中心故障预测技术进行了相关研究,如采用决策树算法和反向传播(BP,Back Propagation)神经网络进行故障预测[5];基于Adaboost算法的BP神经网络故障预测模型进行故障预测[6];基于加权中值的故障检测方法[7]。这些算法在一定程度上提高了模型预测的精确率,但从试验效果上看,还存在计算算力需求偏大、参数调整复杂、预测结果精确率难以满足实用性要求等问题。因此,有必要针对铁路主数据中心应用场景开展相关研究。
当前,铁路主数据中心对故障监控采取阈值检测报警机制,按CPU、内存、磁盘使用率等指标值是否超过预设的阈值进行预警,采取后报警机制。而该中心中应用种类繁多,固定阈值告警方式不能适用于全部应用。本文通过对应用的CPU、内存和磁盘监控数据进行研究,发现部分应用故障的出现并非突然发生,而是在状态恶化持续一段时间后才发生,此外,部分应用的同类故障多次出现时,其各类监控数据表现出一定的特征性和相关性。因此,本文提出一种改进的循环神经网络模型,通过特征工程和单层感知器(SLP,Single layer Perceptron)对应用故障进行预测,在报警阈值到达前发出预警信息,提前处理可能要发生的故障,避免因应用故障导致的损失,为运维人员提供更充裕的处理时间。
1 相关技术
1.1 特征工程
特征工程是根据要解决的业务问题,从原始数据中提取更多信息的过程,其目的是最大限度地从原始数据中提取特征,以供算法和模型使用。在机器学习的流程中,特征是数据和模型间的关键纽带,选取合适的特征可减轻模型构建难度,输出更高质量的模型[8-9],通常,特征工程包括特征构建、特征提取、特征选择3部分。
1.2 循环神经网络
神经网络具有良好的非线性拟合能力及较强的学习能力,为复杂应用场景提供了有效的理论基础。基于神经网络,既可通过设备故障特征诊断是否将会发生故障,也可通过学习来完善故障诊断知识库。目前,神经网络在设备故障领域的应用研究已成为热点[10-12]。
循环神经网络(RNN ,Recurrent Neural Network)作为深度学习的经典算法之一,可提取前后元素间的关联信息,多用来处理时序数据,被业界称为时序利器。在自然语言处理领域,RNN通过前后项间的时序信息理解文本含义,可实现机器翻译、阅读理解等[13]。在语音信号处理领域,也可通过RNN实现语音处理和语音识别
大规模云数据中心的监控数据按时间序列记录,这些数据在时间顺序上的变化能被循环神经网络捕捉并学习数据随时间变化的复杂非线性关系,从而实现故障预测[14]。
1.3 门控循环单元
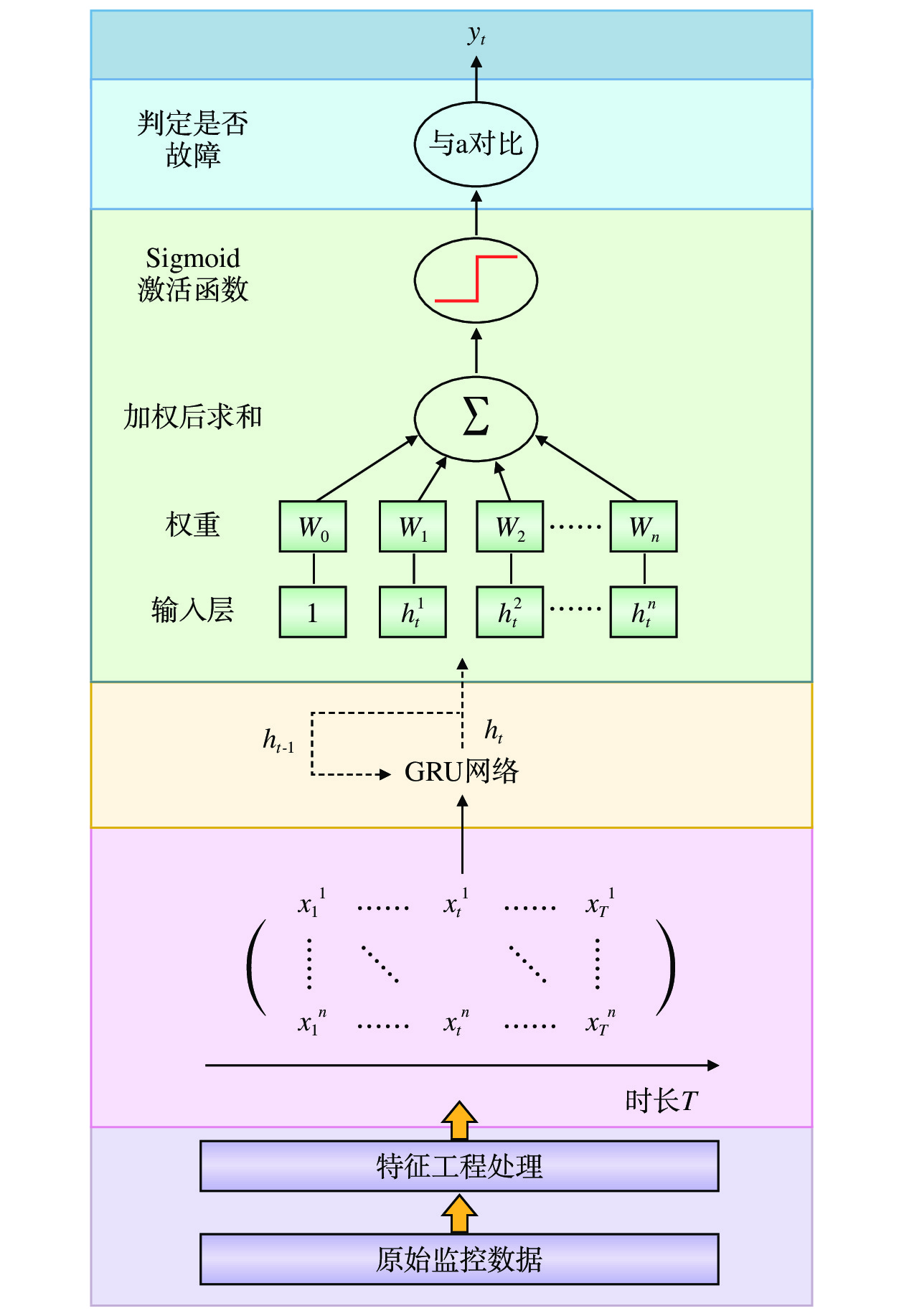
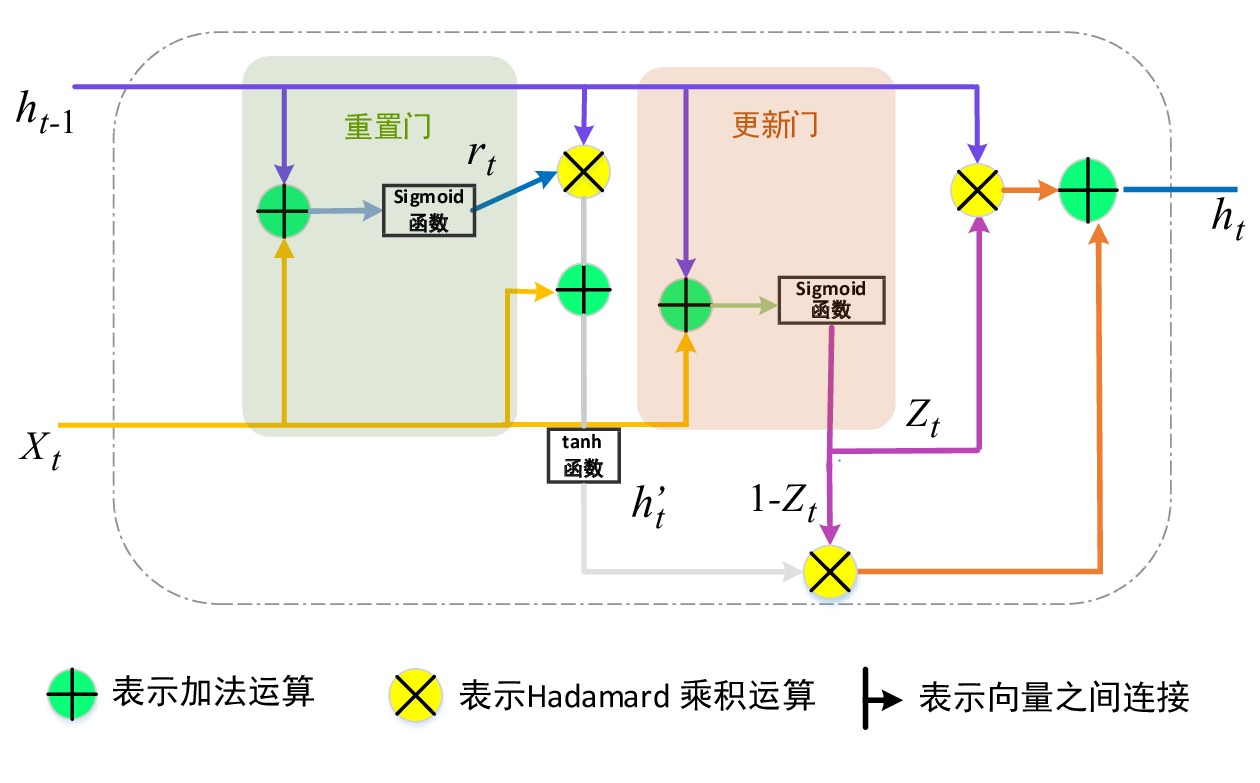
在RNN模型的实际应用中,研究者发现,此类模型存在难以处理信息长期依赖(Long-Term Dependency)的缺陷,而基于门控循环单元(GRU ,Gated Recurrent Unit)和长短期记忆(LSTM ,Long Short Term Memory)的RNN模型可弥补此缺陷。GRU和LSTM原理类似,但GRU采用更少的参数,更快的模型训练速度,即可达到相近的训练效果[15]。基于GRU的RNN(简称:GRU网络)采用门控机制,其神经元基本结构[16]如图1所示。
