

Design of railway data sharing platform based on Greenplum
-
摘要:
实现铁路既有信息系统数据共享,加快数据集成应用开发,是我国铁路信息化建设继续深入推进的必由之路。文章针对铁路企业既有数据资产来源广、数据源类型多种多样等特点,基于分布式数据仓库Greenplum,开发了适用于集中存储和管理铁路企业多源异构数据的数据共享平台。平台提供数据目录管理、数据采集、数据共享、运行监控管理与数据安全防护等功能,实现对铁路多源异构数据的自动采集、处理及规范化集中存储。平台采用高可靠、易扩展的架构设计及可视化技术,为平台管理员提供简便易用的可视化配置与运行管理工具,为铁路企业应用开发单位提供便捷高效、稳定可靠、安全合规的数据共享服务,较好地满足铁路企业数据集成应用开发的需要,也为铁路企业大数据应用构建起坚实的基座。该平台已在中国铁路兰州局集团有限公司启动试运行,创建了企业既有信息系统数据资产目录,已采集76种业务数据,为十多个信息系统提供稳定、高效的数据共享服务。
Abstract:Realizing data sharing of existing railway information systems and accelerating the development of data integration applications is an effective way for pushing forward China's railway informationization construction. To deal with a wide range of and diverse types of data sources of railway enterprise's existing data asset, a data sharing platform suitable for centralized storage and management of railway enterprise multi-source heterogeneous data is developed based on the distributed data warehouse Greenplum. The platform provides functions such as data directory management, data collection, data sharing, operation monitoring management, and data security protection, realizing automatic collection, processing, and centralized storage of railway multi-source heterogeneous data. The platform adopts a highly reliable and scalable architecture design and visualization technology, providing platform administrators with convenient and easy-to-use visualization configuration and operation management tools, and providing convenient, efficient, stable, reliable, safe and compliant data sharing services for railway enterprise application developers. It better meets the needs of railway enterprise data integration application development and also builds a solid foundation for railway enterprise big data applications. The platform started trial operation in China Railway Lanzhou Group Co. Ltd., establishing a complete data asset catalog of existing information systems. It has collected 76 types of business data and provided stable and efficient data sharing services for more than ten information systems.