从图1可看出,GRU由两个门构成,分别为重置门和更新门。GRU网络的数学公式如下:
zt=Sigmoid(Wzxt+Vzht−1+bz) (1) rt=Sigmoid(Wrxt+Vrht−1+br) (2) h′t=tanh(Wxxt+Vx(rt⊙ht−1)+bx) (3) ht=zt⊙ht−1+(1−zt)⊙h′t (4) 其中,
zt 表示t时刻的更新门;rt 表示t时刻的重置门;xt 表示t时刻输入向量;h′t 表示中间隐层状态;Wx、Wz、Wr 表示t时刻输入向量的权重矩阵,Vx、 Vz、Vr 表示t−1时刻隐层状态的权重矩阵,bx、bz、br 分别表示中间隐层、更新门、重置门t时刻的偏置项,这些权重矩阵和偏置项都是优化学习的参数,⊙ 表示点乘关系。结合图1和公式(1)~(4)可知,相比LSTM网络,GRU网络减少一个输出控制,每个单元的输出是其时序传递的单元状态。GRU流程为:(1)从上一个时序单元输入一个
ht−1 ,通过重置门后,与当前的输入xt 结合;(2)经过tanh函数激活处理,形成一个新的中间隐层状态h′t; (3)更新门控制h′t 与ht−1 以相应的比例进行重组,形成当前时刻的输出ht 。1.4 单层感知器
SLP是一种基于阈值传递函数的前馈网络,其神经元局部记忆的内容由一个权重向量组成,是人工神经网络中的基础类型,能处理二分类问题。单层感知器将输入向量与权重向量相乘求和,然后利用激活函数获得输出结果。
故障预测的结果为故障或非故障,是一个二分类问题,因Sigmoid函数可以将任一实数映射到(0,1)区间,可用来做二分类,故本文选择Sigmoid函数作为SLP的激活函数,并设定一个阈值,Sigmoid函数的输出值大于此阈值则标签为1,表示故障,否则标签为0,表示非故障。
2 应用故障预测
2.1 模型数据
本文使用云数据中心仿真环境中的应用进程(简称:进程)监控数据,对应用进行故障预测。该数据集的信息包括:
(1)在监控数据的时间跨度内,共有59类应用,2 013个进程,选取其中102个出现过故障的进程监控数据作为试验数据。
(2)监控数据包含应用所在服务器的CPU使用率、CPU等待I/O时间百分比、内存使用率、磁盘读写操作次数每秒(IOPS,Input/Output Operation Per Second)、进程的响应时间、网络连接数、CPU使用率、内存使用率,共8个特征。
(3)监控数据时间跨度为2020-07-01 00:00~2021-01-12 23:55,共28个星期,数据粒度为5 min。
通过对数据进行分析,发现每次应用发生故障前,在一段时间内,监控指标具有一定上升或下降趋势。本文对具备此类特征的进程监控数据进行建模和训练,构建基于GRU循环神经网络的云数据中心应用故障预测模型(简称:模型),将单个进程监控数据的前80%作为训练数据,剩余20%作为测试数据。
通过特征工程对原始监控数据进行预处理,包括数据的冗余清洗、特征提取、缺失值处理、无量纲化等,其中,特征值筛选采取嵌入法中基于惩罚项的特征选择和专家判断相结合的方法,对数据的无量纲化处理采用Z-score标准化方法,以时间序列
x1 ,x2 ,···,xn 为例,n为特征值总数,Z-score标准化计算公式为:yi=xi−¯xS (5) ¯x=1nn∑i−1xi (6) S=√1n−1n∑i−1(xi−¯x)2 (7) 则新序列的y1,y2,···,yn均值为0,标准差为1。
2.2 模型实现过程
模型实现过程如图2所示,其中,
yt为 判断故障标签;a为设定的故障阈值;w0 ~wn 代表权重矩阵;h1t ~hnt 代表t时刻n个特征的隐层状态(即网络层的输出); T代表训练数据时长;xnt 代表t时刻第n个特征的值。主要步骤如下。(1)对监控数据中存在错误或缺失的数据进行特征工程处理,用此点相邻的部分点均值进行替换或补充,对磁盘IOPS、进程的响应时间、网络连接数等进行归一化处理。
(2)GRU网络输入的单个进程的8个特征数据为:CPU使用率(x1);内存使用率(x2);CPU等待I/O时间百分比(x3);CPU使用率(x4);内存使用率(x5);归一化后的网络连接数(x6);归一化后的响应时间(x7);归一化后的磁盘IOPS(x8)。
(3)利用选取的数据进行模型训练,根据模型测试的精确率进行参数调整及激活函数选定,从而确定GRU模型。
(4)使用和(3)相同的训练数据和测试数据,根据模型测试的精确率和覆盖率确定SLP的参数,训练出单个进程的SLP模型。
(5)利用(3)中训练得到的模型,预测单个进程未来一段时间的监控数据,通过(4)的SLP模型,得出单个进程发生故障的概率,并与此进程设定的阈值进行比较,判定进程是否故障。
2.3 参数设定
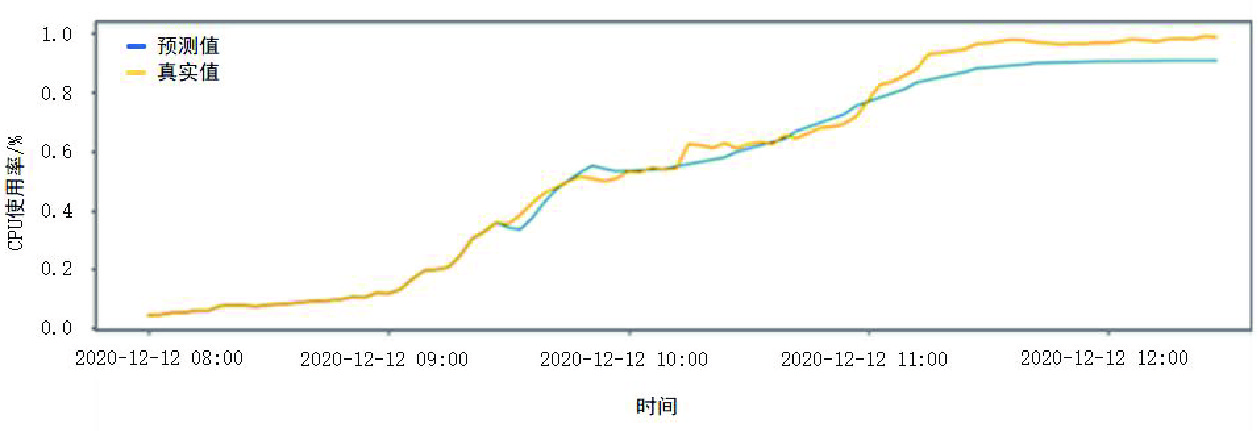
模型的训练调参阶段,通过对不同迭代次数(Epoch)和不同批处理(Batch_size)大小设定值的多次测试,确定当Epoch=20,Batch_size=2时,模型效果较好。基于该参数设定,某进程的CPU预测使用率和实际情况如图3所示。该进程CPU的预测使用率和真实使用率差值较小,趋势基本吻合,表明本文采用的方法对故障预测具有较高的精确性。
3 结束语
针对铁路云数据中心应用运维管理中面临的故障复杂性和随机性问题,提出一种基于GRU循环神经网络和SLP相结合的应用故障预测方法。本方法可对服务器和应用进程的监控数据进行特征工程处理,从原始数据中提取必要特征供算法模型使用,能较快获得高精确率的预测数据,提高判定进程故障的精确率。通过试验数据和仿真分析结果,验证了本方法的实用性。
-