-
随着信息化进入云计算时代,铁路信息系统由第三代际向第四代际演进,对应用系统开发效率和资产复用等方面提出更高要求[1]。“十四五”铁路网络安全和信息化规划中提出,要加强一体化信息平台建设,优化集成服务平台,构建业务和技术中台,提升应用开发效率和管控水平[2]。
我国铁路历经数十年持续的信息化建设,在运输组织、调度指挥、客货营销、办公综合、工程建设等各领域已经开发和应用了大量的信息系统,为我国铁路的建设、运营和维护发挥着不可或缺的支撑作用。在铁路运输生产过程中,各环节之间高效协同离不开业务信息在各个管理层面和各个作业岗位之间安全、快速、准确地传递,既有信息系统间数据互通互融能够更大范围地发挥数据应用价值,使既有信息系统实现应用成效和收益倍增。因此,实现铁路既有业务应用系统的互联互通,在数据整合的基础上开发集成应用,是我国铁路信息化建设继续深入推进的必由之路,对提升铁路信息化水平、构建市场导向营销体系、提高铁路运营运输决策效率具有重要意义,也是推动智能铁路、数字铁路发展的着力点。
数据集成应用开发是近十来年国内各行业信息化的研究热点。在行业数据集成领域,郑倩倩基于kettle提出工业数据融合、转换、集成流程的方法,设计并开发数据集成实时调度系统,解决kettle无成熟调度、无运行监控的问题[3]。刘晓晨等人分析了科技管理信息系统和数据集成技术的发展现状,对科技管理数据各项指标和面临的挑战进行了探讨,基于大数据环境设计实现了科技管理数据共享平台[4]。黄勇光采用电力分区多源异构数据融合算法实现了电力分区多源异构数据的数据集成,提高了数据集成效率,促进电网稳定[5]。
本文面向中国铁路兰州局集团有限公司(简称:兰州局)数据集成应用开发需求,开发了铁路数据共享平台(简称:平台),为铁路企业应用开发单位提供便捷高效、安全、可靠的数据共享服务。该平台作为数据提供方(即产生业务数据源的既有信息系统)和数据提供方(即新开发的信息集成应用)之间数据共享的桥梁,使用Greenplum分布式数据仓库集中存储各类共享数据,数据使用方可直接从该平台获取所需的各类业务数据,无需分别与多个数据提供方单独进行点对点的信息交互。
1 设计目标
按照国铁集团《铁路数据管理暂行方法》提出的“规范数据标准和数据目录管理,规范数据采集、分级和汇聚,强化数据共享,推进数据应用”的要求,开发铁路数据共享平台,将海量复杂的各类业务数据进行采集、整合、集中存储管理,为铁路企业数据共享和集成应用提供有利的技术条件,提升铁路数据资产管理效能。
为充分发挥铁路企业既有数据资源的价值,按照数据治理规范,将既有数据资源集中纳入数据共享平台集中管理,使数据提供方与数据使用方无需进行点对点的反复沟通,减少数据采集、转换等重复工作,简化并规范数据共享的实现过程,提高数据共享效率。
1.1 创建公开透明的数据目录
按照“一数一源”原则[6],平台应创建公开、透明的铁路企业数据资产目录(简称:数据目录),将纳入平台集中管理的各类铁路业务数据进行分类和分级,支持按照业务分类、安全等级、文本、索引分类等查询数据,方便数据使用方查找满足使用需要的共享数据,并避免数据重复汇聚。
1.2 支持多种类型数据源
针对铁路数据源的多样性,平台应能支持数据库、文件、接口等多种类型数据源,可根据各类业务数据的具体特点,采取适用的采集、存储、更新策略,保障共享数据的完整性、准确性、时效性。
1.3 具备高可靠性、高性能与高扩展性
平台应采用适宜的架构设计,确保平台运行的高可靠性;鉴于铁路各类业务数据持续快速增长,平台应采用分布式处理、集群、负载均衡等实现技术,确保高性能和高扩展性;平台应提供完善的运行监控管理与数据安全防护手段,能够有效监测异常情况,为故障诊断和性能调优提供数据支持,保障数据共享服务的高可用性,保证数据提供方数据安全性、数据安全合规使用及数据使用方数据集成应用的稳定运行。
1.4 提供完善的信息安全保障机制
根据业务数据的重要程度与安全等级要求,采用身份认证、权限控制、数据加解密、数据脱敏等技术手段对数据的传输与存储进行数据安全防护,降低数据泄露、数据篡改、非法访问等风险,切实保障铁路数据与信息安全。
2 系统设计
2.1 系统架构
铁路数据共享平台基于Greenplum分布式数据仓库构建,实现铁路企业既有信息系统各类数据的统一采集、集中管理和按需访问,为铁路企业集成应用开发提供便利、高效的数据共享服务。平台由基础设施层、数据层、服务层、应用层、展示层组成,如图1所示。
(1)基础设施层:利用铁路企业数据中心云平台提供的服务器、存储、网络等资源,构建平台运行环境。
(2)数据层:负责存储和管理数据,包括平台配置与运行数据、共享的铁路业务数据,以及平台运行日志,并提供数据访问接口。平台配置与运行数据数据量较少,读写频率较高,采用高效、稳定的关系型数据库Oracle进行存储。铁路业务数据体量较大,且需要在大量并发访问时仍能够保证快速响应,采用高性能分布式数据仓库Greenplum进行存储。运行日志包括用户操作日志、平台运行过程日志和用户上传数据日志(主要是数据提供方和使用方按照数据共享平台管理规定提交的共享数据相关说明及各类申请文档);其中,用户操作日志和平台运行过程日志对实时性要求较高但事务性要求较低,采用单事务、读写性能好的文档数据库MongoDB来存储;用户上传数据日志包含不少非结构化数据文件,且需要长期存储,采用对象存储工具Minio来存储。
(3)服务层:为平台应用提供共性基础服务。采用分布式任务调度技术,实现自动触发和高并发执行数据采集任务;基于数据集成工具Pentaho Data Integration(PDI),实现可视化配置操作,帮助平台管理员快速完成数据采集相关配置;采用Filebeat日志管理工具,自动采集各类日志数据;采用RestfulAPI接口实现数据提供方、平台、数据使用方之间的数据交互;采用数据加解密、数据备份等安全策略,提升数据传输与存储的安全性;采用数据压缩技术减少数据量[7],提高数据传输效率。
(4)应用层:为平台用户提供数据目录管理、数据采集流程配置、任务调度管理、数据推送服务、日志管理、数据共享服务、运行管理与监控等功能,实现数据采集、管理、使用、监控、安全保护的全面管控。
(5)展示层:基于Vue.dataV、Vue.js、ElementUI和Vue.Draggable开发的PC客户端应用,为用户提供图形化查询和操作界面。
2.2 工作模式
平台可为铁路企业应用开发单位提供便捷高效、安全可靠的数据共享服务,充当数据提供方和数据提供方之间数据共享的桥梁。平台从数据提供方获取源数据后,对源数据进行转换和集成处理后存储在平台共享数据库中,供数据提供方按需使用。
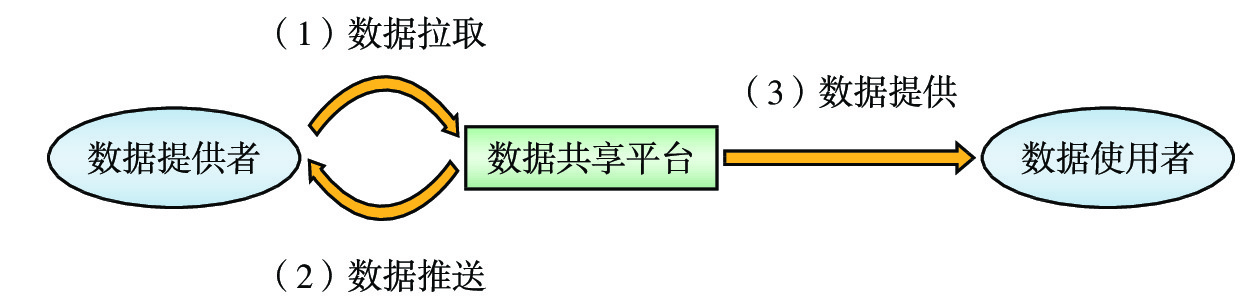
平台采用数据拉取和数据推送2种数据采集工作模式从数据提供方获取源数据,如图2所示。
(1)数据拉取:对于列车运行图、确报等不断平稳增长的业务数据,容易确定数据更新频率和采集时机,平台可依据预先设定的数据拉取任务配置信息,主动定时触发数据采集任务,从数据提供方数据源获取数据。
(2)数据推送:对于数据更新和增长时机不确定的数据源,若采用定时数据拉取工作模式,难以平衡数据采集的及时性与频繁触发数据采集任务对服务器资源的浪费。因此,可采用数据推送工作模式,当源数据发生变动时,由数据提供方主动向平台发送数据推送请求,平台接收请求后触发数据采集任务,从数据提供方数据源获取数据。
2.3 平台部署模型
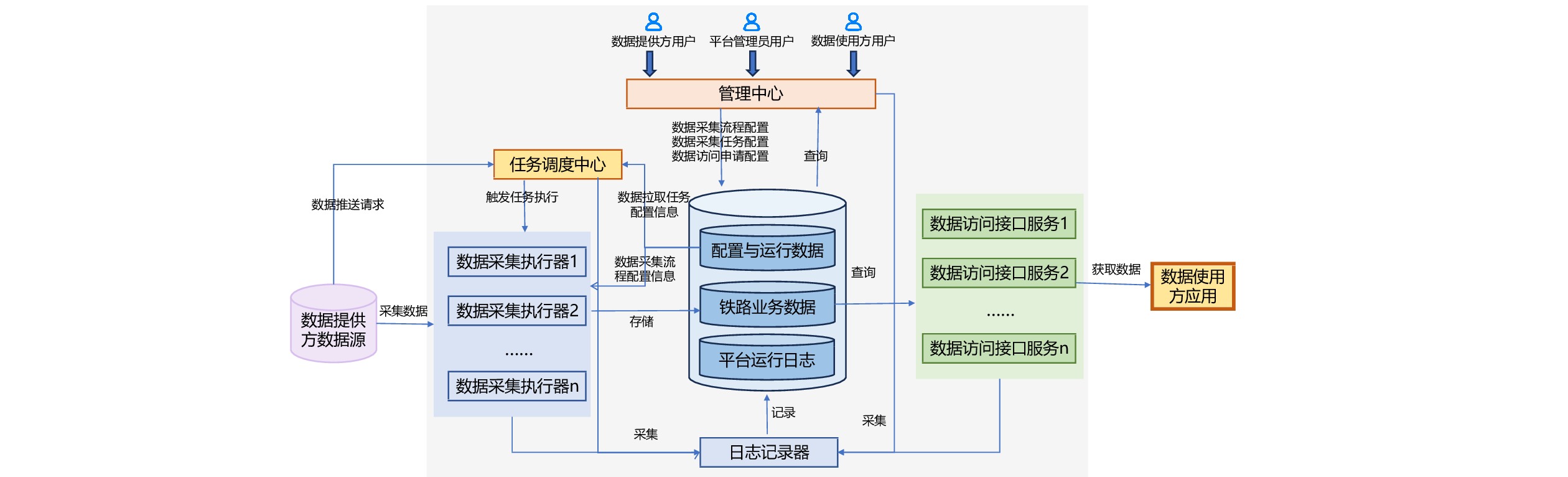
铁路数据共享平台应能保证多用户并发访问场景下高性能要求,需具有高可用性、高稳定性,以及适应发展需要的可伸缩性。因此,平台采用“3+2N”部署模型,由1个管理中心、1个任务调度中心、1个日志记录器、N个数据采集执行器和N个数据访问接口服务构成,部署模型如图3所示。
(1)管理中心:为平台管理员、数据提供方和数据使用方提供查询与操作的用户界面。为平台管理员提供数据采集任务与数据采集流程配置、数据访问控制、平台运行监控等功能;为数据提供方提供数据推送申请、元数据管理等功能;为数据使用方提供数据目录查询与检索、数据使用申请等功能。
(2)任务调度中心:负责数据采集任务的分布式调度。任务调度中心依据数据拉取任务配置数据中设置的执行时间,或是在接收到数据提供方数据源发出的数据推送请求时,选择采集任务负载较小的数据采集执行器,并触发数据采集任务执行。
(3)日志记录器:负责自动采集和存储平台各个组件在运行过程中生成的各种日志数据。利用Filebeat日志管理工具,分别从管理中心、任务调度中心、数据采集执行器集群和数据访问接口服务集群中采集日志数据,并集中存入平台运行日志数据库中,为平台运行监控、故障诊断及性能调优提供数据支持。