[1] 施卫忠. 铁路数据中心建设与规划研究 [J]. 中国铁路,2020(1):1-2. [2] 凌 政,安 藤. AIOps平台建设和实践 [J]. 网络安全和信化,2020,46(2):70-71. [3] 覃进学. 基于AIoT+AIOps的数据中心智能化运维实现探讨 [J]. 数字通信世界,2020,182(2):115. DOI: 10.3969/J.ISSN.1672-7274.2020.02.083 [4] 范清栋,吴旭东,宁建创,等. 浅析人工智能在网络运维中的应用 [J]. 电脑与电信,2019(9):43-45,55. [5] 贾宇晗,李 静,贾润莹,等. 硬盘故障预测模型在大型数据中心环境下的验证 [J]. 计算机研究与发展,2015,52(S2):54-61. [6] 贾润莹,李 静,王 刚,等. 基于Adaboost和遗传算法的硬盘故障预测模型优化及选择 [J]. 计算机研究与发展,2014(S1):148-154. [7] 高建良,徐勇军,李晓维. 基于加权中值的分布式传感器网络故障检测 [J]. 软件学报,2007,18(5):1208-1217. [8] 王 成,王昌琪. 一种面向网络支付反欺诈的自动化特征工程方法 [J]. 计算机学报,2020(10):1986-1987. [9] 张超标,孙延明. 特征工程和深度前馈网络结合的刀具磨损预测 [J]. 机械设计与制造,2020,352(6):197-200. [10] 陆 航,杨涛存,刘 洋,等. 基于LSTM的动车组故障率预测模型 [J]. 中国铁路,2020(7):61-65. [11] 王明哲,张 研,杨 栋,等. 基于深度学习的车站旅客密度检测研究 [J]. 中国铁路,2019(11):13-17. [12] Yan-hua CHEN, Jian-nan LI, Kai LIAN, Qing-jie ZHU, Yi-liang LIU. Failure Prediction of Underground Pipeline Based on Artificial Neural Network[A]. Science and Engineering Research Center. Proceedings of 2017 2nd International Conference on Artificial Intelligence: Techniques and Applications (AITA 2017)[C]. Science and Engineering Research Center: Science and Engineering Research Center, 2017.
[13] Greff K, Srivastava RK, Koutník J, et al. LSTM: A search space odyssey [J]. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(10): 2222-2232. DOI: 10.1109/TNNLS.2016.2582924
[14] Bari M F, Boutaba R, Esteves, et al. Data center network virtualization: A survey [J]. IEEE Communications Surveys & Tutorials, 2013, 15(2): 909-928.