(4)数据采集执行器:负责数据采集任务的执行。当任务调度中心触发数据采集任务执行时,数据采集执行器按照数据采集流程配置信息,从数据提供方数据源获取数据后,对源数据进行处理转换后,将处理过的数据存入平台铁路业务数据库中的指定目标表,供数据使用方按需申请使用。数据采集执行器以集群方式部署,根据接入平台的数据提供方用户数,确定合适的集群大小。
(5)数据访问接口服务:响应来自数据使用方应用的数据访问请求,从平台铁路业务数据库中读取数据并提供给数据使用方;数据共享接口服务以集群方式部署,并根据访问平台数据共享服务的数据使用方应用的数量,确定合适的集群大小。
平台采用“3+2N”部署模型,可使管理中心、任务调度中心、数据采集执行器、日志记录器、数据共享服务5类主要组件分离部署、各自独立运行,当某一组件发生故障时,其它组件仍可正常运行,保障平台整体的可靠性、稳定性。
3 功能设计
平台用户包括平台管理员、数据提供方、数据使用方3类用户。面向平台管理员,提供数据目录管理、数据采集流程配置、采集任务设置、数据推送申请审核、数据推送接口描述、数据使用申请审核、数据访问接口配置等功能;面向数据提供方,主要提供元数据维护、目录浏览与检索、数据推送配置等功能;面向数据使用方,主要提供数据目录浏览与检索、数据使用申请、数据访问接口查看等功能。
3.1 数据目录管理
平台管理员对纳入平台管理的共享数据资源进行分类和分级,在数据分类分级框架下创建可共享的铁路业务数据清单,数据提供方为自己所提供的源数据填写元数据,形成铁路数据资产目录,便于数据使用方快速准确的查找符合自身应用开发需求的既有数据资源,平台为不同级别数据提供差异化安全防护策略。
3.1.1 分类分级定义
平台管理员录入数据分类与分级定义信息,据此对纳入平台管理的源数据进行归类,以建立层级结构的数据目录列表,并为各源数据确定分级。
(1)数据分类定义:根据“十四五”铁路网络安全和信息化规划,将铁路企业数据业务领域定义为战略决策、运输生产、经营开发、资产管理、建设管理、综合协同6大业务领域,并按线分类法[8]进行数据分类,以形成层次结构的铁路业务数据列表。
(2)数据分级定义:按照数据遭到篡改、破坏、泄露等所造成的危害程度,综合评估数据的重要性,划分为一般数据、敏感数据、核心数据3个等级,据此对铁路数据资产进行分级管理,作为数据共享与集成应用开发中实施规范化数据安全保护策略的依据。
3.1.2 源数据管理
平台管理员按照铁路企业共享数据资源管理规范,对各数据源相关信息进行维护,数据提供方基于此完成元数据管理,确保铁路业务数据统一规范管理,使共享数据资源更容易理解、查找、管理和使用。
(1)数据源信息录入:平台管理员按照通过业务主管部门审核的信息系统数据源名单,录入信息系统名称、研发单位、业务主管部门、简介、数据源类型(信息系统数据、信息基础设施平台数据、或通信系统和控制系统数据)、数据源所在网域(铁路综合信息网、外部服务网、专网或互联网)及其等保情况等信息,以及该系统包含的源数据种类名称。
(2)数据分块索引维护:对于需要根据业务职责实行访问权限控制的业务数据,平台管理员设置用于实现访问权限控制的数据分块索引配置数据,包括索引编号、索引字段名、索引值范围、数据块名称,平台会自动为每个索引对应的数据块生成唯一代码DataID,通过在数据访问接口中指定索引,即可控制数据使用方只能获取该索引对应的数据块。
(3)元数据维护:数据提供方录入源数据的相关说明,包括源数据表名称、源数据表中各个数据字段的名称、数据类型、数据取值范围、数值单位、数据含义等。
3.1.3 目录浏览与检索
平台以层次化列表形式,对数量庞大、种类繁多的铁路企业数据资产进行有序组织,形成铁路企业数据资产目录,使铁路业务数据资产更易于被发现和使用,提高数据治理的有效性和效率。
(1)数据目录浏览:平台按预定义的数据分类、数据来源信息系统、数据种类和元数据信息,将纳入平台管理的所有数据源进行层级化展示,通过展开和折叠数据目录,查看平台中可用的共享数据资源及其元数据信息。
(2)数据资产检索:根据数据名称、数据分类、数据分级、数据来源信息系统和业务主管部门等查询条件,查询所需数据资源。
3.2 数据采集
对于纳入平台管理的共享数据源,平台提供拉取和推送两种数据采集方式;按照预定义的数据采集任务配置信息和数据采集流程配置信息,任务调度中心调度数据采集执行器,自动采集各业务应用系统产生(即数据提供方提供)的数据,并集中存储在平台的铁路业务数据库中,供数据使用方按需申请使用。
3.2.1 数据采集流程配置
平台管理员完成数据采集流程配置,平台可据此自动完成数据采集任务。数据采集流程规定了从哪个数据源采集数据、对源数据进行何种处理、以及平台铁路业务数据库中用于存储所采集数据的目标表[9]。
(1)数据源参数设置:平台管理员设置访问数据源的相关参数,平台支持的数据源有数据库、API接口、文件等多种类型。数据库类型的数据源参数包括数据库连接参数、接口访问地址及参数等。文件类型的数据源可是文本文件、Excel格式文件等;对于文本文件的数据源,需设置数据分割符;对于Excel格式文本的数据源,需设置文件内容解析规则,包括是否读取首行标题、是否跳过空行、Excel文件编码格式等。
(2)数据处理规则定义:平台管理员录入数据处理的相关规则,用于数据采集任务对源数据进行处理,使共享数据满足使用方的需要。处理规则主要包括字段类型转换、字段重命名、数据集过滤、缺失值填充、冗余数据剔除等。
(3)目标表参数设置:平台管理员设置存储共享数据目标表的相关参数,主要包括数据仓库模式名、表名、字段名、字段类型等信息,数据采集任务自动将处理好的数据存储到平台数据仓库中的目标表,供数据使用方访问。
3.2.2 数据拉取配置
平台管理员设置数据拉取任务相关参数,任务调度中心可据此主动触发数据采集任务的执行,以按照预定义的数据采集流程自动完成数据采集任务。
(1)数据采集流程选择:平台管理员浏览和查询预定义的数据采集流程清单,从中选择需要以拉取模式执行的数据采集流程。
(2)数据拉取任务参数设置:平台管理员为主动拉取数据的数据采集流程设置相关任务参数,包括启动时间、执行频率和响应参数等[10],由任务调度中心据此自动触发数据采集任务的执行。
3.2.3 数据推送申请、审核及执行
对于数据变化较为频繁的源数据,为及时采集变化的数据,平台为数据提供方提供数据推送服务。当源数据发生变动时,数据提供方使用审核通过的数据推送接口,向任务调度中心发起数据推送请求,由任务调度中心调度数据采集执行器完成数据采集任务。
(1)数据推送申请:数据提供方浏览和查询预定义的数据采集流程清单,从中选择需要以推送模式执行的数据采集流程,并填写主动推送数据的申请,包括数据内容、数据量、推送数据的IP地址清单和确定数据增量的字段等内容,提交给平台管理员。
(2)数据推送审核:平台管理员查看数据提供方提交的数据推送申请,按照铁路企业数据治理管理规范进行审核,批准符合规范的数据推送申请,对不符合规范的数据推送申请返回修改意见。数据提供方用户可查看数据推送申请的审核状态,对未通过审核的数据推送申请进行修改完善后再次提交,或取消未通过审核的数据推送申请。
(3)推送申请接口服务描述:数据推送申请通过审核后,平台自动为其生成一个特定、加密的推送申请接口服务,其中包含由数据提供方选定的数据采集流程的惟一标识号;由平台管理员填写该接口服务的使用说明,包括请求方法(包括POST、GET、PUT等)、参数类型(Param和Boby)、响应状态码等信息,数据提供方用户可以查看接数据推送申请接口服务的使用说明。
任务调度中心根据数据拉取任务配置数据,或数据提供方数据源发出的数据推送请求,调度数据采集执行器,由数据采集执行器按照数据采集流程配置信息执行数据采集任务。
(1)数据采集任务调度:任务调度中心从平台配置与运行数据库中读取数据拉取任务配置数据,按照其中设置的执行时间,或是在接收到数据提供方数据源发出的数据推送请求时,选择采集任务负载较小的数据采集执行器,并触发数据采集任务执行。
(2)采集任务执行:数据采集执行器读取数据采集流程配置信息,从指定的数据源读取源数据,按照指定的处理规则对源数据进行处理,并将处理后的数据存入到铁路业务数据库中指定的目标表。
3.3 数据共享
平台提供周全的数据使用服务,方便数据使用方全面细致了解平台中可用的共享数据资源,根据自身需要提交数据使用申请,数据使用申请通过审核后,数据使用方应用可通过数据访问接口服务,直接从平台获取所需的数据。
3.3.1 共享数据预览
数据使用方用户浏览平台数据目录中可共享数据资源,查看各数据名称、数据简介、提供数据源的业务应用系统、以及元数据等信息,并预览示例数据,以确定数据资源是否满足自身应用需求。
(1)数据基本信息查看:显示数据名称、数据 种类、数据含义、数据来源的业务应用系统、数据分块索引等基本信息, 方便数据使用方找到所需数据。
(2)示例数据预览:数据使用方可预览任一数据表中的5行数据记录,帮助数据使用方判断数据表中的数据是否满足使用需求。
3.3.2 数据使用申请与审核
数据使用方找到所需数据后,提交数据使用申请,通过平台管理员审核后,数据使用方应用即可访问共享数据。