[15] 林靖皓,秦亮曦,苏永秀,等. 基于自注意力机制的双向门控循环单元和卷积神经网络的芒果产量预测 [J]. 计算机应用,2020(S1):51-55. [16] Gaurav Singhal. LSTM versus GRU Units in RNN[EB/OL]. [2021-07-07]. https://www.pluralsight.com/guides/lstm-versus-gru-units-in-rnn.
-
期刊类型引用(6)
1. 皮魏. 城市轨道交通车辆智能运维系统信息安全技术方案. 城市轨道交通研究. 2024(06): 281-285 .  百度学术
百度学术
2. 樊玉明,刘琦,咸晓雨,王剑. 基于区块链+北斗的铁路装备可信数字身份服务方法. 导航定位与授时. 2023(04): 48-57 . 百度学术
3. 司群,魏长水,王震华. 新时期铁路网络空间安全防御技术架构研究. 铁路计算机应用. 2023(11): 20-24 . 本站查看
4. 孙鹏,张惟皎. 铁路物联网系统的安全挑战与对策研究. 铁路计算机应用. 2022(10): 62-67 . 本站查看
5. 焦雄风,马龙,金卫峰,陈铮,张献州. 运营高铁重点监测地段云评估系统设计与实现. 铁道勘察. 2021(04): 43-47 . 百度学术
6. 王朋成. 电铁牵引变电所内部数据传输网络安全防护研究. 电气化铁道. 2020(S2): 66-68 . 百度学术
其他类型引用(2)
 下载:
下载:



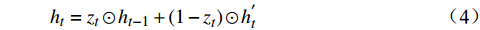


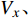

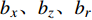

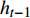
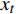

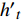
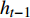
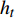
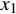




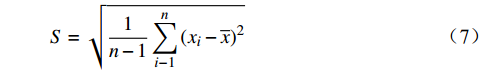

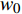
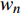

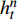

计量
- 文章访问数: 152
- HTML全文浏览量: 269
- PDF下载量: 41
- 被引次数: 8