(1)数据使用申请:数据使用方填写数据使用申请,包括申请单位、申请人、联系方式、数据名称、数据分块索引、使 用目的、预估日均访问次数、允许发起数据访问请 求的合法 IP 地址清单等信息;数据使用申请提交后, 可查看申请的审核状态。
(2)使用申请审核:平台管理员查看并审核数据使用申请,数据使用方用户可对未通过审核的申请进行修改完善后重新提交,也可直接取消该申请。
3.3.3 数据使用
数据使用方通过平台管理员配置的数据访问接口服务获取所需数据。
(1)数据访问接口配置:数据使用申请通过审核后,平台管理员设置数据使用方数据访问请求的参数格式示例、请求头参数值、请求方法(包括POST、GET、PUT等)、返回结果示例等,平台自动为其生成加密的数据访问接口服务。
(2)数据访问接口查看:数据使用方用户可查看平台管理员配置的数据访问接口及使用说明。
(3)数据获取:数据使用方应用通过调用数据访问接口服务,获取允许访问范围内的所需数据。
3.4 运行监控管理及数据安全防护
为平台运行过程、服务调用过程、数据传输与存储提供完善的运行监控工具,对数据采取必要的安全防护措施,确保平台易于维护、运行稳定可靠、数据安全有保障。
3.4.1 日志查询
平台管理员可通过管理中心的日志查询界面了解平台总体运行情况,包含请求执行时间、执行结果和数据更新行数等内容,并可按时间、内容、结果等多种条件进行组合查询,快速诊断和定位平台运行过程中出现的异常,及时采取措施排除故障。
3.4.2 运行监控
为平台管理员提供可视化服务监控界面,实时查看服务调用情况、监控服务健康状态,以及时发现异常情况并采取措施处理,确保平台服务保持正常状态。
(1)服务调用情况:平台管理员可以查看平台服务请求量、服务响应响应时间、成功率等服务调用指标数据,及时发现流量异常、请求超时、服务崩溃等异常情况,采取针对性的容错处理或性能调优,提高服务的可靠性和执行效率。
(2)服务器健康状况:平台管理员可以监控支持平台运行的各服务器的CPU利用率、内存使用量、I/O读写量、网络连接等健康状况,及时发现服务器资源不足、服务器故障、网络故障等异常情况并采取相应措施,保障服务高可用性。
3.4.3 数据安全防护
平台在数据采集、传输、存储、使用的过程采取较为完善的数据安全防护措施,保证数据提供方的数据不被篡改、破坏、泄露、非法获取等,保证提供给数据使用方的数据完整、正确、可用。
(1)数据源信息加密:为避免对数据提供方数据库的侵入,采用数据加密算法对数据库连接参数等数据源信息进行加密存储。
(2)敏感数据保护:针对手机号、用户密码、身份证号等敏感的个人数据以及铁路企业核心业务数据、调度命令等敏感的业务数据,采用数据加密、数据脱敏、数据防泄漏等技术[11],实现数据传输和存储的安全。
(3)服务调用安全防护:在用户调用数据推送接口服务和数据访问接口服务时,采用身份认证、访问控制、权限控制等手段,对服务调用过程进行安全保护,降低数据泄露、非法访问等风险,提高平台服务调用的安全性。
4 关键技术
4.1 基于PDI的可视化数据采集配置
平台管理员需要完成与数据采集相关的配置任务,主要包括数据采集流程配置、数据拉取配置和数据推送申请接口服务描述。数据采集流程配置是为了从异构数据源获取数据,并对源数据进行必要的处理,使其与使用方的数据使用目的完全对接,确保共享数据满足数据使用方的要求。数据拉取配置是平台管理员为拉取模式的数据采集任务设置相关参数,主要用于确定调度数据采集任务的时机。数据推送接口服务描述是平台管理员填写数据推送申请接口服务的使用说明,主要用于指导数据提供方提交数据推送申请。
一个数据采集流程的配置大致划分为3个主要步骤:数据源参数设置、数据处理规则定义、目标表参数设置,每个步骤都需要单独进行多个参数项或多条规则的设置,而且对于不同类型的数据源、数据处理规则和目标表,需要设置的具体配置信息各不相同。例如,若数据源为数据库表时,需要设置数据库类型、数据库连接参数、源数据表名等信息;若数据处理需要将源数据中某字段处理为时间类型,需要设置字段名、时间类型、时间格式等信息;若数据处理中需要更改字段名时,需要设置新字段名、字段类型、默认值等信息;若存储目标表为excel文件时,需要设置文件地址、文件名和写入表头名等信息。由于数据采集流程配置过程具有一定的复杂度,若以表单方式录入配置信息,不但操作繁琐,且容易录入错误数据。
数据集成工具(PDI,Pentaho Data Integration)基于元数据驱动方法,可提供可视化图形操作界面,支持处理大量异构数据源和多样化数据处理逻辑。
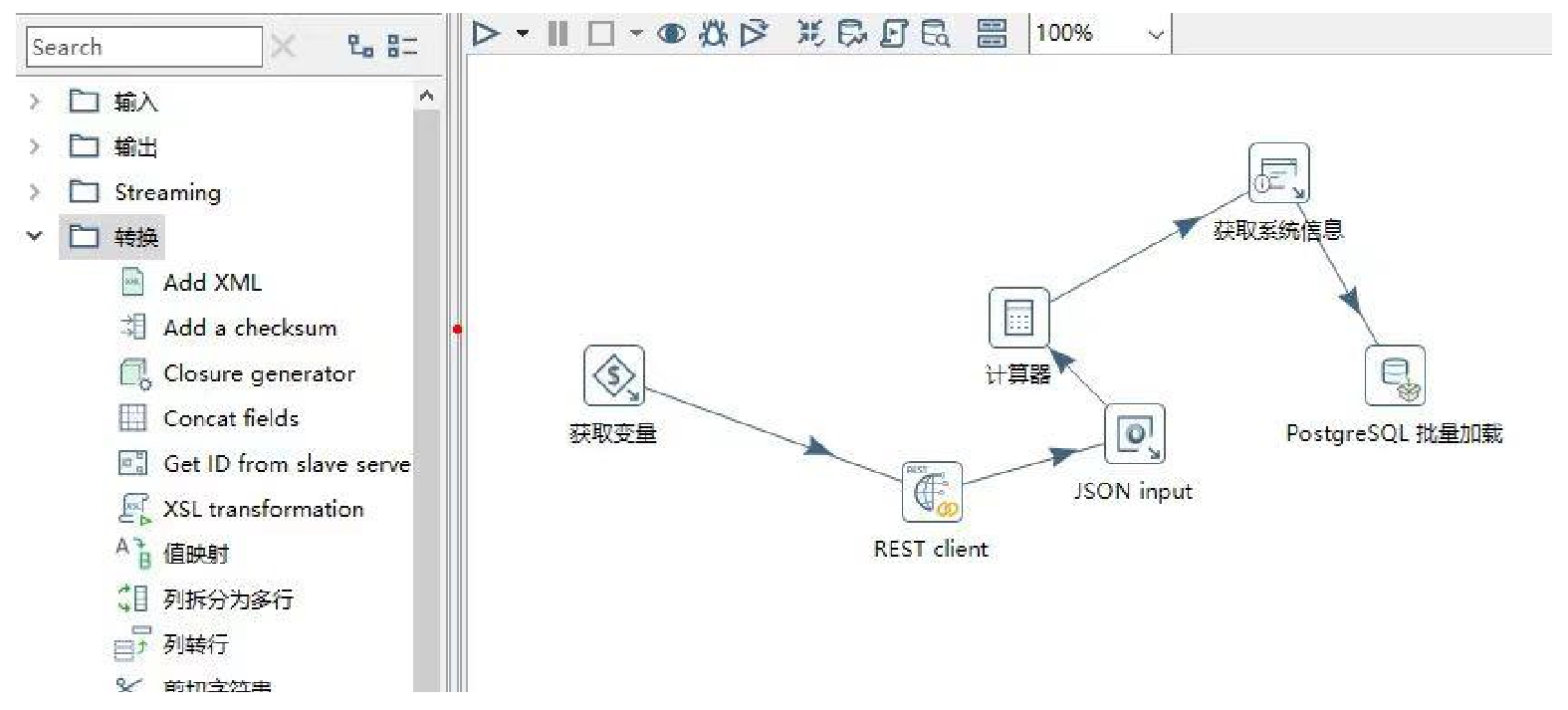
基于PDI数据集成工具开发了可视化数据采集配置界面,允许平台管理员以拖拽式完成数据采集流程的配置,使数据采集流程的配置过程更加直观,易于理解且轻松快捷。可视化数据采集配置主界面如图4所示,由组件库、设计区、工具栏组成。
(1)组件库:提供一系列完成数据输入、数据转换和数据输出等数据处理逻辑的可视化组件,用于编排设计数据采集流程。目前,组件库包含超过200种数据处理逻辑组件,以列表形式展示在左侧组件列表框中,平台管理员可通过展开与折叠列表框,查看可用的处理逻辑组件。
(2)设计区:当平台管理员新建一条数据采集流程时,设计区初始为空白画布。采用Vue.Draggable技术,平台管理员可从组件库内选取预定义组件拖拽到设计区内,作为数据采集流程的各个节点,并用箭头将各个节点连接起来,通过对组件的拖拽与排序完成数据采集流程的编排;双击任一组件节点,可弹出设置具体参数或配置详细规则的表单,平台管理员填写完表单后,即可完成相应的设置操作。
(3)工具栏:为平台管理员设置数据拉取配置信息和录入数据推送申请接口服务描述信息提供了一组操作按钮,点击按钮后可弹出对应的表单完成操作。
数据采集流程可视化配置使数据采集流程的配置过程变得便捷、灵活,有效提高平台管理员工作效率,也让平台可配置的数据采集流程具有良好的可扩展性,便于增加更多新的数据处理逻辑。
4.2 基于xxl-job的数据采集任务分布式执行调度
考虑到平台未来需要承担大量的数据采集任务,若采用单机部署所有的数据采集执行器,容易出现接口响应超时、单机故障和并发量过高等问题,数据采集任务执行的稳定性较低、运维成本较高。因此,以集群方式部署数据采集执行器,通过数据采集任务的资源调度、负载均衡等手段,提高平台数据采集性能与执行效率。
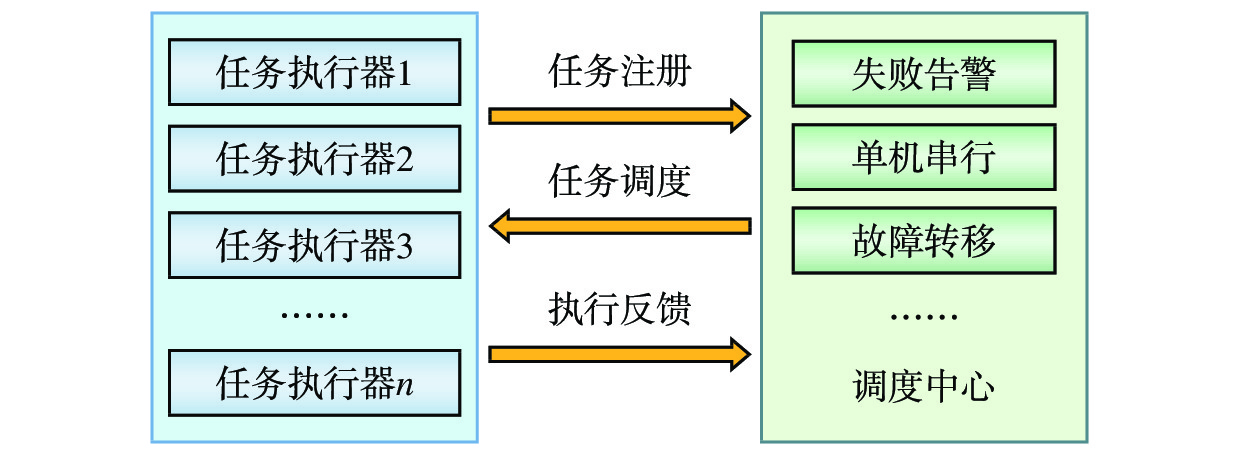
xxl-job是一种开源的分布式任务调度框架[12],提供了任务调度可视化操作界面,便于用户启动、执行、中止任务,且提供任务状态监控及日志查看功能。基于xxl-job的分布式数据采集任务调度框架由任务调度中心和若干个任务执行器组成,二者通过RestfulAPI进行通信,任务执行器可根据业务量部署多个,分布式数据采集任务调度框架如图5所示。
(1)执行器注册:当一个数据采集执行器启动时,将该执行器的地址、名称和注册时间等信息告知任务调度中心,并通过不断定时向调度中心报告自身状态。
(2)任务调度:任务调度中心读取数据拉取配置数据,按照其中设置的执行时间,或是在接收到数据提供方数据源发出的数据推送请求时,选择采集任务负载较小的数据采集执行器,向其发送数据采集请求,数据采集请求包括任务名称、调度时间、任务内容和调度执行器名称等信息。
(3)任务执行:数据采集执行器接收到数据采集请求之后,读取数据采集流程配置信息,并启动一个线程执行数据采集任务。
(4)执行反馈:当一次数据采集请求执行完毕后,数据采集执行器将数据采集请求的执行情况(包括执行时间、执行日志和执行结果)回传给任务调度中心,由任务调度中心记录数据采集任务执行结果。
(5)故障处置:当数据采集执行器状态异常或任务执行异常时,任务调度中心根据平台管理员设置的阻塞处理策略(包括单机串行、丢弃后续调度和覆盖之前调度)、任务超时时间、失败重试次数等任务调度参数进行故障处置,保证数据采集任务的可靠性与稳定性。
4.3 基于索引的数据分块访问控制
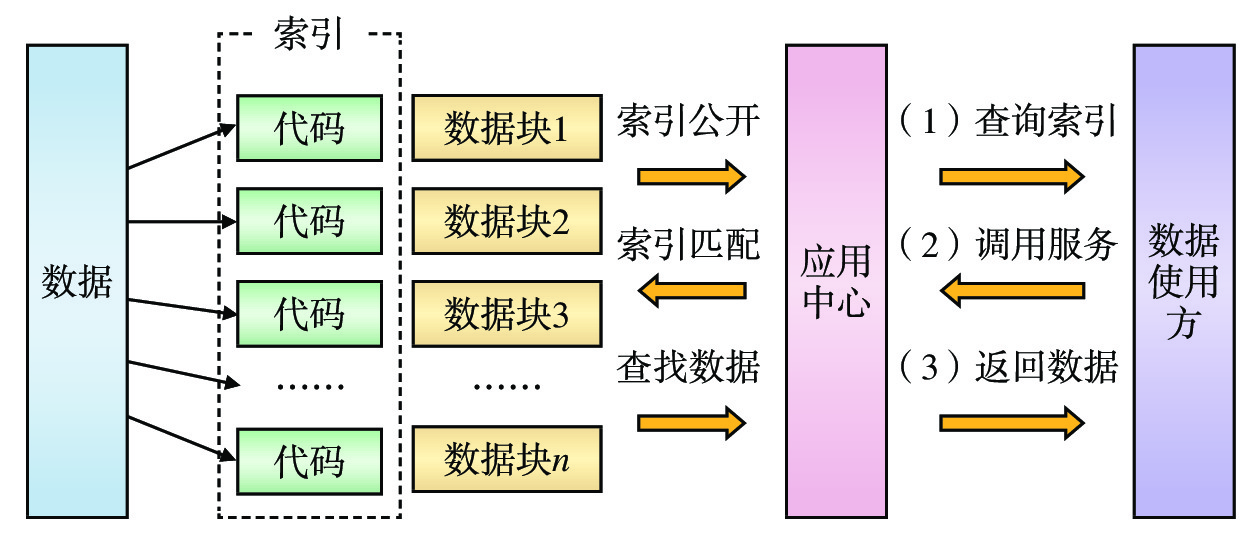
在数据共享时,由于部分业务数据较为敏感,需保证最终用户不能访问超出自身职责允许范围的业务数据,例如车站A的业务人员不允许查看车站B的货运装车数据。针对此类数据使用场景,提出一种基于索引的数据分块访问控制技术。数据使用方在调用某个数据访问接口服务时,可通过指定索引来获取对应的数据块,由平台提供数据访问控制,无需对数据进行二次过滤。基于索引的数据访问控制的实现流程如图6所示。
(1)数据分块:按照岗位、车站、单位或专业等具体情况,将数据集划分为若干个独立的数据块,并为每个数据块创建一个唯一索引,数据使用方在调用数据共享接口服务时可通过指定索引来访问特定的数据块。例如,货运装车数据可根据车站划分,将兰州北车站的货运装车定义为一个数据块,对应的唯一索引为“A1”。
(2)索引生成:平台为每个数据块分配一个随机字符串代码作为索引,并为数据使用方提供索引与数据块范围定义的查询。
(3)服务调用:数据使用方根据最终用户的职责范围,通过平台提供的数据块范围定义查找对应的索引,并在调用数据共享接口服务时,将索引作为服务请求的一个参数。
(4)数据返回:数据共享接口服务在接收到数据使用方的服务请求后,从请求体中解析出索引参数,并对索引参数进行正确性和非空性校验后,从数据仓库中取得相应的数据块返回给数据使用方。
基于索引的数据访问控制能实现基于数据使用方业务职责范围的数据访问控制,减少不必要的数据访问量,降低敏感数据泄露的风险,提高数据共享的安全性。
5 结束语
本文针对铁路企业既有数据资产来源广、数据源类型多种多样等特点,基于分布式数据仓库Greenplum,开发了适用于集中存储和管理铁路企业多源异构数据的数据共享平台。平台提供数据目录管理、数据采集、数据共享、运行监控管理及数据安全防护等功能,实现对铁路多源异构数据的自动采集、处理及集中存储,实现铁路企业数据资产的规范化集中管理,使各业务应用系统间能够简单、便捷地共享数据。平台采用高可靠、易扩展的架构设计及可视化技术,为平台管理员提供简便易用的可视化配置管理与运行监控工具,为铁路企业应用开发单位提供便捷高效、稳定可靠、安全合规的数据共享服务,较好地满足铁路企业数据集成应用开发的需要,也为铁路企业大数据应用构建起坚实的基座。
数据共享平台已在兰州局启动试运行。对兰州局既有255个信息系统进行了全面摸底调查和规范化梳理,在该平台上完成数据资产目录的建立。平台目前已采集76种业务数据,数据总量84 GB,主要包括实时运行图、预确报、在站车、运货五等数据。平台已为车务段安全生产指挥中心管理系统(亦称车务生产指挥中心信息平台)、调车作业安全防护及智能监控系统、货运大数据营销平台等16个信息系统提供稳定、高效的数据共享服务,目前日均数据访问量达2800余次。
后续将根据平台试运行中出现的问题和新需求,加快完善平台功能。随着纳入该平台管理的铁路业务数据的体量不断增长、应用范围不断扩大,需要集中处理和存储的数据种类也将愈加丰富,需要不断结合具体业务场景,对多源异构数据的汇聚与集成继续开展深入研究,建立完善的数据采集、处理、集成、共享机制,更大程度地发挥铁路企业数据资产价值,为促进铁路业务融合创新和大数据应用开发提供有利条件,助力铁路运输生产信息化赋能和业务数字化创新不断升级。
-
[1] 朱 涛,张伯驹,靳 磊. 下一代铁路信息系统发展方向思考[J]. 铁路计算机应用,2023,32(1):9-14. [2] 国家铁路局. “十四五”铁路网络安全和信息化规划[EB/OL]. [2022-05-12]. http://www.rail-transit.com/xinwen/show.php?itemid=21603. [3] 郑倩倩. 基于Kettle的工业数据集成与应用[D]. 重庆:西南大学,2023. [4] 刘晓晨,王卓昊. 基于大数据环境的科技管理数据集成平台研究[J]. 情报学报,2021,40(9):953-961. [5] 顾巍. 基于FPGA的LZ4无损压缩算法优化设计[D]. 南京:东南大学,2018. [6] 黄勇光,黄 兵. 基于大数据技术的电力分区多源异构数据集成系统设计[J]. 电子设计工程,2023,31(2):34-37,42. [7] 国务院办公厅. 国务院办公厅关于印发全国一体化政务大数据体系建设指南的通知[EB/OL]. (2022-10-28). https://www.gov.cn/zhengce/content/2022-10/28/content_5722322.htm. [8] 吴宁忠. 线分类法在社会保险业务分类与代码中的应用探讨[J]. 标准科学,2017(2):36-39. [9] 宋 杰. 面向多类型数据源的数据仓库构建及ETL关键技术的研究[D]. 沈阳:东北大学,2011. [10] 郭 迪,赵政文,王 玺. 基于cron的计划任务时间管理的设计与实现[J]. 现代电子技术,2011,34(14):62-64,74. [11] 张红勇,左 睿,王佳星. 铁路数据安全管理策略研究[J]. 信息技术与信息化,2022(11):185-189. [12] 张 鹏,白朝旭,王 锟,等. 基于Quartz的集团化调度任务分布部署研究[J]. 现代电子技术,2014,37(2):80-83. -
期刊类型引用(1)
1. 谢文达. 基于区块链技术的高校产教融合平台信息数据共享方法. 无线互联科技. 2024(24): 76-79 .  百度学术
百度学术
其他类型引用(0)
 下载:
下载:

计量
- 文章访问数: 51
- HTML全文浏览量: 19
- PDF下载量: 16
- 被引次数: 1
